
Vektorraum-Retrievalmodelle für E-Commerce
Dieser Beitrag wurde ursprünglich von Grid Dynamics veröffentlicht und von Stanislav Stolpovskiy (Senior Software Architect), Eugene Steinberg (Technical Fellow, Head of Digital Commerce), Maria Dyuldina (Senior Data Scientist) und Dmitry Rusyaikin (Data Scientist) geschrieben.
Maschinelles Lernen ist ein wesentlicher Bestandteil des modernen Suchsystems. ML-Modelle helfen in vielen Bereichen des Such-Workflows, z. B. bei der Klassifizierung von Absichten, der Analyse von Suchanfragen, der Auswahl von Facetten und vor allem bei der Neueinstufung von Ergebnissen.
In diesem Blog-Beitrag werden wir die Vorteile der Ausweitung von Modellen des maschinellen Lernens auf den zentralen Teil des Such-Workflows – die Dokumentensuche – untersuchen und eine Reihe von Beiträgen starten, um die Umsetzung der Ideen zu beschreiben, die in Semantische Vektorsuche: die neue Grenze der Produktfindung und Nicht die Suchmaschine Ihres Vaters: eine kurze Geschichte der Einzelhandelssuche behandelt werden .
Vektorabfrage in der modernen E-Commerce-Suchmaschine
Wie bei den meisten Suchsystemen bildet die Häufigkeitsverteilung von E-Commerce-Suchanfragen ein „Kopf-Rumpf-Schwanz-Muster“:
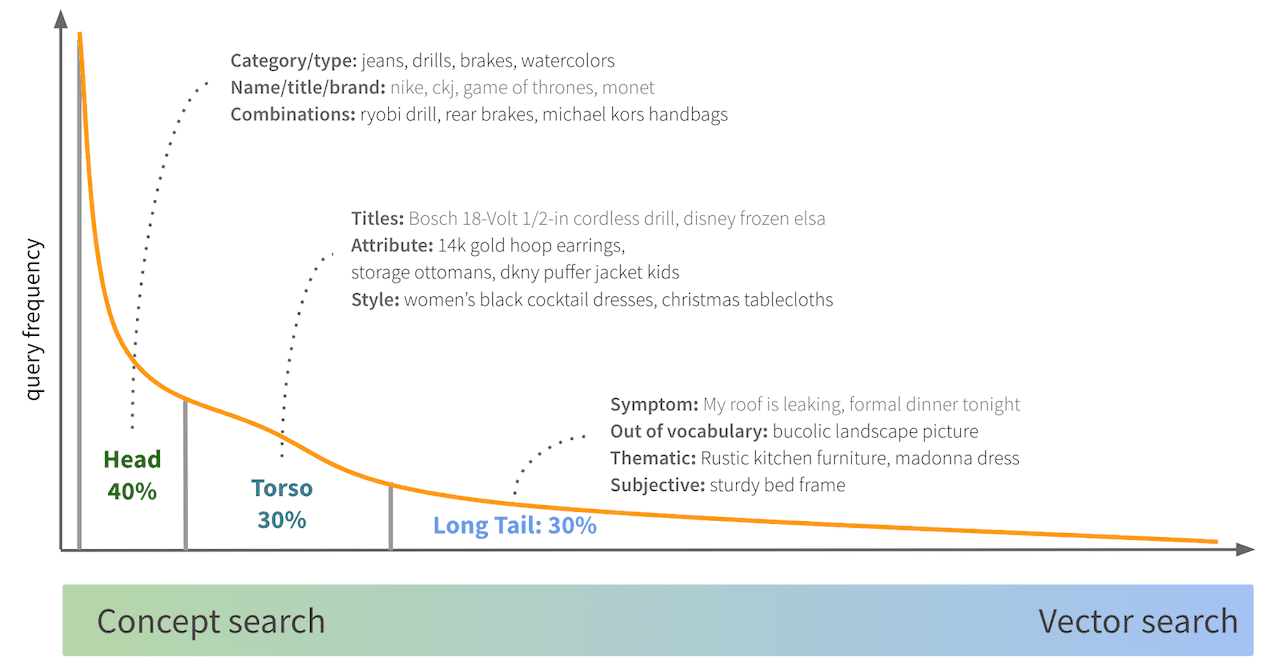
- Bei den Hauptabfragen, die einen großen Teil des gesamten Datenverkehrs ausmachen, handelt es sich in der Regel um sehr einfache Abfragen, die auf einer Produktkategorie/einem Produkttyp oder ein oder zwei wichtigen Produktattributen basieren.
- Torso-Abfragen enthalten Titel beliebter Produkte und Kombinationen von Attributen und Stilen.
- Long-Tail-Abfragen führen oft zu Abfragen in natürlicher Sprache, die nicht mehr im Vokabular enthalten sind, sowie zu thematischen und subjektiven Abfragen
Für die Kopf-, viele Rumpf- und einige der Longtail-Abfragen ist eine konzeptorientierte Abfrageanalyse (auch bekannt als Konzeptsuche) normalerweise ausreichend. Bei der Konzeptsuche wird versucht, semantisch vollständige Teile der Abfrage auf die entsprechenden Attribute und Beschreibungen in Produkten abzubilden.
Bei komplexen Long-Tail-Anfragen ist die Konzeptsuche jedoch oft unzureichend. Heutzutage gibt es eine neue Art der Produktsuche, die unter den Suchpraktikern schnell an Popularität gewinnt – die Vektorsuche. Heutzutage ist es möglich, ein Deep-Learning-Modell zu erstellen, das sowohl die Suchanfrage als auch die Katalogprodukte in denselben mehrdimensionalen Vektorraum vektorisiert. Dies ermöglicht eine neue Art der Abfrage mit Hilfe von Algorithmen für die Vektorsuche in der nächsten Umgebung.
Im Mittelpunkt dieses Blogbeitrags steht das Deep Learning-Modell, das sowohl Anfragen als auch Produkte in den gemeinsamen Vektorraum einbettet.
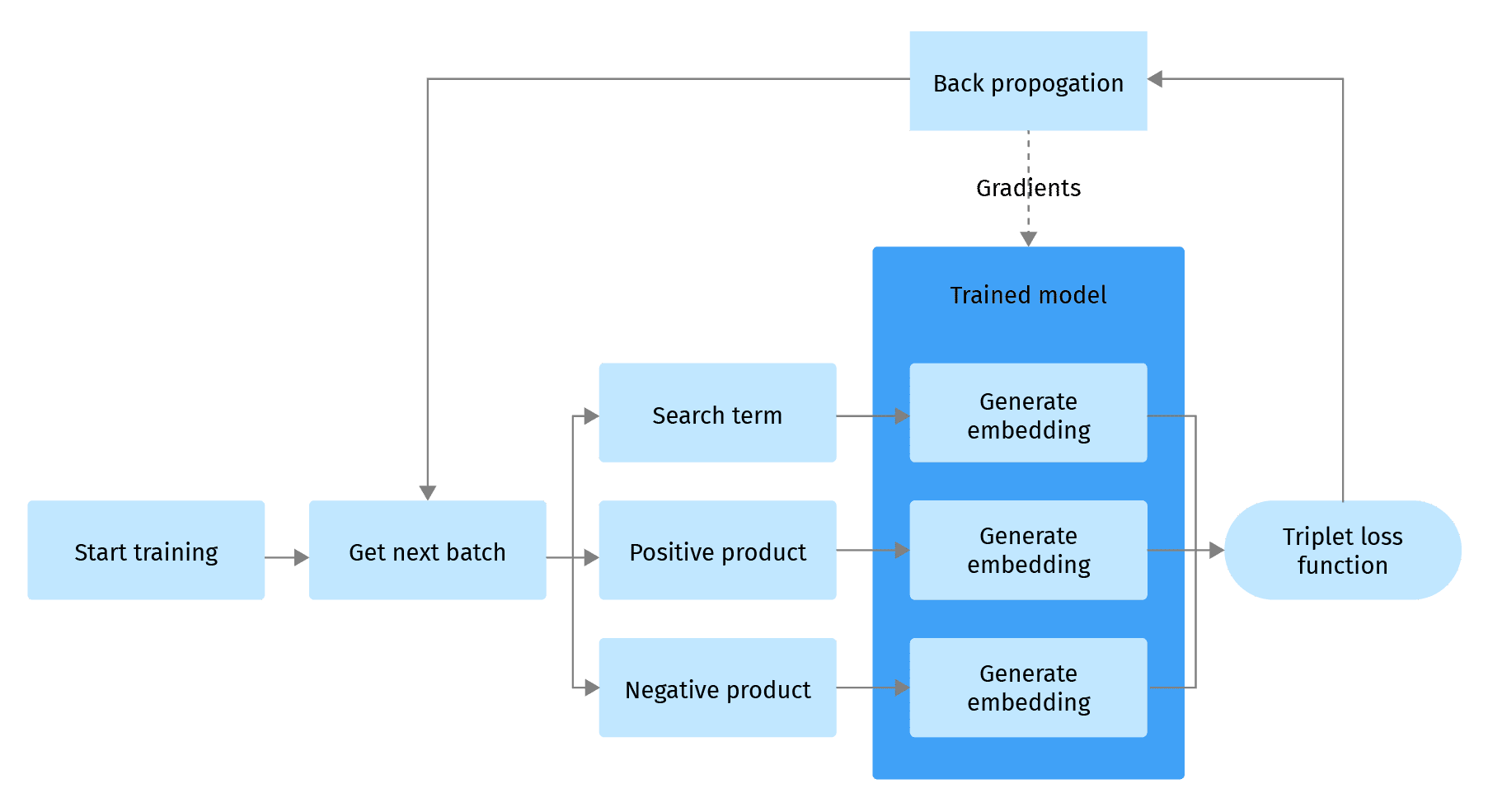
Sammeln von Modell-Trainingsdaten
Der Schlüssel zum Aufbau eines ML-basierten Retrievalsystems sind Trainingsdaten, die Beispiele für Produkte liefern, die für eine Suchanfrage relevant sind. Idealerweise hätten wir gerne ein explizites „Relevanzurteil“ des Kunden darüber, wie relevant ein bestimmtes Produkt für seine Anfrage ist. Natürlich ist diese Art von Beurteilung in der realen Welt so gut wie unmöglich zu erhalten. Das Nächstbeste, was wir tun können, ist, das Kundenverhalten bzw. die Clickstream-Daten als Ersatz für die Beurteilung der Relevanz zu verwenden. Wir können unsere Produkte zum Beispiel nach ihrer Beliebtheit und der Anzahl der Klicks und Käufe einstufen:
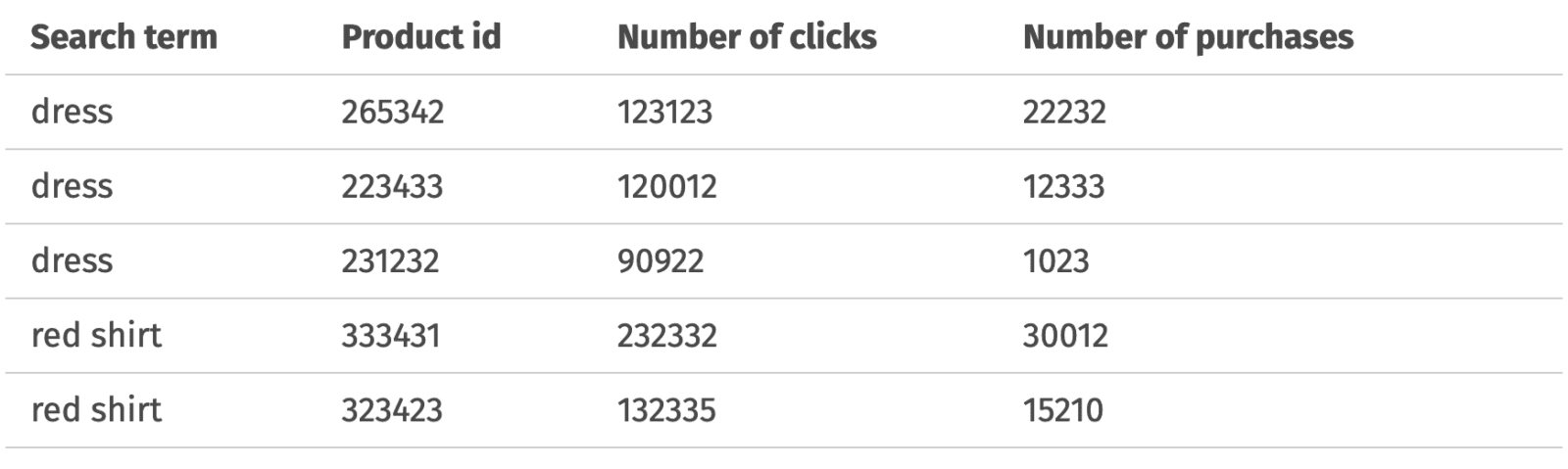
Der Verlauf der Suchmaschine und der Clickstream sind nicht die einzige Möglichkeit, Daten zur Beurteilung der Relevanz zu erhalten. Die Clickstream-Daten werden stark von der Qualität der aktuellen Suchmaschine beeinflusst. Wenn die aktuelle Suchmaschine beispielsweise keine relevanten Produkte abruft oder keine Ergebnisse liefert, gibt es für die Kunden keine Möglichkeit, auf die relevanten Produkte zu klicken und uns ein Relevanzsignal zu geben.
Es gibt verschiedene Techniken, die zur Erweiterung der Clickstream-Daten verwendet werden können:
- die Verfeinerung/Neuformulierung von Suchanfragen aus der gleichen Suchsitzung
- Produkte, die beim Durchsuchen von Kategorien entdeckt wurden, in der gleichen Sitzung abbauen, was besonders bei Suchbegriffen mit geringer Trefferquote nützlich ist
- Erkennung von Suchvorgängen mit anschließender Produktempfehlung von globalen Suchmaschinen wie Google und Bing in derselben Benutzersitzung
- Verfolgung der Verweise von Suchmaschinen auf Ihre Website einschließlich der Verwendung von Suchbegriffen
Wenn solche Informationen mit ausreichender statistischer Signifikanz aggregiert werden, können sie zu einer Fundgrube für Daten zur Beurteilung der Relevanz werden.
Es ist auch möglich, vorhandene Clickstream-Daten mit Hilfe von High-End-Allzweck-NLP-Modellen zu erweitern, die als Ausgangspunkt für die Relevanzbeurteilung dienen. BERT-ähnliche Modelle, insbesondere nach einer Feinabstimmung der Domaindaten, sind hierfür sehr nützlich.
Ein weiterer nützlicher Ansatz besteht darin, aus Katalogdaten generierte Abfragen zu synthetisieren. Dieser Ansatz hilft uns, das Problem des Kaltstarts zu bekämpfen, wenn wir nicht über genügend Daten zur Nutzeraktivität für neue Produkttypen oder Marken verfügen. Bei diesem Ansatz kombinieren wir Produktattribute, um eine Abfrage zu erstellen, und betrachten alle Produkte, die diese Kombination von Attributen enthalten, als relevant, wobei die Punktzahl proportional zu ihrer Beliebtheit ist.
Hier finden Sie einige Tipps zur Abfragesynthese:
- bevorzugen Attributwerte, die in Suchprotokollen beliebt sind und oft als Filter verwendet werden.
- Vermeiden Sie Attribute, die viele sich überschneidende Werte haben, da Sie sonst Abfragen wie „weiße weiße Jeans“ erzeugen.
- Die Abfragesynthese ist ein zweischneidiges Schwert und kann das Relevanzmodell in die Irre führen, wenn sie zu aggressiv eingesetzt wird. Verwenden Sie sie hauptsächlich für schlecht abgedeckte Kategorien und als Kaltstart für neue Produkte und Marken.
Einrichten der Datenverarbeitung
Bevor die Daten für das Modelltraining verwendet werden, sollten sie mehrere Vorverarbeitungsschritte durchlaufen. Das Ziel dieser Schritte ist eine bessere Tokenisierung und Normalisierung der Abfragen im Hinblick auf ein bestimmtes Domänenwissen.
Natürlich kann das ML-Modell theoretisch bei einer ausreichend großen Datenmenge die notwendigen Datenmuster selbst herausfinden. In der Praxis ist es jedoch immer besser, einen Teil des Domänenwissens früh in die Trainingspipeline einzubauen, um die Datenknappheit zu bekämpfen und das Modell schneller konvergieren zu lassen.
Die Vorverarbeitung beginnt mit Kleinschreibung und ASCII-Faltung. Danach sind die Textmerkmale bereit für die Tokenisierung. Allerdings sollten wir die direkte Tokenisierung von Leerzeichen vermeiden, da dadurch oft die Bedeutung von Sätzen zerstört wird. Intelligentere, domänenspezifische Tokenisierer, die Größen, Dimensionen, Altersgruppen und Farben berücksichtigen, können weitaus bessere Token für das Modell erzeugen, die es verarbeiten kann.
Es ist wichtig, Token zu normalisieren, z.B. um Größeneinheiten zu vereinheitlichen. Stemming und das Entfernen von Stoppwörtern sind ebenfalls gängige Praktiken bei der Vorverarbeitung von Textmerkmalen. Bei der Entfernung von Stoppwörtern müssen Sie jedoch vorsichtig sein, da z.B. „not/no/nor“ in der NLTK-Standardliste der Stoppwörter enthalten ist und wenn Sie diese weglassen, kann die Bedeutung des Konzepts verloren gehen.
Die Normalisierung ermöglicht es uns, Clickstream-Daten zu de-duplizieren, zu gruppieren und zusammenzuführen. Wenn wir zum Beispiel die Abfragen „Kleider“ und „Kleid“ haben, werden sie nach der Normalisierung beide zu „Kleid“ und die Clickstream-Daten können zwischen diesen beiden Abfragen zusammengeführt werden.
Sobald die Daten normalisiert und bereinigt sind, ist es an der Zeit, sie als Vektoren zu kodieren. Wir können Token- und Subtoken-Kodierer verwenden, um unsere Token darzustellen:
- auf der Token-Ebene werden wir Unigramme und Bigramme erstellen
- auf der Ebene der Teilwörter ist es am einfachsten, Trigramme auf Zeichenebene zu verwenden. Alternativ können wir uns für separat trainierbare Teilwort-Tokenizer entscheiden, wie z.B. sentencepiece.
Beide Repräsentationen sind einhändig kodiert und beide Vektoren werden verkettet.
Modell Architektur
Unser Retrieval-Modell ist inspiriert vom DSSM-Modell, das von Microsoft Research veröffentlicht wurde. Um den allgemeinen Ansatz aus dieser Arbeit auf den elektronischen Handel zu übertragen, müssen wir berücksichtigen, dass es sich bei E-Commerce-Produkten um halbstrukturierte Dokumente handelt. Wir haben Produktmerkmale: Attribute, Bilder, Beschreibungen, die unterschiedliche semantische Bedeutung haben. Wir möchten diese Merkmale separat kodieren und sie dann in den endgültigen Produkteinbettungsvektor zusammenführen, der sich in dem mehrdimensionalen Vektorraum befindet, den sich Produkte und Suchanfragen teilen:
Um diese Art der semantischen Kodierung zu erreichen, werden wir die folgende Architektur des neuronalen Netzes verwenden, das getrennte Eingaben für Katalogprodukte und Suchbegriffe hat, aber dennoch gemeinsame Einbettungen für diese Begriffe erzeugt.
Die Produkteigenschaften werden je nach Art des Produkts über verschiedene Encoder gesteuert:
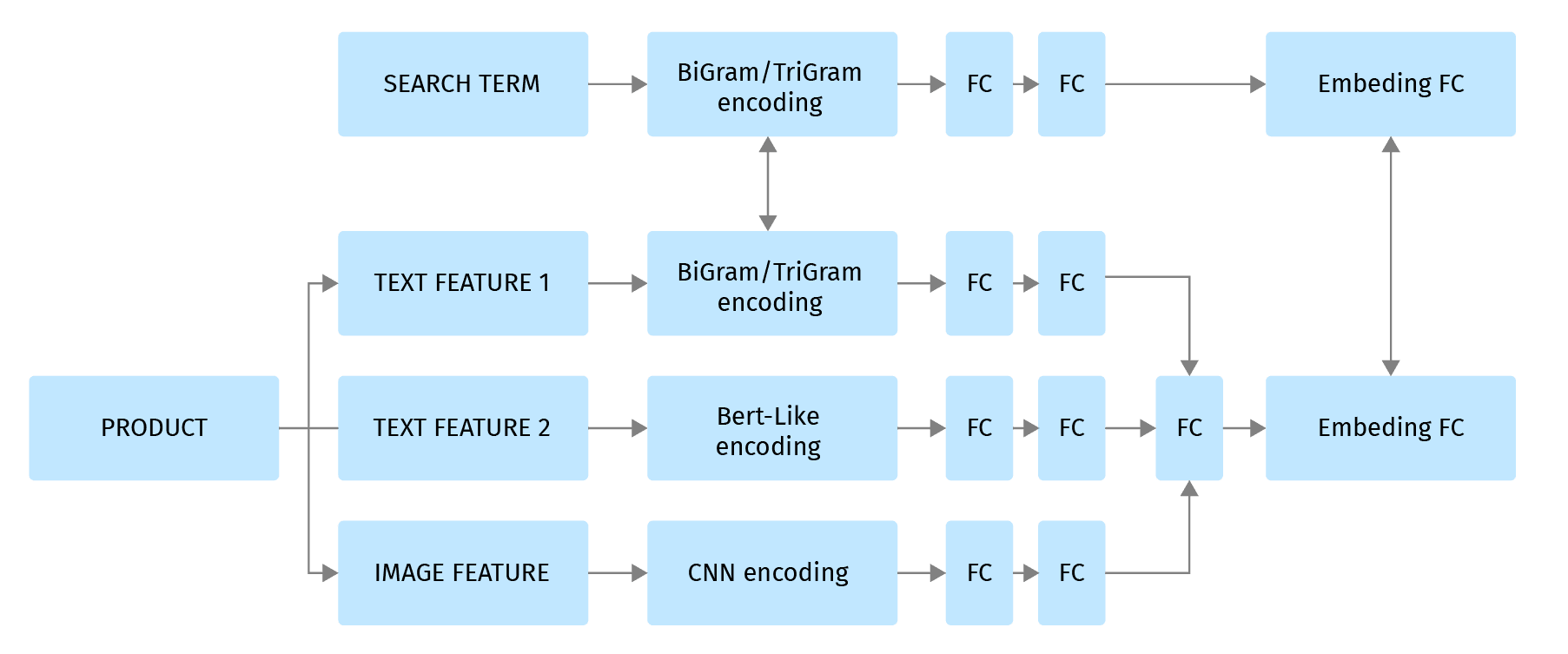
Textmerkmale können mit einer Kombination der folgenden Methoden verarbeitet werden:
- Traditionelles Bag-of-Word- oder TF-IDF-gewichtetes Bag-of-Words-Modell, wie z.B. von TfidfVectorizer aus dem sklearn-Paket erstellt.
- TriGram-Kodierung auf Char-Ebene (oder eine andere Tokenizer-Technik für Unterwörter) zur Kodierung von Begriffen außerhalb des Vokabulars und von Rechtschreibfehlern.
- Transformer-Modelle, wie Albert oder Electra. Diese Netzwerke erzeugen CLS-Token für die Satzeingabe oder wortweise Token, die mit der 1D-CNN-Schicht weiterverarbeitet werden können. Beachten Sie, dass Transformatoren für beste Ergebnisse auf Domaindaten fein abgestimmt werden müssen.
Bilder können auch mit einer Vielzahl von Encodern analysiert werden:
- Inhaltsextrahierende Kodierer auf der Grundlage von vortrainierten ResNext-50 oder einer ähnlichen Architektur
- Neuronale Encoder
- Vortrainierte CNN-Klassifikatoren zur Extraktion domänenspezifischer Attribute
Die Merkmalseinbettungen werden mit mehreren vollständig verknüpften Schichten nachbearbeitet und zu einer einzigen Einbettung zusammengefügt.
Schließlich werden die Kodierung des Suchbegriffs und die Produktkodierung in denselben mehrdimensionalen Vektorraum abgebildet, indem eine voll verknüpfte Schicht mit gemeinsamen Gewichten für den Produkt- und den Anfrageteil verwendet wird.
Model Ausbildung
Wir möchten unser Modell so trainieren, dass es Produkte und Abfragen so in einen Vektorraum einbettet, dass Abfragen und Produkte, die für diese Abfragen relevant sind, sich in derselben Nachbarschaft befinden. Mathematisch gesehen bedeutet dies, dass diese Vektoren in Bezug auf eine Metrik, die einen Abstand im mehrdimensionalen Vektorraum misst, wie z.B. die Kosinus-Metrik, nahe beieinander liegen sollten .
Wir werden den Trainingsansatz mit Triplettverlusten verwenden, der eine beliebte Wahl ist, wenn wir das Modell für ähnlich gelagerte Aufgaben trainieren wollen, wie z.B. Empfehlungen für ähnliche Personen, Gesichtserkennung und andere Aufgaben, bei denen wir versuchen, Vektorrepräsentationen unserer Entitäten in einem Vektorraum zu clustern und zu suchen.
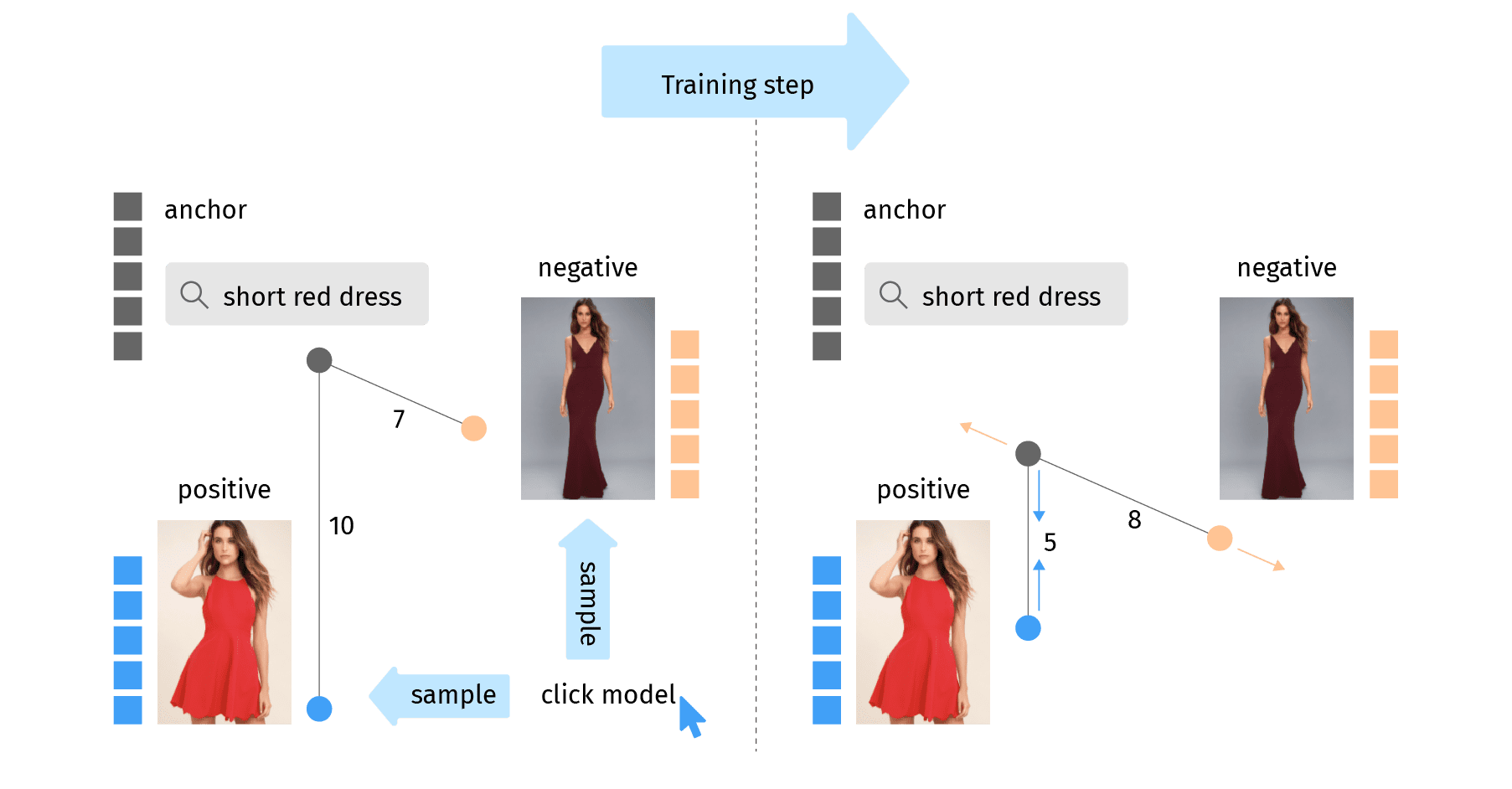
Der Grundgedanke des Triplet-Loss-Trainingsansatzes besteht darin, ein Triplett von Datenpunkten auszuwählen: Anker, positive und negative Probe. Die Triplet-Verlustfunktion belohnt es, wenn der Anker und die positive Probe um eine bestimmte Marge näher beieinander liegen als der Anker und die negative Probe. In unserem Fall der gemeinsamen Einbettung von Produkt und Anfrage haben wir eine Anfrage als Anker, ein relevantes Produkt als positive Probe und ein irrelevantes Produkt als negative Probe.
Mathematisch gesehen sieht die Formel für den Verlust von Drillingen im Falle eines Stapels von N Drillingen wie folgt aus:
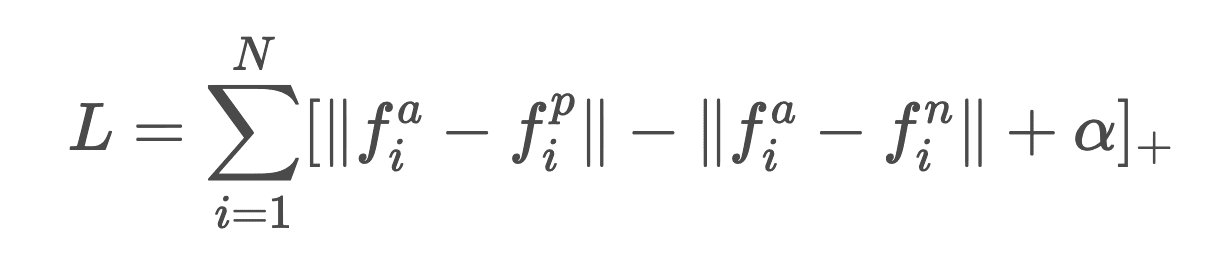
Dabei ist fa- ein Abfragevektor, der als Anker fungiert, fp- ein positiver Produktvektor und fn- ein negativer Produktvektor, α ist eine empirisch gewählte Konstante, ||x|| ist eine euklidische Norm, [x]+ = max(0,x).
Beachten Sie, dass wir einen Margin-Wert benötigen, um zu verhindern, dass alle Einbettungen in Nullvektoren kollabieren. Wenn alle Vektoren 0 sind und wir keine Marge haben, wird auch die Verlustfunktion Null, was wir vermeiden müssen. Zu diesem Zweck fügen wir einen Randwert hinzu, um den alle negativen Abstände zwischen den Abfragen die positiven Abstände zwischen den Abfragen übersteigen sollten. Diese Verlustfunktion wird einen Gradienten erzeugen, der Anker und Positiv zusammenzieht und Anker und Negativ auseinander treibt.
Nach vielen Iterationen dieses einfachen Schritts werden wir für jede Anfrage und jedes Produkt eine optimale Einbettung erreichen.
Eine der Schlüsselfragen im Prozess des Triplettverlusts ist die richtige Auswahl der Tripletts. Unser Datensatz enthält bisher nur die Abfrage-Positiv-Paare, so dass wir jedes dieser Paare um eine Negativprobe ergänzen müssen.
Der einfachste Ansatz ist die Verwendung einer Zufallsstichprobe aus dem Katalog. Wenn der Katalog groß genug ist, besteht eine faire Chance, dass es sich bei dem entnommenen Produkt um eine negative Stichprobe handelt. Bei diesem Ansatz gibt es einige Herausforderungen:
- Breit angelegte Suchanfragen, wie z.B. „Schuhe“, rufen oft große Teile des Katalogs ab, und es besteht eine große Wahrscheinlichkeit, dass ein positives Beispiel als negativ eingestuft wird, was das Netzwerk verwirren wird. Beachten Sie, dass die Clickstream-Daten oft nur die erste Seite aller passenden Produkte enthalten, so dass sie nicht zuverlässig verwendet werden können, um diese falsch negativen Beispiele auszusortieren.
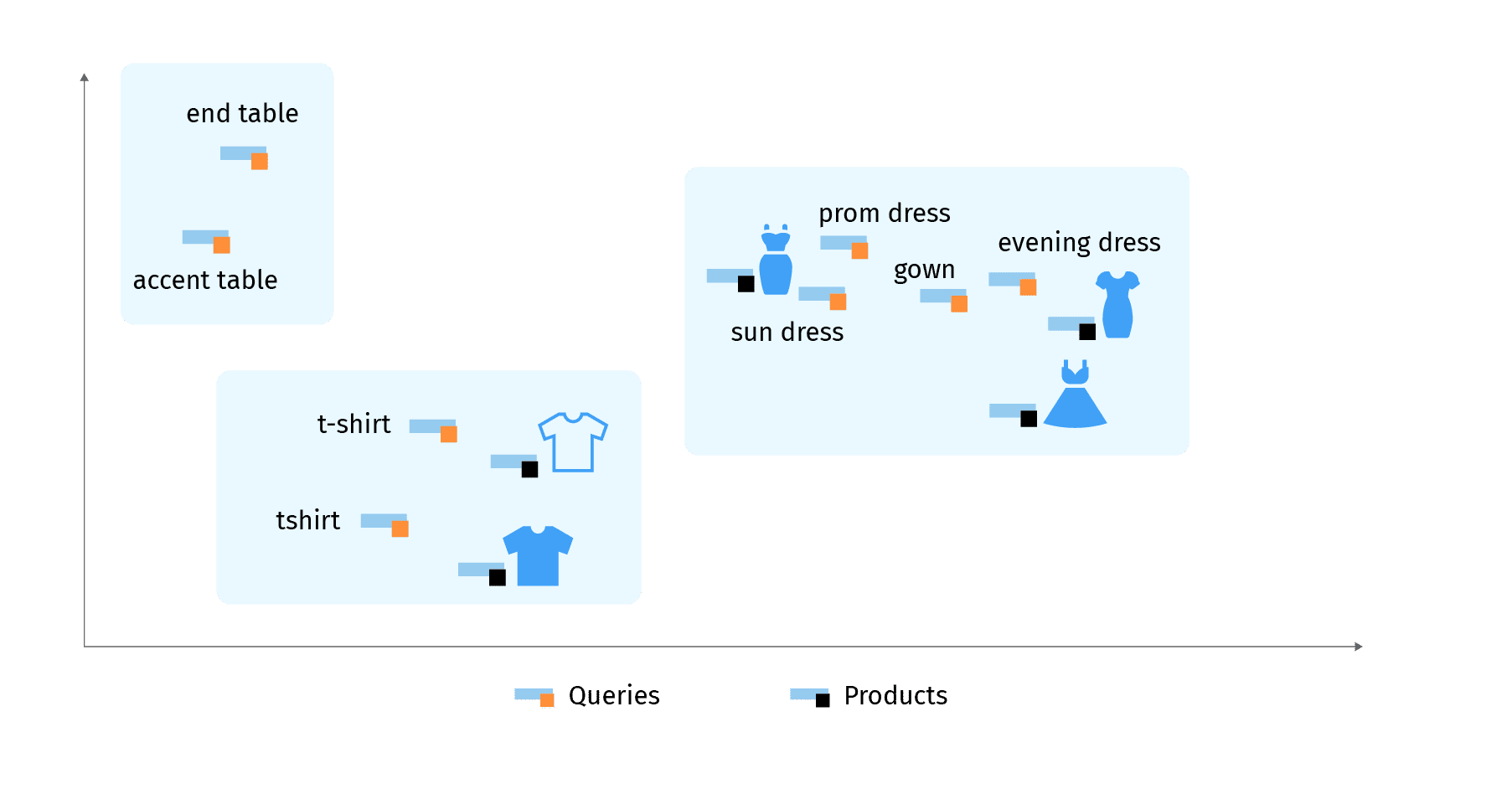
- Zufällig ausgewählte Negative können zu negativ sein. Nach einiger Zeit lernt das Netzwerk, Kleider zuverlässig von Waschmaschinen zu unterscheiden, und der Lernfortschritt hört auf. Das Netzwerk wird nicht lernen, lange Kleider von kurzen Kleidern und Sommerkleider von Abendkleidern zu unterscheiden.
Wir brauchen also eine andere Technik, um bessere Negative zu finden. Betrachten wir die Arten von Negativen, die wir im Katalog haben, am Beispiel der Abfrage „Cocktailkleid“. Wir können ein kurzes schwarzes Kleid und ein langes Abendkleid abrufen. In diesem Fall ist das kurze schwarze Kleid relevanter als das lange. Gleichzeitig ist ein langes Kleid im Vergleich zu Pullovern und Waschmaschinen viel relevanter. Das bedeutet, dass wir zwischen klasseninternen und klassenfremden Negativen unterscheiden sollten. In der Anfangsphase des Trainings sind klassenfremde Negative wichtiger, um dem Modell zu helfen, die wichtigsten Produkttypen zu unterscheiden, damit es nicht zu wirklich bizarren Ergebnissen kommt, während in den späteren Phasen des Trainings klasseninterne Negative immer wichtiger werden, um Nuancen zu verstehen.
Es ist eine gute Idee, zu parametrisieren, welchen Teil der negativen Stichproben innerhalb und außerhalb der Klasse wir nehmen und mit verschiedenen Verteilungen und Möglichkeiten zu experimentieren, diesen Parameter während des Trainings zu ändern. Wir können auch eine Verlustfunktion modifizieren, um unterschiedliche Margen für klasseninterne und klassenfremde negative Proben zu erhalten. Ähnliche Ideen finden sich in Arbeiten zur Re-Identifizierung von Personen mit dem Quadruplet-Verlustansatz.
Eine weitere wichtige Technik ist die Suche nach harten Negativen. Die Hauptidee besteht darin, Triplets für die Backpropagation auszuwählen, die die „härtesten“ Proben enthalten. Diese Optimierungstechnik kann auf Batch- und Epochenebene eingesetzt werden:
- Chargenebene. Wir können den Verlust für alle Triplets im Stapel berechnen und die kleinere Anzahl der Triplets mit dem höchsten Verlust auswählen, um die vollständige Backpropagation durchzuführen.
- Ebene der Epoche. Zu Beginn jeder Trainingsepoche können wir das aktuelle Modell verwenden, um Einbettungen für alle Produkte und Abfragen zu erstellen, die in der aktuellen Epoche enthalten sind, und für jedes Paar aus Anker und Positiv die „nächstgelegenen“ Negative für die Back-Propagation finden. In der nächsten Epoche wird der Prozess mit einem aktualisierten Modell wiederholt.
In der Praxis beschleunigt das Mining von harten Negativen das Modelltraining erheblich und verbessert die Qualität des trainierten Modells.
Das Modell auswerten
Der letzte Schritt bei der Modellschulung ist die Modellbewertung. Nachdem das Training abgeschlossen ist, hat das Modell seine Verlustfunktion optimiert, aber es bleibt abzuwarten, wie diese Verlustfunktion unserem Ziel, relevante Ergebnisse zu erzielen, entspricht.
Dem klassischen Ansatz folgend, teilen wir die Trainings- und Validierungsmenge während der Vorverarbeitungsphase auf und verwenden sie getrennt. Es ist wichtig, eine Trennung auf der Abfrageebene vorzunehmen, um unvollständige Relevanzdaten und vor allem ein Datenleck zu vermeiden.
Wir berechnen den Verlust für das Validierungsset einmal pro Epoche, vor allem, um das Modell auf Überanpassung zu überprüfen.
Vor allem werden wir eine Reihe von Metriken für die Suchqualität verwenden, die während des Trainingsprozesses berechnet werden können und die Qualität des Modells anhand der Relevanzbeurteilung aus den Clickstream-Daten messen.
Hier ist eine kurze Liste der nützlichsten Metriken:
- Recall@K – wichtige Suchmetrik, die den Anteil der relevanten Produkte angibt, die aus den ersten K Suchergebnissen abgerufen wurden.
- NDCG – Normalized Discounted Cumulative Gain (Normalisierter diskontierter kumulativer Gewinn) – eine wichtige Kennzahl für die Qualität des Rankings.
- MRR – Mean reciprocal rank – Ranking-Metrik mit Fokus auf die Position des ersten relevanten Produkts.
Denken Sie daran, dass die Retrieval-Metriken hier am wichtigsten sind, da unser Retrieval-Modell als das erste Modell in der Suchrelevanzkette angesehen werden kann. Es sollte sich vor allem um einen guten Produktabgleich kümmern. Im weiteren Verlauf können LTR- oder Post-Ranking-Modelle übernehmen und die Top-Ergebnisse neu ranken und die NDCG- und MRR-Metriken weiter verbessern.
Um eine Modellbewertung anhand dieser Metriken durchzuführen, sollten wir einen Suchindex auf der Grundlage des aktuellen Modells haben. Alle Produkte sollten mit dem aktuellen Modell vektorisiert werden und die ANN-Suche wird für jede Bewertungsanfrage durchgeführt. Positive Proben für eine bestimmte Abfrage werden zur Berechnung der Relevanzmetriken verwendet. Der Bewertungsindex muss am Ende jeder Trainingsepoche neu erstellt werden.
Der High-Fidelity-Ansatz würde darin bestehen, einen Index aus allen Produkten zu erstellen, so dass die Bewertung den realen Szenarien sehr nahe kommt. Das ist ziemlich kostspielig. Eine praktischere Lösung ist daher die Bewertung der Metriken anhand des Indexes, der nur auf dem Validierungssatz basiert. Am Ende des Trainings kann eine vollständige Bewertung durchgeführt und mit den Zwischenergebnissen des Trainings verglichen werden.
Das Modelltraining sollte aufhören, wenn wir keine sinnvollen Verbesserungen bei den Bewertungsmetriken mehr sehen.
Möchten Sie noch mehr über dieses Thema erfahren? Hören Sie sich die Grid Dynamics-Präsentation von unserer jüngsten virtuellen Veranstaltung ACTIVATE 2022 an:
