Solr Nutzlasten
Bevor wir uns mit den technischen Details befassen, wie sieht das große Ganze aus? Welche realen Herausforderungen lassen sich mit diesen neuen Solr-Funktionen besser bewältigen? Hier sind einige Anwendungsfälle, bei denen Payloads helfen können:
- Preise pro Filiale
- gewichtete Begriffe, wie das Vertrauen oder die Wichtigkeit eines Begriffs
- Gewichtung der Begriffstypen, z.B. Synonyme niedriger oder Verben höher gewichten
Nun zu den technischen Details, beginnend damit, wie Nutzdaten in Lucene implementiert werden, und dann zur Integration von Solr.
Nutzlasten in Lucene
Das Herz von Solr wird von unserer Lieblings-Java-Bibliothek aller Zeiten, Lucene, angetrieben. Lucene verfügt schon seit einiger Zeit über diese Payload-Funktion, hat aber bisher nicht viel von sich hören lassen, weil sie bisher nicht nativ von Solr unterstützt wurde.
Nehmen wir uns einen Moment Zeit, um die Funktionsweise von Lucene aufzufrischen und dann zu zeigen, wo Payloads hineinpassen.
Lucene Index Struktur
Lucene erstellt einen invertierten Index des Inhalts, der ihm zugeführt wird. Ein invertierter Index ist im Grunde genommen ein einfaches Wörterbuch mit Wörtern aus dem Korpus, die alphabetisch geordnet sind, um sie später leicht wiederzufinden. Dieser invertierte Index eignet sich hervorragend für die Stichwortsuche. Sie möchten Dokumente mit „Katze“ im Titel finden? Schlagen Sie einfach „Katze“ im invertierten Index nach und lassen Sie sich alle Dokumente anzeigen, die diesen Begriff enthalten – ganz ähnlich wie beim Nachschlagen von Wörtern im Index am Ende eines Buches, um die entsprechenden Seiten zu finden.
Lucene findet Dokumente superschnell anhand der darin enthaltenen Wörter. Es kann auch erforderlich sein, Wörter in der Nähe zueinander zu finden. Daher zeichnet Lucene optional die Positionsinformationen auf, um den Abgleich von Phrasen, Wörtern oder Begriffen, die nahe beieinander liegen, zu ermöglichen. Die Positionsinformationen liefern die Wortnummer (oder den Positionsversatz) eines Begriffs: „Katzenhirte“ hat „Katze“ und „Hirte“ an aufeinanderfolgenden Positionen.
Für jedes Vorkommen eines indizierten Wortes (oder Begriffs) in einem Dokument werden die Positionsinformationen aufgezeichnet. Zusätzlich und optional können auch die Offsets (der tatsächliche Zeichenanfangs- und -endoffset) pro Begriffsposition kodiert werden.
Nutzlasten
Neben den positionsbezogenen Informationen ist auch ein optionales Byte-Array für allgemeine Zwecke verfügbar. Auf der untersten Ebene erlaubt Lucene jedem Begriff an jeder Position, beliebige Bytes in seinem Nutzdatenbereich zu speichern. Dieses Byte-Array kann abgerufen werden, wenn auf die Position des Begriffs zugegriffen wird.
Diese Byte-Arrays pro Begriff/Position können auf verschiedene Weise mit Hilfe einiger esoterischer eingebauter Lucene TokenFilter’s gefüllt werden, von denen ich im Folgenden ein paar enttarnen werde.
Der primäre Anwendungsfall einer Payload ist die Beeinflussung der Relevanzbewertung. Es gibt aber auch andere sehr interessante Möglichkeiten, Payloads zu verwenden, auf die wir später eingehen werden. Im Kern von Lucene ist der Scoring-Mechanismus float Similarity#computePayloadFactor() eingebaut, der bis jetzt noch von keinem Produktionscode in Lucene oder Solr verwendet wurde. Er ist robust, wird aber nur wenig genutzt, wenn man nicht auf Expertenebene kodiert, um sicherzustellen, dass die Nutzdaten zur Indexzeit auf die gleiche Weise kodiert werden, wie sie zur Abfragezeit dekodiert werden, und um diesen Mechanismus in die Auswertung einzubinden.
Nutzdaten in Solr
Einer der Vorteile von Solr besteht darin, dass die verwendeten Felder und Feldtypen streng definiert sind, so dass Index- und Abfragezeitverhalten synchronisiert sind. Die Unterstützung von Nutzdaten folgte, indem die Kodierung der Nutzdaten zur Indexzeit mit der Dekodierung zur Abfragezeit über die Feldtypdefinition verknüpft wurde.
Die hier beschriebenen Payload-Funktionen wurden in Solr 6.6 hinzugefügt und in SOLR-1485 nachverfolgt.
Lassen Sie uns mit einem End-to-End-Beispiel beginnen…
Solr 6.6 Nutzdaten Beispiel
Hier ein kurzes Beispiel für die Zuweisung von Float-Payloads pro Begriff und deren Nutzung:
bin/solr start bin/solr create -c payloads bin/post -c payloads -type text/csv -out yes -d $'id,vals_dpfn1,one|1.0 two|2.0 three|3.0n2,weighted|50.0 weighted|100.0'
Wenn Sie mit dem letzten Befehl Probleme haben, navigieren Sie zu http://localhost:8983/solr/#
id,vals_dpf 1,one|1.0 two|2.0 three|3.0 2,weighted|50.0 weighted|100.0
Zwei Dokumente (id 1 und 2) werden mit einem speziellen Feld namens vals_dpf indiziert. Die Standardkonfiguration von Solr sieht *_dpf vor, wobei das Suffix angibt, dass es sich um ein Feld vom Typ„delimited payloads, float“ handelt.
Lassen Sie uns sehen, was dieses Beispiel kann, und dann werden wir aufschlüsseln, wie es funktioniert hat.
Die Funktion payload() gibt eine Fließkommazahl zurück, die aus den numerisch kodierten Nutzdaten eines bestimmten Begriffs berechnet wird. Im ersten Dokument, das gerade indiziert wurde, hat der Begriff „eins“ einen Float-Wert von 1,0, „zwei“ einen Wert von 2,0 und „drei“ einen von 3,0. Im zweiten Dokument wird derselbe Begriff „gewichtet“ wiederholt, wobei die Nutzdaten für jede Position dieser Begriffe unterschiedlich sind (Sie erinnern sich, Nutzdaten sind pro Position).
Die Pseudofelder von Solr bieten eine nützliche Möglichkeit, auf Berechnungen von Nutzwertfunktionen zuzugreifen. Um zum Beispiel die Nutzlastfunktion für den Begriff „drei“ zu berechnen, verwenden wir payload(vals_dpf,three). Das erste Argument ist der Feldname und das zweite Argument ist der interessierende Begriff. http://localhost:8983/solr/
id,p 1,3.0 2,0.0
Das erste Dokument enthält den Begriff „drei“ mit einem Payload-Wert von 3.0. Das zweite Dokument enthält diesen Begriff nicht, und die Funktion payload() gibt den Standardwert 0.0 zurück.
Anhand der obigen indizierten Daten sehen Sie hier ein Beispiel, das alle verschiedenen Optionen der Funktion payload() nutzt:
id,def,first,min,max,avg 2,37.0,50.0,50.0,100.0,75.0
Es gibt eine nützliche Umleitung für die Parametersubstitution, damit der Feldname einmal als
f=vals_dpfangegeben und in allen Funktionen referenziert werden kann. In ähnlicher Weise wird der Begriffweightedals Abfrageparametertangegeben und in den Nutzdatenfunktionen ersetzt.
Beachten Sie, dass sich diese Abfrage auf q=id:2 beschränkt, um den Effekt bei mehreren beteiligten Nutzlasten zu demonstrieren. Der Ausdruck fl def:payload($f,not_there,37) findet keinen Begriff „not_there“ und gibt den angegebenen Standardwert von 37,0 zurück. avg:payload($f,$t,0.0,average) nimmt den Durchschnitt der Nutzlasten, die an allen Positionen des Begriffs „gewichtet“ (50,0 und 100,0) gefunden wurden, und gibt den Durchschnitt, 75,0, zurück.
Indizierung von Begriffen mit Payloads
Die Standardkonfiguration (data_driven) verfügt über drei neue Feldtypen, die Nutzdaten verwenden. Im obigen Beispiel wurde der Feldtyp delimited_payloads_float verwendet, der einer dynamischen Felddefinition *_dpf zugeordnet ist, so dass Sie ihn sofort verwenden können. Dieser Feldtyp wird mit einem WhitespaceTokenizer gefolgt von einem DelimitedPayloadTokenFilter definiert. Textlich gesehen handelt es sich lediglich um einen Leerzeichen-Tokenizer (Groß- und Kleinschreibung ist wichtig!). Wenn das Token mit einem senkrechten Strich (|) gefolgt von einer Fließkommazahl endet, werden das Trennzeichen und die Zahl aus dem indizierten Begriff entfernt und die Zahl in die Nutzdaten kodiert.
Das Analyse-Tool von Solr bietet einen Einblick in die Funktionsweise dieser begrenzten Nutzdatenfeldtypen. Anhand des ersten Dokuments aus dem vorherigen Beispiel und einer einfachen (nicht ausführlichen) Ausgabe sehen wir die Auswirkungen der Leerraum-Tokenisierung, gefolgt von der Filterung der begrenzten Nutzdaten, wobei die grundlegende textuelle Indizierung des Begriffs das Basiswort/der Token-Wert ist und das Begrenzungszeichen und alles, was darauf folgt, entfernt wird. Für die Indizierung bedeutet dies, dass die Begriffe „eins“, „zwei“ und „drei“ indiziert und mit Standardabfragen durchsuchbar sind, so als hätten wir „eins zwei drei“ in ein Standardtextfeld indiziert.

Wenn Sie die Indizierungsanalyse etwas genauer betrachten, indem Sie die ausführliche Ansicht einschalten, sehen Sie im folgenden Screenshot eine Hex-Dump-Ansicht der Nutzdatenbytes, die jedem Begriff in der letzten Zeile mit der Bezeichnung „Nutzdaten“ zugeordnet sind.
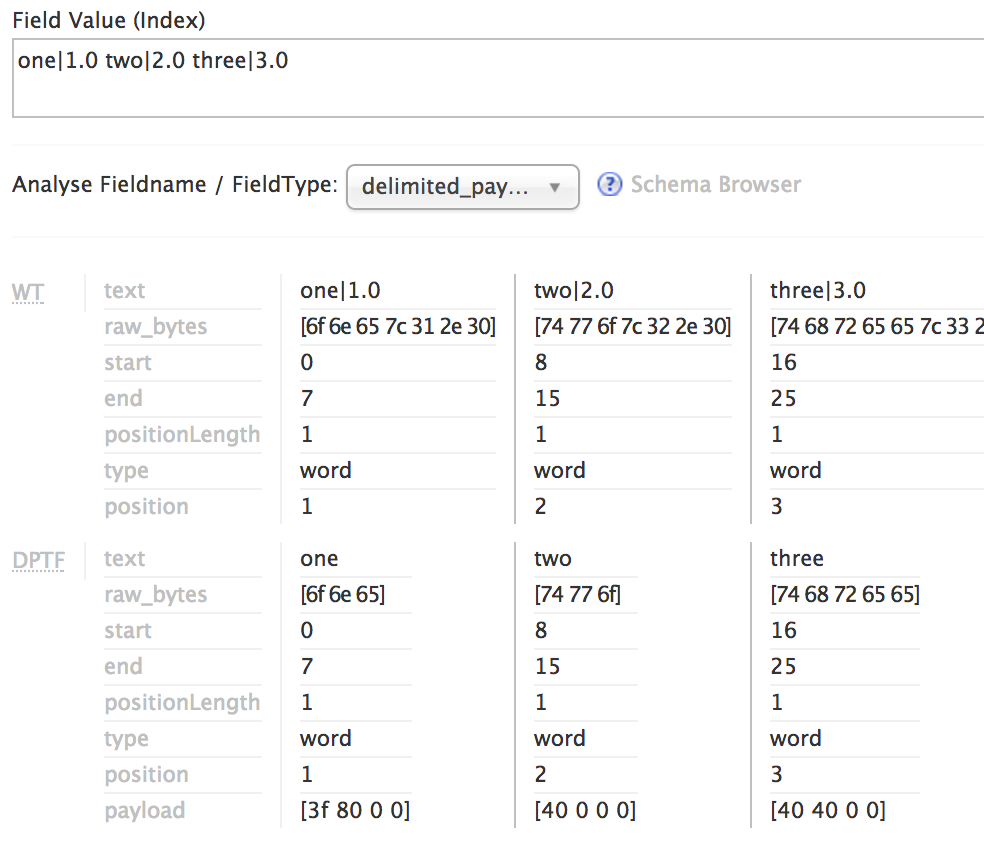
Bezahlte Feldtypen
Diese neuen bezahlten Feldtypen sind in der data_driven Konfiguration von Solr verfügbar:
| Feldtyp | Nutzdatenkodierung | dynamische Feldzuordnung |
delimited_payloads_float |
Schwimmer | *_dpf |
delimited_payloads_int |
Ganzzahl | *_dpi |
delimited_payloads_string |
String, so wie er ist | *_dps |
Jedes dieser Programme ist mit Leerzeichen versehen und filtert die Nutzdaten, wobei der Unterschied in der verwendeten Kodierung/Dekodierung der Nutzdaten liegt.
payload() Funktion
Die payload() Funktion gibt im einfachen Fall von eindeutigen, sich nicht wiederholenden Begriffen mit einer numerischen Nutzlast (Integer oder Float) den tatsächlichen Nutzlastwert zurück. Wenn die Funktion payload() auf Begriffe stößt, die sich wiederholen, nimmt sie entweder den first Wert, auf den sie stößt, oder sie durchläuft alle Begriffe und gibt den minimum, maximum oder average Nutzlastwert zurück.
Die payload() Funktionssignatur lautet wie folgt:
payload(field,term[,default, [min|max|average|first]])
wobei die Standardwerte 0.0 für den Standardwert und für die Mittelung der Nutzlastwerte sind.
Zurück zu den Anwendungsfällen
Das ist großartig, drei = 3,0, und der Durchschnitt von 50,0 und 100,0 ist 75,0. Als ob wir Nutzdaten bräuchten, um uns das zu sagen. Wir hätten ein Feld, z.B. words_t mit „drei drei drei“ indizieren und termsfreq(words_t,three) ausführen können und hätten 3 zurückbekommen. Wir könnten die Felder min_f auf 50.0 und max_f auf 100.0 setzen und div(sum(min_f,max_f),2) verwenden, um 75.0 zu erhalten.
Nutzlasten bieten uns eine weitere Technik, die uns neue Möglichkeiten eröffnet.
Preisgestaltung pro Filiale
Das Geschäft boomt, wir haben Läden im ganzen Land! Logistik ist schwierig und teuer. Je näher ein Widget am Geschäft hergestellt wird, desto weniger Versandkosten fallen an; oder besser gesagt, es kostet mehr für ein Widget, je weiter es reisen muss. Abgesehen von der vielleicht nicht ganz so ausgeklügelten Argumentation ist diese Art von Situation mit der Preisgestaltung von Produkten pro Filiale bei einigen Unternehmen so. Wenn ein Kunde also in meinem Online-Shop stöbert, wird er mit seinem bevorzugten oder nächstgelegenen physischen Geschäft verknüpft, in dem alle angezeigten Produktpreise ( facettiert und sortiert, nicht zu vergessen!) spezifisch für die Preisgestaltung in diesem Geschäft für dieses Produkt sind.
Betrachten wir das Ganze einmal ganz pragmatisch: Wenn Sie fünf Geschäfte haben, sollten Sie vielleicht fünf Solr-Kollektionen anlegen, bei denen außer den Preisen alles gleich ist. Was ist, wenn Sie 100 Geschäfte haben und es werden immer mehr? Dann wird die Verwaltung so vieler Kollektionen zu einer ganz neuen Komplexität, so dass Sie vielleicht ein Feld für jedes Geschäft in jedem Produktdokument haben. Beides funktioniert und funktioniert gut…. bis zu einem gewissen Punkt. Es gibt Vor- und Nachteile dieser verschiedenen Ansätze. Aber was ist, wenn wir 5000 Geschäfte haben? Bei vielen Feldern werden die Dinge unhandlich, da Solr die Felder zwischenspeichert und pro Feld aufschlüsselt. Stellen Sie sich vor, ein Benutzer aus jeder Filialregion führt eine Suche mit Sortierung und Facettierung durch und multipliziert eine traditionelle numerische Sortieranforderung mit 5000. Eine andere Technik, die von vielen eingesetzt wird, ist die Verknüpfung von Produkten mit Geschäften und die Erstellung eines Dokuments für jedes Geschäft und jedes Produkt. Dies ist vergleichbar mit einer Sammlung pro Geschäft, führt aber sehr schnell zu einer großen Anzahl von Dokumenten (num_stores * num_products kann eine Menge sein!). Schauen wir uns an, wie wir mit Payloads eine andere Möglichkeit haben, mit dieser Situation umzugehen.
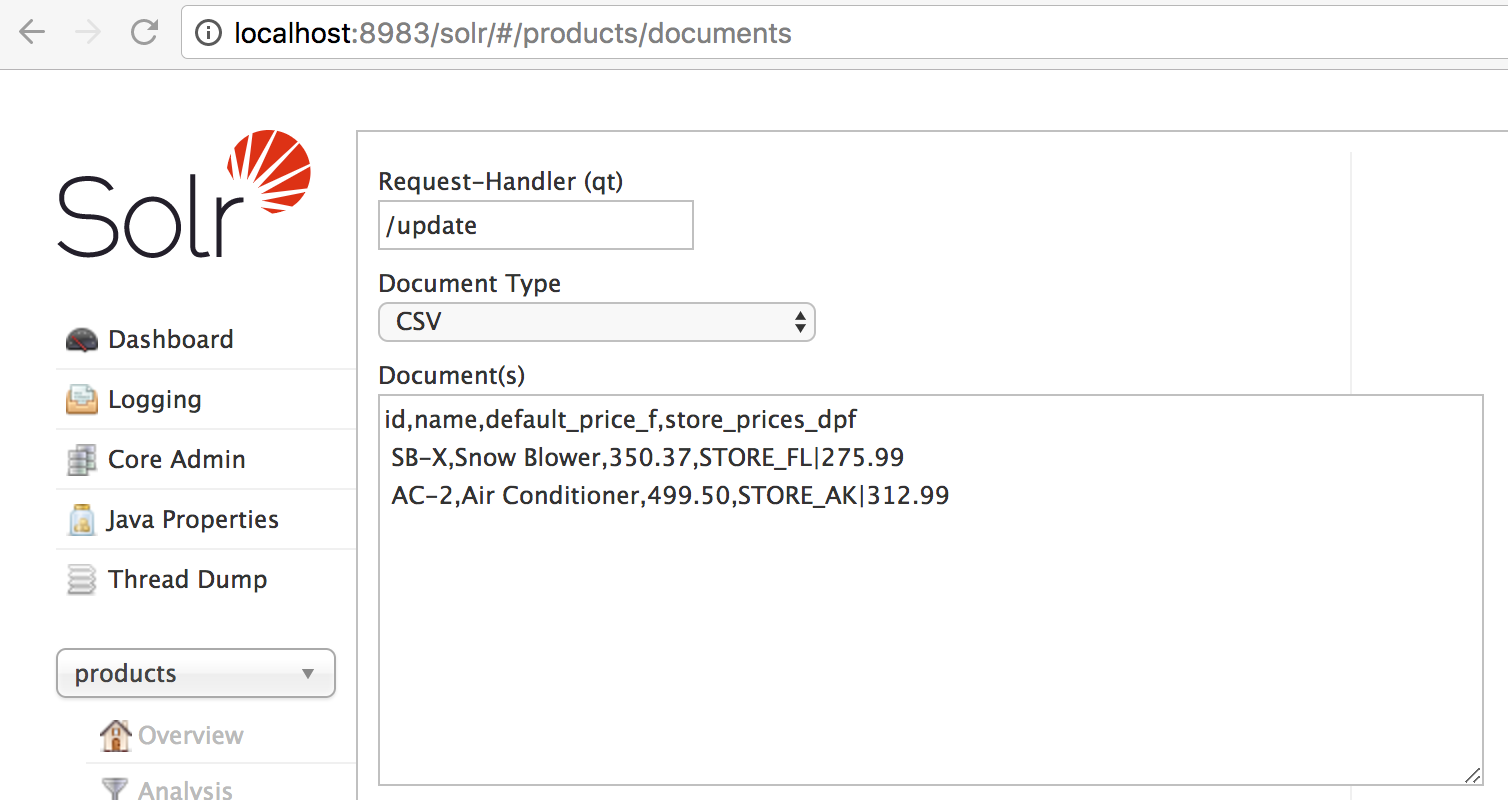
Erstellen Sie eine Produktsammlung mit bin/solr create -c products und importieren Sie dann die folgenden Daten per CSV. Am einfachsten ist es, die Registerkarte Dokumente im CSV-Modus zu verwenden, diese Daten einzufügen und abzuschicken:
id,name,default_price_f,store_prices_dpf SB-X,Snow Blower,350.37,STORE_FL|275.99 AC-2,Air Conditioner,499.50,STORE_AK|312.99
Ich habe mich an dynamische Feldzuordnungen gehalten, damit die Dinge in diesem Beispiel einfach funktionieren, aber ich persönlich würde sauberere Namen für real verwenden, z.B. default_price anstelle von default_price_fundstore_prices anstelle von store_prices_dpf.
Lassen Sie uns alle Produkte finden, sortiert nach Preis, zuerst nach default_price_f: http://localhost:8983/
In Alaska ist das allerdings nicht die richtige Sortierreihenfolge. Verknüpfen wir die Anfrage mit STORE_AK, indem wir &store_id=STORE_AK verwenden, und sehen wir uns den berechneten Preis auf der Grundlage der mit store_id verknüpften Nutzlast für jedes Produktdokument mit &computed_price=payload(store_prices_dpf,$store_id,default_price_f) an. Beachten Sie, dass diese beiden Parameter unsere sind und nicht die von Solr. Mit einer Funktion, die als separater Parameter definiert ist, können wir sie dort wiederverwenden, wo wir sie brauchen. Um das Feld anzuzeigen, fügen Sie es mit &fl=actual_price:${computed_price} zu fl hinzu, und um danach zu sortieren, verwenden Sie &sort=${computed_price} asc.
Um auf die Ansätze mit der Preisgestaltung pro Filiale zurückzukommen, stellen Sie sich vor, wir hätten 5000 Filialen. 5000*Anzahl_der_Produkte Dokumente versus 5000 Sammlungen versus 5000 Felder versus 5000 Begriffe. Lucene ist gut für viele Begriffe pro Feld geeignet, und mit Payloads ist es eine gute Lösung für dieses Szenario mit vielen Werten pro Dokument.
Facettierung bei numerischen Nutzdaten
Die Facettierung ist derzeit etwas schwieriger mit berechneten Werten, da facet.range funktioniert nur mit tatsächlichen Feldern, nicht mit Pseudofeldern. Da in diesem Fall nicht viele Preisspannen benötigt werden, können wir facet.query’s zusammen mit {!frange} auf payload() verwenden. Mit den Beispieldaten können wir die Facette auf (berechnete/echte) Preisspannen anwenden. Die folgenden beiden Parameter definieren zwei Preisspannen:
facet.query={!frange key=up_to_400 l=0 u=400}${computed_price}(beinhaltet Preis=400.00)facet.query={!frange key=above_400 l=400 incl=false}${computed_price}(schließt Preis=400.00 aus, mit „include lower“ incl=false)
Je nachdem, welche store_id wir übergeben, haben wir entweder beide Produkte im Bereich up_to_400 (STORE_AK) oder ein Produkt in jedem Bereich (STORE_FL). Unter dem folgenden Link finden Sie die vollständige URL mit diesen beiden Preisklassenfacetten: /products/query?…
Hier ist der Preisbereich Facettenausgabe mit store_id=STORE_AK:
facet_queries: {
up_to_400: 2,
above_400: 0
}
Gewichtete Begriffe
Dieser spezielle Anwendungsfall wird genau wie das Preisbeispiel implementiert, wobei anstelle von Store-Identifikatoren beliebige Begriffe verwendet werden. Dies könnte zum Beispiel nützlich sein, um dieselben Wörter je nach dem Kontext, in dem sie erscheinen, unterschiedlich zu gewichten – Wörter, die in ein <H1> html-Tag geparst werden, könnten ein höheres Payload-Gewicht erhalten als andere Begriffe. Oder bei der Indizierung kann die Entitätsextraktion Konfidenzgewichte über die Konfidenz der Entitätswahl zuweisen.
Um Nutzdaten zu Begriffen zuzuordnen, die die Filterung von begrenzten Nutzdaten-Token verwenden, muss der Indizierungsprozess die Begriffe in der begrenzten Form „term|payload“ erstellen.
Synonym Gewichtung
Eine Technik, die viele von uns verwendet haben, ist der copyField-Trick mit zwei Feldern, wobei in einem Feld Synonyme aktiviert sind und in einem anderen Feld keine Synonyme gefiltert werden, und die Verwendung von Abfragefeldern (edismax qf), um das nicht-synonyme Feld höher zu gewichten als das synonyme Feld, so dass die Relevanz bei exakten Übereinstimmungen erhöht wird.
Stattdessen können Payloads verwendet werden, um Synonyme innerhalb eines einzelnen Feldes herunterzugewichten. Beachten Sie, dass dies eine Technik zur Indexzeit mit Synonymen ist, nicht zur Abfragezeit. Das Geheimnis dahinter liegt in einer praktischen Analysekomponente namens NumericPayloadTokenFilterFactory – dieser praktische Filter weist allen Begriffen, die dem angegebenen Token-Typ entsprechen, in diesem Fall „SYNONYM“, die angegebene Nutzlast zu. Der Synonymfilter injiziert Begriffe mit diesem speziellen Token-Typ-Wert. Der Token-Typ wird in der Regel ignoriert und in keiner Weise indiziert, ist aber während des Analyseprozesses nützlich, um ihn für andere Operationen wie diesen Trick zu nutzen, bei dem nur bestimmten markierten Token eine Nutzlast zugewiesen wird.
Lassen Sie uns zu Demonstrationszwecken eine neue Sammlung erstellen, mit der wir experimentieren können: bin/solr create -c docs
Es gibt keinen eingebauten Feldtyp, für den dies bereits eingerichtet ist, also fügen wir einen hinzu:
curl -X POST -H 'Content-type:application/json' -d '{
"add-field-type": {
"name": "synonyms_with_payloads",
"stored": "true",
"class": "solr.TextField",
"positionIncrementGap": "100",
"indexAnalyzer": {
"tokenizer": {
"class": "solr.StandardTokenizerFactory"
},
"filters": [
{
"class": "solr.SynonymGraphFilterFactory",
"expand": "true",
"ignoreCase": "true",
"synonyms": "synonyms.txt"
},
{
"class": "solr.LowerCaseFilterFactory"
},
{
"class": "solr.NumericPayloadTokenFilterFactory",
"payload": "0.1",
"typeMatch": "SYNONYM"
}
]
},
"queryAnalyzer": {
"tokenizer": {
"class": "solr.StandardTokenizerFactory"
},
"filters": [
{
"class": "solr.LowerCaseFilterFactory"
}
]
}
},
"add-field" : {
"name":"synonyms_with_payloads",
"type":"synonyms_with_payloads",
"stored": "true",
"multiValued": "true"
}
}' http://localhost:8983/solr/docs/schema
Mit diesem Feld können wir ein Dokument hinzufügen, dem Synonyme zugewiesen werden (die mitgelieferte synonyms.txt enthält Television, Televisions, TV, TVs). Auch dieses Dokument fügen wir über den Solr-Administrationsbereich Dokumente für die soeben erstellte Sammlung docs mit dem Dokumenttyp CSV hinzu:
id,synonyms_with_payloads 99,tv
Wenn wir dieses Mal den {!payload_score} Query Parser verwenden, können wir nach „tv“ wie folgt suchen: http://localhost:8983/solr/docs/select?
die zurückgibt:
id,score 99,1.0
Wenn Sie &payload_term=television ändern, verringert sich die Punktzahl auf 0,1.
Diese Zuordnung von Termtypen zu numerischen Nutzdaten kann über Synonyme hinaus nützlich sein – es gibt eine Reihe anderer Token-Typen, die verschiedene Solr-Analysekomponenten zuweisen können, darunter <EMAIL> und <URL>Token, die UAX29URLEmailTokenizer extrahieren kann.
Abfrage-Parser, die die Nutzlast beherrschen
Es gibt zwei neue Abfrage-Parser, die Nutzdaten nutzen, payload_score und payload_check. In der folgenden Tabelle finden Sie die Syntax dieser Parser:
| Abfrage-Parser | Beschreibung | Spezifikation |
{!payload_score} |
SpanQuery/Phrase Matching, Scores basierend auf numerisch kodierten Payloads, die an die übereinstimmenden Begriffe angehängt sind |
|
{!payload_check} |
SpanQuery/Phrase-Matching, die eine bestimmte Nutzlast an der angegebenen Position haben, Punkte basierend auf SpanQuery/Phrase-Scoring |
|
Beide Abfrageparser tokenisieren die Abfragezeichenfolge auf der Grundlage der Definition der Abfragezeitanalyse des Feldtyps (Leerzeichen-Tokenisierung für die eingebauten Nutzlasttypen) und formulieren eine exakte Phrasenabfrage (SpanNearQuery) zum Abgleich.
{!payload_score} Abfrage Parser
Die {!payload_score} Abfrageparser passt auf die angegebene Phrase und bewertet jedes Dokument auf der Grundlage der Nutzdaten, die für die Abfragebegriffe gefunden wurden, unter Verwendung des Minimal-, Maximal- oder Durchschnittswerts. Zusätzlich kann die natürliche Punktzahl der Phrasenübereinstimmung, die auf den üblichen Indexstatistiken für die Abfragebegriffe basiert, mit dem berechneten Bewertungsfaktor für die Nutzlast multipliziert werden ( includeSpanScore=true).
{!payload_check} Abfrage-Parser
Bislang haben wir uns auf numerische Nutzdaten konzentriert, aber auch Strings (oder rohe Bytes) können in Nutzdaten kodiert werden. Diese nicht-numerischen Nutzdaten können zwar nicht mit der payload()-Funktion verwendet werden, die ausschließlich für numerisch kodierte Nutzdaten gedacht ist, aber sie können für eine zusätzliche Ebene des Abgleichs verwendet werden.
Fügen wir unserer ursprünglichen Sammlung „payloads“ ein weiteres Dokument hinzu, indem wir das dynamische Feld *_dps verwenden, um die Nutzdaten als Strings zu kodieren:
id,words_dps 99,taking|VERB the|ARTICLE train|NOUN
Die bequeme Befehlszeile zum Indizieren dieser Daten lautet:
bin/post -c payloads -type text/csv -out yes -d $'id,words_dpsn99,taking|VERB the|ARTICLE train|NOUN'
Wir haben jetzt drei Begriffe, die mit ihrer Wortart geladen wurden. Mit {!payload_check} können wir nach „train“ suchen und erhalten nur Treffer, wenn der Begriff als „NOUN“ geladen wurde:
q={!payload_check f=words_dps v=train payloads=NOUN}
wenn stattdessen payloads=VERB, würde dieses Dokument nicht übereinstimmen. Die Wertung von {!payload_check} ist die Wertung der SpanNearQuery, die unter Verwendung von Payloads für den Abgleich generiert wird. Wenn mehrere Wörter für die Hauptabfrage angegeben werden, müssen mehrere Nutzdaten angegeben werden, die in der gleichen Reihenfolge wie die angegebenen Abfragebegriffe übereinstimmen. Die angegebenen Payloads müssen durch Leerzeichen getrennt sein. In diesem Beispiel können wir „der Zug“ abgleichen, wenn diese beiden Wörter in der Reihenfolge ein ARTIKEL und ein NOUN sind:
q={!payload_check f=words_dps v='the train' payloads='ARTICLE NOUN'}
während payloads='ARTICLE VERB' nicht übereinstimmt.
Fazit
Die Nutzdatenfunktion liefert Metadaten zu den einzelnen Begriffen, die die Bewertungen beeinflussen und eine zusätzliche Ebene für den Abfrageabgleich bieten können.
Nächste Schritte
Oben haben wir gesehen, wie man mit Nutzdaten eine Bereichsfacettierung durchführt. Das ist zwar nicht ideal, aber es besteht Hoffnung auf eine echte Bereichsfacettierung über Funktionen. Verfolgen Sie SOLR-10541, um zu sehen, wann diese Funktion implementiert wird.
Kurz nach Abschluss dieser Arbeiten an Solr wurde Lucene um eine nützliche Funktion erweitert, die das Überschreiben von Termhäufigkeiten ermöglicht, was eine Abkürzung für die uralte Technik der wiederholten Schlüsselwörter darstellt. Dies wurde für Lucene 7.0 unter LUCENE-7854 implementiert. Wie bei den oben beschriebenen Token-Filtern zur Begrenzung der Nutzlast gibt es jetzt auch eine DelimitedTermFrequencyTokenFilter. Die Nutzlast wird pro Termposition kodiert, was die Indexgröße erhöht und eine zusätzliche Suche pro Termposition erfordert, um sie abzurufen und zu dekodieren. Die Begriffshäufigkeit hingegen ist ein einzelner Wert für einen bestimmten Begriff. Sie ist auf ganzzahlige Werte beschränkt und ist leistungsfähiger als eine Nutzlast. Die Funktion payload() kann so geändert werden, dass sie ganzzahlig kodierte Nutzdaten und abgegrenzte Termfrequenzüberschreibungen transparent unterstützt (Hinweis: die Funktion termfreq() würde in diesem Fall bereits funktionieren). Verfolgen Sie SOLR-11358 für den Status der Implementierung der transparenten term frequency / integer payload().
Außerdem wurde leider ein Fehler im Modus debug=true bei der Verwendung von payload() gemeldet, wenn Assertions aktiviert sind. Ein Fix ist im Patch unter SOLR-10874 enthalten, der ab 7.2 enthalten ist.