example/files – ein konkretes nützliches domänenspezifisches Beispiel für bin/post und /browse
Die Serie
Dies ist der dritte Teil einer dreiteiligen Serie, in der wir Ihnen zeigen, wie Sie mit ein paar einfachen Befehlen eine echte Anwendung erstellen können. Die drei Teile dieser Serie sind:
- Daten mit bin/post in Solr übertragen
- Visualisierung von Suchergebnissen: /browse und mehr
- ==> (Sie befinden sich hier) Realistische Zusammenstellung: example/files – ein konkretes nützliches domänenspezifisches Beispiel für bin/post und /browse
Im vorigen /browse-Artikel haben wir Ihnen gezeigt, wie Sie Ihre Suchergebnisse mit dem VelocityResponseWriter aus einer ästhetischeren Perspektive visualisieren können. Lassen Sie uns einen Schritt weiter gehen.
example/files – Ihre eigene persönliche Solr-gestützte Dateisuchmaschine
Das neue example/files bietet eine Solr-gestützte Suchmaschine, die speziell auf Rich-Document-Dateien abgestimmt ist. Innerhalb von Sekunden können Sie Solr herunterladen und starten, eine Sammlung erstellen, Ihre Dokumente darin ablegen und die einfache Abfrage Ihrer Sammlung genießen. Das /browse-Erlebnis der example/files-Konfiguration wurde für die Indizierung und Navigation in einer Reihe von „einfachen Dateien“ wie Word-Dokumenten, PDF-Dateien, HTML und vielen anderen Formaten zugeschnitten.
Neben der standardmäßigen datengesteuerten und generischen /browse-Schnittstelle bietet example/files folgende Funktionen:
- Distillierte, einfache, dokumentenartige Navigation
- Mehrsprachige, lokalisierbare Oberfläche
- Spracherkennung und Facettierung
- Phrasen-/Einzelindexierung und „Tag Cloud“-Facettierung
- Extraktion von E-Mail-Adressen und URLs zur Indexzeit
- „Sofortige Suche“ (während Sie die Ergebnisse eingeben)
Erste Schritte mit Beispielen/Dateien
Starten Sie Solr und erstellen Sie eine Sammlung namens „Dateien“:
bin/solr start bin/solr create -c files -d example/files
Wenn Sie bei der Erstellung einer Solr-Sammlung das Flag -d verwenden, geben Sie die Konfiguration an, aus der die Sammlung erstellt wird, einschließlich der Indizierungskonfiguration und der Skript- und Benutzeroberflächenvorlagen.
Dann indizieren Sie ein Verzeichnis voller Dateien:
bin/post -c files ~/Documents
Je nachdem, wie groß Ihr „Dokumente“-Ordner ist, kann dies einige Zeit dauern. Lehnen Sie sich zurück und warten Sie auf eine Meldung wie die folgende:
23731 files indexed. COMMITting Solr index changes to http://localhost:8983/solr/files/update… Time spent: 0:11:32.323
Und öffnen Sie dann /browse in der Dateisammlung:
open http://localhost:8983/solr/files/browse
Die UI ist die App
Mit example/files wollten wir die Schnittstelle speziell auf die Dateisuche ausrichten. Deshalb haben wir die Möglichkeit implementiert, nach bestimmten Dateitypen wie Präsentationen, Tabellenkalkulationen und PDF-Dateien zu suchen und zu filtern. Mit einem UI/UX-First-Ansatz wollten wir auch eine „Sofortsuche“ und eine lokalisierbare Oberfläche. 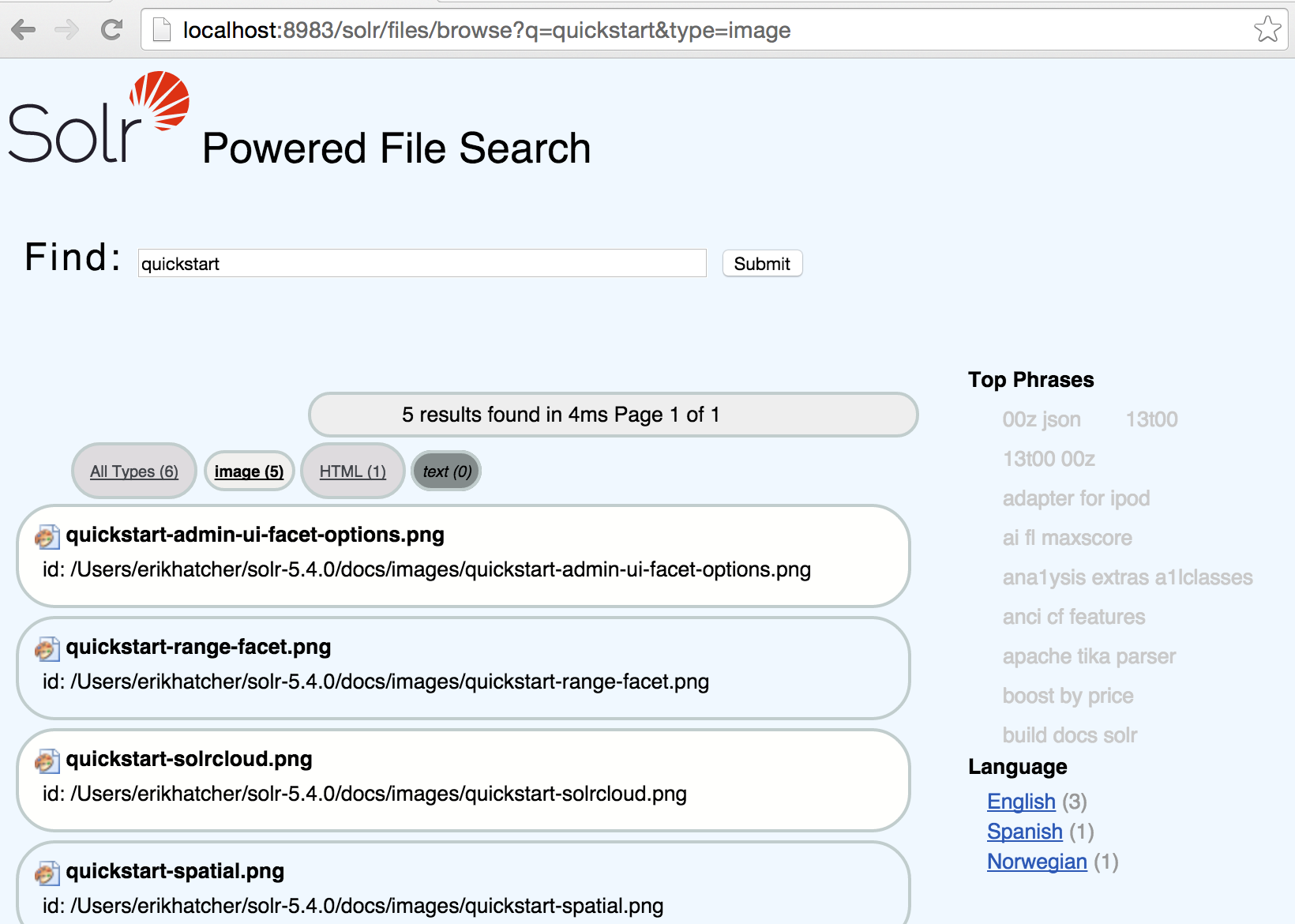
Der Rest dieses Artikels erklärt von außen nach innen das Design und die Implementierung, von der Benutzeroberfläche und der URL-Ästhetik bis hin zu den leistungsstarken Solr-Funktionen, die dies möglich machen.
URLs sind auch UI!
„…wenn man darüber nachdenkt, wie man sie gestaltet“. Coole URIs
Neben der HTML/JavaScript/CSS-„App“ der Beispiele/Dateien wurde auch auf die Ästhetik und Sauberkeit der anderen Benutzeroberfläche, der URL, geachtet. Die URLs beginnen mit /browse und beschreiben damit die Hauptaktivität des Benutzers in dieser Schnittstelle – das Durchsuchen einer Sammlung von Dokumenten.
Durchsuchen nach Dokumenttyp
Die Ergebnisse können über die Links am oberen Rand nach Dokumenttyp gefiltert werden.

Wenn Sie auf die einzelnen Typen klicken, können Sie sehen, wie sich der Parameter „Typ“ in der URL-Anfrage ändert.
Für die Ästhetik der URL haben wir beschlossen, dass die Filterung nach Dokumenttyp so aussehen sollte: /browse?type=pdf (oder type=html, type=spreadsheet, usw.). Die Schnittstelle unterstützt auch zwei spezielle Typen: „all“, um alle Typen auszuwählen, und „unknown“, um Dokumente ohne Dokumententyp auszuwählen.
Zur Indexzeit wird der Typ eines Dokuments identifiziert. Eine Aktualisierungsprozessorkette (files-update-processor) ist  definiert, um ein Skript für jedes Dokument auszuführen. Eine Reihe von regulären Ausdrücken bestimmt den Typ des Dokuments auf der Grundlage des Feldes „content_type“ (MIME-Typ), das für jedes indizierte Rich Document festgelegt wurde. Die aktuellen Typen sind doc, html, image, spreadsheet, pdf und text. Wenn ein übergeordneter Typ erkannt wird, wird ein doc_type Feld auf diesen Wert gesetzt.
definiert, um ein Skript für jedes Dokument auszuführen. Eine Reihe von regulären Ausdrücken bestimmt den Typ des Dokuments auf der Grundlage des Feldes „content_type“ (MIME-Typ), das für jedes indizierte Rich Document festgelegt wurde. Die aktuellen Typen sind doc, html, image, spreadsheet, pdf und text. Wenn ein übergeordneter Typ erkannt wird, wird ein doc_type Feld auf diesen Wert gesetzt.
Es wird kein doc_type-Feld hinzugefügt, wenn der content_type keine geeignete Zuordnung auf höherer Ebene hat, ein wichtiger Aspekt für die Besonderheiten der Filtertechnik. Die /browse-Handler-Definition wurde um die folgenden Parameter erweitert, um die Facettierung von doc_type und die Filterung mit unserem eigenen „type=…“ zu ermöglichen URL-Parameter zum Filtern nach einem der Typen, einschließlich „all“ oder „unknown“:
- facet.field={!ex=type}doc_type
- facet.query={!ex=type key=all_types}*:*
- fq={!switch v=$type tag=type case=’*:*‘ case.all=’*:*‘ case.unknown=‘-doc_type:[* TO *]‘ default=$type_fq}
Es gibt einige Details darüber, wie diese Parameter festgelegt werden, die hier erwähnt werden sollten. Zwei Parameter, facet.field und facet.query, werden in params.json unter Verwendung der „paramset“-Funktion von Solr festgelegt. Und der fq-Parameter wird in der /browse-Definition in solrconfig.xml angehängt (denn paramsets erlauben derzeit kein Anhängen, sondern nur das Setzen von Parametern).
Die Facettenparameter schließen den Filter „Typ“ aus (der in der angehängten fq definiert ist), so dass die Anzahl der angezeigten Typen nicht von der Typfilterung beeinflusst wird (die Einschränkung auf „Bild“-Typen zeigt immer noch die Anzahl der „pdf“-Typen und nicht 0). Es gibt eine spezielle Facettenabfrage „all_types“, die die Zählung für alle Dokumente innerhalb der Abfrage und der durch die Filterung eingeschränkten Menge liefert. Und dann gibt es noch den kniffligen fq-Parameter, der den Abfrageparser „switch“ nutzt, der steuert, wie die Typfilterung anhand des benutzerdefinierten Parameters „type“ funktioniert. Wenn kein Typ-Parameter angegeben wird oder type=all, wird der Typ-Filter auf „all docs“ (über *:*) gesetzt, so dass effektiv nicht nach Typ gefiltert wird. Bei type=unbekannt wird das spezielle -doc_type:[* TO *] (beachten Sie das Bindestrich/Minuszeichen zum Negieren) verwendet, das alle Dokumente abgleicht, die kein doc_type-Feld haben. Und schließlich, wenn ein anderer „type“-Parameter als all oder unknown angegeben wird, wird der verwendete Filter durch den Parameter „type_fq“ definiert, der in params.json als type_fq={!field f=doc_type v=$type} definiert ist. Dieser Parameter type_fq gibt eine Feldwertabfrage an (im Grunde dasselbe wie fq=doc_type:pdf, wenn type=pdf), wobei der Feldabfrageparser verwendet wird (der in diesem Fall eine einfache Lucene TermQuery ist).
Das ist eine Menge Solr-Mojo, nur um in der URL type=image sagen zu können, aber es geht ja um die URL/Benutzererfahrung, also war es die Mühe wert, die Komplexität zu implementieren und zu verbergen.
Lokalisierung der Schnittstelle
 Die Oberfläche von example/files wurde in mehrere Sprachen übersetzt. Beachten Sie das blaue globale Symbol in der oberen rechten Ecke der /browse-Benutzeroberfläche. Bewegen Sie den Mauszeiger über das Globussymbol und wählen Sie eine Sprache aus, in der Sie Ihre Sammlung anzeigen möchten.
Die Oberfläche von example/files wurde in mehrere Sprachen übersetzt. Beachten Sie das blaue globale Symbol in der oberen rechten Ecke der /browse-Benutzeroberfläche. Bewegen Sie den Mauszeiger über das Globussymbol und wählen Sie eine Sprache aus, in der Sie Ihre Sammlung anzeigen möchten.
Jede angezeigte Textzeichenfolge ist in Standard-Java-Ressourcenbündeln definiert (siehe die Dateien unter example/files/browse-resources). Der Text („Find“ auf Englisch), der direkt vor dem Sucheingabefeld erscheint, ist beispielsweise in jeder der sprachspezifischen Ressourcendateien wie folgt angegeben:
English: find=Find French: find=Recherche German: find=Durchsuchen
Das Werkzeug $resource des VelocityResponseWriters erkennt eine Gebietsschema-Einstellung. In der Vorlage browse.vm (example/files/conf/velocity/browse.vm) wird die Zeichenkette „find“ generisch wie folgt angegeben:
$resource.find: <input name=“q“…/>
Wir wollten, dass der Parameter zur Auswahl des Gebietsschemas von außen betrachtet sauber ist und alle Implementierungsdetails verbirgt, wie zum Beispiel /browse?locale=de_DE.
Der zugrundeliegende Parameter, der benötigt wird, um das Gebietsschema des VelocityResponseWriter $resource-Tools zu steuern, ist v.locale. Daher verwenden wir eine weitere Solr-Technik (Parametersubstitution), um den externen Parameter locale auf den internen Parameter v.locale zu mappen.
Diese Parametersubstitution unterscheidet sich von der „local param substitution“ (die mit den obigen „type“-Parametereinstellungen verwendet wird), die nur als exakte Parametersubstitution innerhalb der {!… Syntax} mit Dollarzeichen und ohne geschweifte Klammern {!… v=$foo} verwendet werden kann, wobei der Parameter foo (&foo=…) ersetzt wird. Die Syntax mit dem Dollarzeichen in geschweiften Klammern kann als Textersetzung an Ort und Stelle verwendet werden und erlaubt auch einen Standardwert wie ${param:default}
.
Damit die URLs einen locale=de_DE-Parameter unterstützen, wird dieser einfach in den eigentlichen v.locale-Parameter ersetzt, der verwendet wird, um die Locale im Velocity-Vorlagenkontext für die UI-Lokalisierung festzulegen. In params.json haben wir v.locale=$ angegeben.{locale}
Spracherkennung und Facettierung
Es kann praktisch sein, eine Gruppe von Dokumenten nach ihrer Sprache zu filtern. Praktischerweise verfügt Solr über zwei(!) verschiedene Spracherkennungsimplementierungen, so dass wir eine von ihnen wie folgt in unsere Aktualisierungsprozessorkette eingebunden haben:
<processor class="org.apache.solr.update.processor.LangDetectLanguageIdentifierUpdateProcessorFactory">
<lst name="defaults">
<str name="langid.fl">content</str>
<str name="langid.langField">language</str>
</lst>
</processor>
Wenn das Feld Sprache auf diese Weise indiziert ist, zeigt die Benutzeroberfläche einfach seine Facetten an (facet.field=language, in params.json) und ermöglicht so auch die Filterung.
Phrasen-/Einzelindexierung und „Tag Cloud“-Facettierung
Wenn Sie häufige Ausdrücke sehen, können Sie sich auf einen Blick einen Überblick über eine Reihe von Dokumenten verschaffen. Sie werden feststellen, dass sich die Top-Phrasen ändern, wenn Sie den Parameter „q“ ändern (oder nach Dokumenttyp oder Sprache filtern). Die Top-Phrasen spiegeln die Phrasen wider, die in der Teilmenge der Ergebnisse, die für eine bestimmte Abfrage und angewandte Filter zurückgegeben wurden, am häufigsten vorkommen. Klicken Sie auf eine Phrase, um die Dokumente in Ihrer Ergebnismenge anzuzeigen, die diese Phrase enthalten. Die Größe der Phrase entspricht der Anzahl der Dokumente, die diese Phrase enthalten.
Die Extraktion von Phrasen aus dem Text des Feldes „content“ erfolgt durch Kopieren in ein text_shingles-Feld, das mithilfe eines ShingleFilters Phrasen erzeugt. Diese Funktion befindet sich noch in der Entwicklung und muss verbessert werden, um qualitativ hochwertigere Phrasen zu extrahieren. Die derzeitige grobe Implementierung ist es nicht wert, hier einen Codeschnipsel einzufügen, um den Leuten zu suggerieren, sie sollten sie per Copy/Paste emulieren, aber hier ist ein Verweis auf die aktuelle Konfiguration – https://github.com/apache/lucene-solr/blob/branch_5x/solr/example/files/conf/managed-schema#L408-L427
Extraktion von E-Mail-Adressen und URLs zur Indexzeit
Eine derzeit noch nicht veröffentlichte Funktion, die aus Spaß hinzugefügt wurde, ist die Extraktion von E-Mail-Adressen und URLs aus dem Inhalt von Dokumenten zur Indexzeit. Bei der oben beschriebenen Extraktion von Phrasen geht es darum, Facettierung und Filterung zu ermöglichen, aber bei der Betrachtung eines einzelnen Dokuments brauchten wir die Phrasen nicht gespeichert und verfügbar. Mit anderen Worten: text_shingles musste kein gespeichertes Feld sein, so dass wir die copyField/fieldType-Technik nutzen konnten. Aber für extrahierte E-Mail-Adressen und URLs ist es sinnvoll, diese als gespeicherte (mehrwertige) Begriffe zu haben, nicht nur als indizierte Begriffe… was bedeutet, dass unsere Indizierungspipeline diese unabhängig gespeicherten Werte bereitstellen muss. Die copyField/fieldType-Extraktionstechnik wird hier nicht ausreichen. Wir können jedoch eine Feldtypdefinition zur Hilfe nehmen und ihre Möglichkeiten in einem Aktualisierungsskript nutzen. Aktualisierungsprozessoren, wie das hier verwendete Skript, ermöglichen die vollständige Manipulation eines eingehenden Dokuments, einschließlich des Hinzufügens zusätzlicher Felder, so dass ihr Wert „gespeichert“ werden kann. Hier sind die Konfigurationsteile, die E-Mail-Adressen und URLs aus dem Text extrahieren:
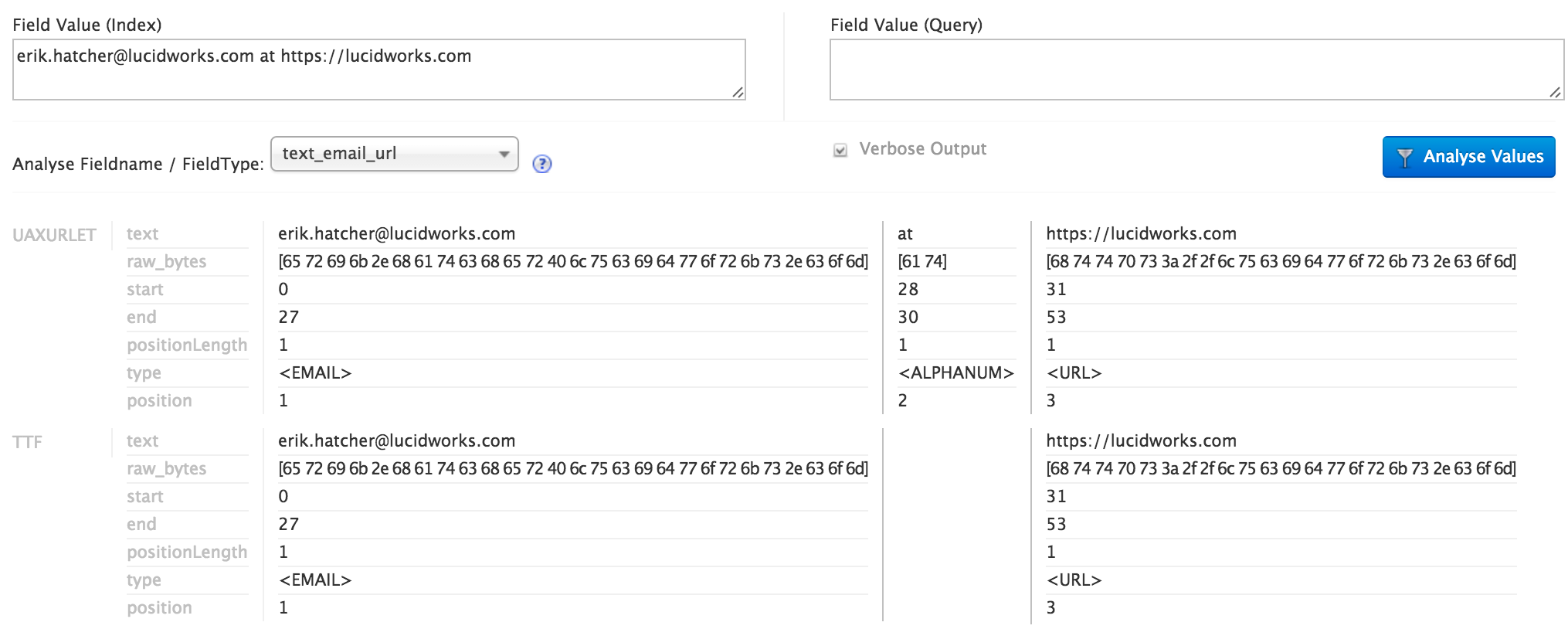
 Das Analyse-Tool der Solr-Admin-Oberfläche ist nützlich, um zu sehen, wie dieser Feldtyp funktioniert. Im ersten Schritt wird der Text durch den UAX29URLEmailTokenizer gemäß der Unicode UAX29-Segmentierungsspezifikation tokenisiert, mit dem speziellen Zusatz, E-Mail-Adressen und URLs zu erkennen und zusammenzuhalten. Bei der Analyse werden die erzeugten Token auch mit einem „Typ“ versehen. Der folgende Screenshot zeigt die Ergebnisse des Solr Admin-Analysetools bei der Analyse eines Strings „e-mail@lucidworks.com https://lucidworks.com“ mit dem Feldtyp text_email_url. Der Tokenizer kennzeichnet E-Mail-Adressen mit einem Typ von, wörtlich, “ <EMAIL>“ (einschließlich spitzer Klammern) und URLs als „<URL>“. Es gibt noch andere Arten von Token, die der URL/Email-Tokenizer ausgibt, aber für diesen Zweck wollen wir nur alles außer E-Mail-Adressen und URLs aussortieren. Geben Sie den TypeTokenFilter ein, der nur eine genau festgelegte Gruppe von Token-Typen durchlässt. Im Screenshot sehen Sie, dass der Text „at“ als Typ „“ identifiziert wurde.<ALPHANUM>“ und haben den Typfilter nicht durchlaufen. Eine externe Textdatei (email_url_types.txt) enthält die Typen, die durchgelassen werden sollen, und enthält einfach zwei Zeilen mit den Werten „<URL>“ und „<EMAIL>“.
Das Analyse-Tool der Solr-Admin-Oberfläche ist nützlich, um zu sehen, wie dieser Feldtyp funktioniert. Im ersten Schritt wird der Text durch den UAX29URLEmailTokenizer gemäß der Unicode UAX29-Segmentierungsspezifikation tokenisiert, mit dem speziellen Zusatz, E-Mail-Adressen und URLs zu erkennen und zusammenzuhalten. Bei der Analyse werden die erzeugten Token auch mit einem „Typ“ versehen. Der folgende Screenshot zeigt die Ergebnisse des Solr Admin-Analysetools bei der Analyse eines Strings „e-mail@lucidworks.com https://lucidworks.com“ mit dem Feldtyp text_email_url. Der Tokenizer kennzeichnet E-Mail-Adressen mit einem Typ von, wörtlich, “ <EMAIL>“ (einschließlich spitzer Klammern) und URLs als „<URL>“. Es gibt noch andere Arten von Token, die der URL/Email-Tokenizer ausgibt, aber für diesen Zweck wollen wir nur alles außer E-Mail-Adressen und URLs aussortieren. Geben Sie den TypeTokenFilter ein, der nur eine genau festgelegte Gruppe von Token-Typen durchlässt. Im Screenshot sehen Sie, dass der Text „at“ als Typ „“ identifiziert wurde.<ALPHANUM>“ und haben den Typfilter nicht durchlaufen. Eine externe Textdatei (email_url_types.txt) enthält die Typen, die durchgelassen werden sollen, und enthält einfach zwei Zeilen mit den Werten „<URL>“ und „<EMAIL>“.
Wir haben jetzt also einen Feldtyp, der die Erkennung und Extraktion von E-Mail-Adressen und URLs übernehmen kann. Lassen Sie uns diesen nun innerhalb der Aktualisierungskette verwenden, was bequem in update-script.js möglich ist. Mit etwas gruselig aussehendem JavaScript/Java/Lucene API-Voodoo wird dies mit dem oben gezeigten Code in update-script.js erreicht. Dieser Code ist im Wesentlichen die Art und Weise, wie indizierte Felder ihre Begriffe erhalten, wir müssen es nur selbst tun, damit die Werte *gespeichert* werden.
Diese Technik wurde ursprünglich im Abschnitt „Analyse in ScriptUpdateProcessor“ in dieser Präsentation beschrieben: http://www.slideshare.net/erikhatcher/solr-indexing-and-analysis-tricks
Beispiel/Dateien Demonstrationsvideo
Unser Dank geht an Esther Quansah, die während ihres Praktikums bei Lucidworks einen Großteil der Konfiguration der Beispiele/Dateien entwickelt und das Demonstrationsvideo produziert hat.
Wie geht es weiter mit example/files?
Ein übergeordneter Solr JIRA Eintrag wurde erstellt, um diese wünschenswerten Korrekturen und Verbesserungen zu notieren: https://issues.apache.org/jira/browse/SOLR-8590 – einschließlich der folgenden Punkte:
- E-Mail- und URL-Feldnamen korrigieren (<E-Mail>_ss und <url>_ss(mit spitzen Klammern in den Feldnamen), fügen Sie auch die Anzeige dieser Felder in der Ergebnisanzeige von /browse hinzu
- Update-Skript einschränken: Es schlägt derzeit fehl, wenn Dokumente kein Feld „Inhalt“ haben.
- Verbessern Sie die Qualität der extrahierten Phrasen
- Akronyme extrahieren, facettieren und anzeigen
- Fügen Sie Sortierfunktionen hinzu, möglicherweise alle oder einige der folgenden: Datum der letzten Änderung, Erstellungsdatum, Relevanz und Titel
- Vielleicht Gruppierung nach doc_type hinzufügen
- Behebung des Debug-Modus – derzeit wird die Debug-Ausgabe der geparsten Abfrage nicht aktualisiert (dies ist wahrscheinlich auch ein Fehler im datengesteuerten /browse)
- Gefälschte extrahierte E-Mail-Adressen herausfiltern
Die ersten beiden Punkte wurden behoben und der Patch wurde während des Schreibens dieses Beitrags eingereicht.
Fazit
Die Verwendung von example/files ist eine gute Möglichkeit, die eingebauten Fähigkeiten von Solr speziell für Rich-Text-Dateien zu erkunden.
Mit einer Menge Solr-Konfiguration und Parametertrickserei wird /browse?locale=de_DE&type=html eine viel sauberere Methode, dies zu tun: /select?v.locale=de_DE&fq={!field%20f=doc_type%20v=html}&wt=velocity&v.template=browse&v.layout=layout&q=*:*&facet.query={!ex=type%20key=all_types}*:*&facet=on… (und weitere Standardparameter)
Das Ziel, „eine echte Anwendung mit nur wenigen einfachen Befehlen zu erstellen“, ist erreicht! Es ist so prägnant und übersichtlich, dass Sie es sogar twittern können!
https://lucidworks.com/blog/2016/01/27/example_files:$ bin/solr start; bin/solr create -c files -d example/files; bin/post -c files ~/Documents #solr