Visualizing Search Results with Solr /browse & Velocity
The Series
This is the second in a three part series demonstrating how it’s possible to build a real application using just a few simple commands. The three parts to this are:
- Getting data into Solr using bin/post
- ==> (you are here) Visualizing search results: /browse and beyond
- Up next: Putting it together realistically: example/files – a concrete useful domain-specific example of bin/post and /browse
/browse – A simple, configurable, built-in templated results view
We foreshadowed to this point in the previous, bin/post, article, running these commands –
$ bin/solr create -c solr_docs $ bin/post -c solr_docs docs/
And here we are: http://localhost:8983
Or sticking with the command-line, this will get you there:
$ open http://localhost:8983/solr/solr_docs/browse?q=faceting
The legacy “collection1”, also known as techproducts
Seasoned Solr developers probably have seen the original incarnation of /browse. Remember /collection1/browse with the tech products indexed? With Solr 5, things got a little cleaner with this example and it can easily be launched with the -e switch:
$ bin/solr start -e techproducts
The techproducts example will not only create a techproducts collection it will also index a set of example documents, the equivalent of running:
$ bin/solr create -c techproducts -d sample_techproducts_configs $ bin/post -c techproducts example/exampledocs/*.xml
You’re ready to /browse techproducts. This can be done using “open” from the command-line:
$ open http://localhost:8983/solr/techproducts/browse
An “ipod” search results in:
The techproducts example is the fullest featured /browse interface, but it suffers from the kitchen sink syndrome. It’s got some cool things in there like as-you-type term suggest (type “ap” and pause, you’ll see “apple” appear), geographic search (products have contrived associated “store” locations), results grouping, faceting, more-like-this links, and “did you mean?” suggestions. While those are all great features often desired in our search interfaces, the techproducts /browse has been overloaded to support not only just the tech products example data, but also the example books data (also in example/exampledocs/) and even made to demonstrate rich text files (note the content_type facet). It’s convoluted to start with the techproducts templates and trim it down to your own needs, so the out of the box experience got cleaned up for Solr 5.
New and… generified
With Solr 5, /browse has been designed to come out of the box with the default configuration, data_driven_configs (aka “schema-less”). The techproducts example has its own separate configuration (sample_techproducts_configs) and custom set of templates, and they were left alone and as you see above. In order to make the templates work generically for most any type of data you’ve indexed, the default templates were stripped down to the basics and baked in. The first example above, solr_docs, illustrates the out of the box “data driven” experience with /browse. It doesn’t matter what data you put in to a data driven collection, the /browse experience starts with the basic search box and results display. Let’s delve into the /browse side of things with some very simple data in a fresh collection:
$ bin/solr create -c example $ bin/post -c example -params "f.tags.split=true" -type text/csv -d $'id,title,tagsn1,first document,An2,second document,"A,B"n3,third document,B' $ open http://localhost:8983/solr/example/browse
This generic interface shows search results from a query specified in the search box, displays stored field values, includes paging controls, has debugging/troubleshooting features (covered below) and includes a number of other capabilities that aren’t initially apparent.
Faceting
Because the default templates make no assumptions about the type of data or values in fields, there is no faceting on by default, but the templates support it. Add facet.field=tags to a /browse request such as http://localhost:8983

Clicking the value of a facet filters the results as naturally expected, using Solr’s fq parameter. The built-in, generic /browse templates, as of Solr 5.4, only support field faceting. Other faceting options (range, pivot, and query) are not supported by the templates – they simply won’t render in the UI. You’ll notice as you click around after manually adding “facet.field=tags” that the links do not include the manually added parameter. We’ll see below how to go about customizing the interface, including how to add a field facet to the UI. But let’s first delve into how /browse works.
Note: the techproducts templates do have some hard-coded support for other facets, which can be borrowed from as needed; continue on to see how to customize the view to suit your needs.
What makes /browse work?
In Solr technical speak, /browse is a search request handler, just like /select – in fact, on any /browse request you can set wt=xml to see the standard results that drive the view. The difference is that /browse has some additional parameters defined as defaults to enhance querying, faceting, and response writing. Queries are configured to use the edismax query parser. Faceting is turned on though no fields are specified initially, and facet.mincount=1 so as to not show zero count buckets. Response writing tweaks make the secret sauce to /browse, but otherwise it’s just a glorified /select.
VelocityResponseWriter
Requests to /browse are standard Solr search requests with the addition of three parameters:
wt=velocity: Use the VelocityResponseWriter for generating the HTTP response from the internal SolrQueryRequest and SolrQueryResponse objectsv.template=browse: The name of the template to renderv.layout=layout: The name of the template to use as a “layout”, a wrapper around the main v.template specified
Solr generally returns search results as data, as XML, JSON, CSV, or even other data formats. At the end of a search request processing the response object is handed off to a QueryResponseWriter to render. In the data formats, the response object is simply traversed and wrapped with angle, square, and curly brackets. The VelocityResponseWriter is a bit different, handing off the response data object to a flexible templating system called Velocity.
“Velocity”? Woah, slow down! What is this ancient technology of which you speak? Apache Velocity has been around for a long time; it’s a top-notch, flexible, templating library. Velocity lives up to its name – it’s fast too. A good starting point to understanding Velocity is an article I wrote many (fractions of) light years ago: “Velocity: Fast Track to Templating”. Rather than providing a stand-alone Velocity tutorial here, we’ll do it by example in the context of customizing the /browse view. Refer to the VelocityResponseWriter documentation in the Reference Guide for more detailed information.
Note: Unless you’ve taken other precautions, users that can access /browse could also add, modify, change, delete or otherwise affect collections, documents, and all kinds of things opening the possibility to data security leaks, denial of service attacks, or wiping out partial or complete collections. Sounds bad, but nothing new or different when it comes to /browse compared to /select, it just looks prettier, and user-friendly enough to want to expose to non-developers.
Customizing the view
There are several ways to customize the view; it ultimately boils down to the Velocity templates rendering what you want. Not all modifications require template hacking though. The built-in /browse handler uses a relatively new feature to Solr called “param sets”, which debuted in Solr 5.0. The handler is defined like this:
<requestHandler name="/browse" class="solr.SearchHandler" useParams="query,facets,velocity,browse">
The useParams setting specifies which param set(s) to use as default parameters, allowing them to be grouped and controlled through an HTTP API. An implementation detail, but param sets are defined in a conf/params.json file, and the default set of parameters is spelled out as such:
{"params":{
"query":{
"defType":"edismax",
"q.alt":"*:*",
"rows":"10",
"fl":"*,score",
"":{"v":0}
},
"facets":{
"facet":"on",
"facet.mincount": "1",
"":{"v":0}
},
"velocity":{
"wt": "velocity",
"v.template":"browse",
"v.layout": "layout",
"":{"v":0}
}
}}
The various sets aim to keep parameters grouped by function. Note that the “browse” param set is not defined, but it is used as a placeholder set name that can be filled in later. So far so good with straightforward typical Solr parameters being used initially. Again, ultimately everything that renders is a result of the template driving it. In the case of facets, all field facets in the Solr response will be rendered (from facets.vm). Using the param set API, we can add the “tags” field to the “facets” param set:
$ curl http://localhost:8983/solr/example/config/params -H 'Content-type:application/json' -d '{
"update" : {
"facets": {
"facet.field":"tags"
}
}
}'
Another nicety about param sets – their effect is immediate, whereas changes to request handler definitions require the core to be reloaded or Solr to be restarted. Just hit refresh in your browser on /browse, and the new tags facet will appear without being explicitly specified in the URL.
See also the file example/films/README.txt for an example adding a facet field and query term highlighting. The built-in templates are already set up to render field facets and field highlighting when enabled, making it easy to do some basic domain-specific adjustments without having to touch a template directly.
At this point, /browse is equivalent to this /select request: http://localhost:8983
Again, set wt=xml or wt=json and see the standard Solr response.
Overriding built-in templates
VelocityResponseWriter has a somewhat sophisticated mechanism for locating templates to render. Using a “resource loader” search path chain, it can get templates from a file system directory, the classpath, a velocity/ subdirectory of the conf/ directory (either on the file system or in ZooKeeper), and even optionally from request parameters. By default, templates are only configured to come from Solr’s resource loader which pulls from conf/velocity/ or from the classpath (including solrconfig.xml configured JAR files or directories). The built-in templates live within the solr-velocity JAR file. These templates can be extracted, even as Solr is running, to conf/velocity so that they can be adjusted. To extract the built-in templates to your collections conf/velocity directory, the following command can be used, assuming the “example” collection that we’re working with here.
$ unzip dist/solr-velocity-*.jar velocity/*.vm -d server/solr/example/conf/
This trick works when Solr is running in standalone mode. In SolrCloud mode, conf/ is in ZooKeeper as is conf/velocity/ and the underlying template files; if you’re not seeing your changes to a template be sure the template is where Solr is looking for it which may require uploading it to ZooKeeper. With these templates extracted from the JAR file, you can now edit them to suit your needs. Template files use the extension .vm, which stands for “Velocity macro” (“macro” is a bit overloaded, unfortunately, really these are best called “template” files). Let’s demonstrate changing the Solr logo in the upper left to a magnifying glass clip art image. Open server/solr<div id="head"> to the following, save the file, and refresh /browse in your browser:
<div id="head">
<a href="#url_for_home">
<!-- Borrowed from https://commons.wikimedia.org/wiki/File:Twemoji_1f50e.svg -->
<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/d/d5/Twemoji_1f50e.svg/50px-Twemoji_1f50e.svg.png"/>
</a>
</div>
#protip: your boss will love seeing the company logo on your quick Solr prototype. Don’t forget the colors too: the CSS styles can be customized in head.vm.
Customizing results list
The /browse results list is rendered using results_list.vm, which just iterates over all “hits” in the response (the current page of documents) rendering hit.vm for each result. The rendering of a document in the search results commonly is an area that needs some domain-specific attention. The templates that were extracted will now be used, overriding the built-in ones. Any templates that you don’t need to customize can be removed, falling back to the default ones. In this example, the template changed was specific to the “example” core. Newly created collections, even data-driven based ones, won’t have this template change.
NOTE: changes made will be lost if you delete the example collection – see the
-Dvelocity.template.base.dirtechnique to externalize templates from the configuration.
Debugging/Troubleshooting
I like using /browse for debugging and troubleshooting. In the footer of the default view there is an “enable debug” link adding a “debug=true” to the current search request. The /browse templates add a “toggle parsed query” link under the search box and a “toggle explain” by each search result hit. Searching for “faceting”, enabling debug, and toggling the parsed query tells us how the users query was interpreted, including what field(s) are coming into play and any analysis transformations like stemming or stop word removal that took place.
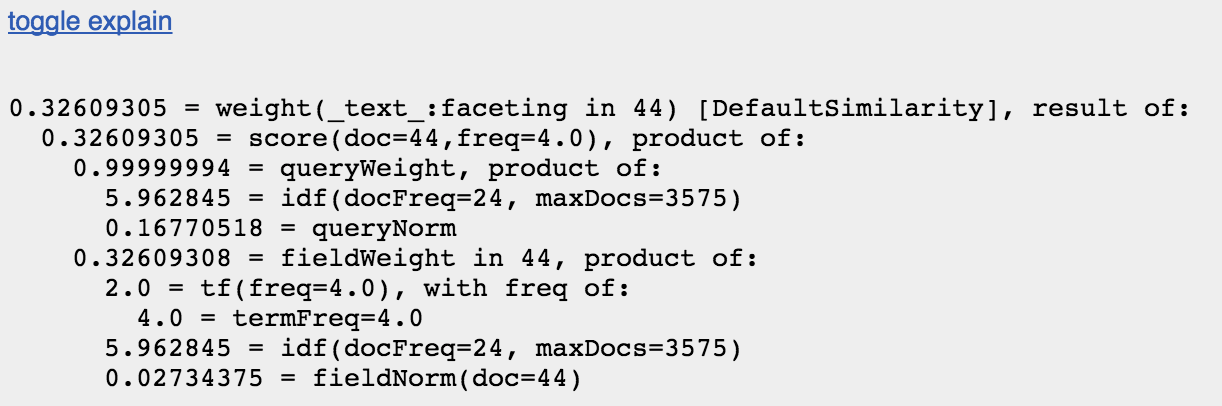
Toggling the explain on a document provides detailed, down to the Lucene-level, explanation of how this document matched and how the relevancy score was computed. As shown below, “faceting” appears in the _text_ field (a data_driven_configs copyField destination for all fields making everything searchable). “faceting” appears 4 times in this particular document (tf, term frequency), and appears in 24 total documents (docFreq, document frequency). The fieldNorm factor can be a particularly important one, a factor based on the number of terms in the field generally giving shorter fields a relevancy advantage over longer ones.
Conclusion
VelocityResponseWriter: it’s not for everyone or every use case. Neither is wt=xml for that matter. Over the years, /browse has gotten flack for being a “toy” or not “production-ready”. It’s both of those, and then some. VelocityResponseWriter has been used for:
- effective sales demos
- rapid prototyping
- powering one of our Lucidworks Fusion customers entire UI, through the secure Fusion proxy
- and even generating nightly e-mails from a job search site!
Ultimately, wt=velocity is for generating textual (not necessarily HTML) output from a Solr request.