Verbinden Sie Suche und KI mit der Integration des Data Science Toolkit von Fusion
Für Datenwissenschaftler und Suchingenieure kann es harte Arbeit sein, zusammenzuarbeiten und synchron zu bleiben. Unternehmen verlassen sich zunehmend auf Datenwissenschaftler und maschinelles Lernen, um ein hyper-personalisiertes Erlebnis zu schaffen, das die Erwartungen der Nutzer erfüllt und das Engagement erhöht. Der Prozess der Optimierung dieser Algorithmen ist jedoch in der Regel zeitaufwändig und schleppend.
Fusion 5.0 ermöglicht eine einfachere Operationalisierung von Modellen, um die Zeit bis zur Bereitstellung für Datenwissenschaftler zu verkürzen und die Entwickler zu entlasten.
„Die Verbindung von Suche und KI ist eine große Herausforderung und Chance für Unternehmen, die daran arbeiten, ein persönlicheres Nutzererlebnis zu schaffen. Datenwissenschaftler wollen ihre Energie darauf verwenden, bessere Modelle zu entwickeln, während die Suchentwickler vor allem daran interessiert sind, die Relevanz der Suche messbar zu machen. Modelle sind ein Mittel zu diesem Zweck“, erklärt Radu Miclaus, Lucidworks Director of Product, AI and Cloud.
„Diese neue Funktion in Fusion 5.0 macht die Übergabe zwischen diesen beiden Hauptakteuren völlig nahtlos und kollaborativ, ohne dass einer von ihnen aus dem Ruder läuft. Magie entsteht, wenn robuste Modelle direkt in die Suche eingespeist werden können, ohne personalintensive Prozesse.“
Mit Fusion 5.0 sind Datenwissenschaftler nicht mehr darauf angewiesen, dass Entwickler Algorithmen in produktive Systemsprachen (wie Java) übersetzen und umkodieren, bevor sie für die Indizierung und Abfrage bereitgestellt werden können. Sie können weiterhin ihre bevorzugten Tools wie scikit-learn, spaCy und TensorFlow verwenden, um Modelle für ein breites Spektrum von NLP-, maschinellen Lern- und Deep-Learning-Techniken zu entwickeln und diese sofort über einen nativen Python-Konnektor in Fusion bereitzustellen.
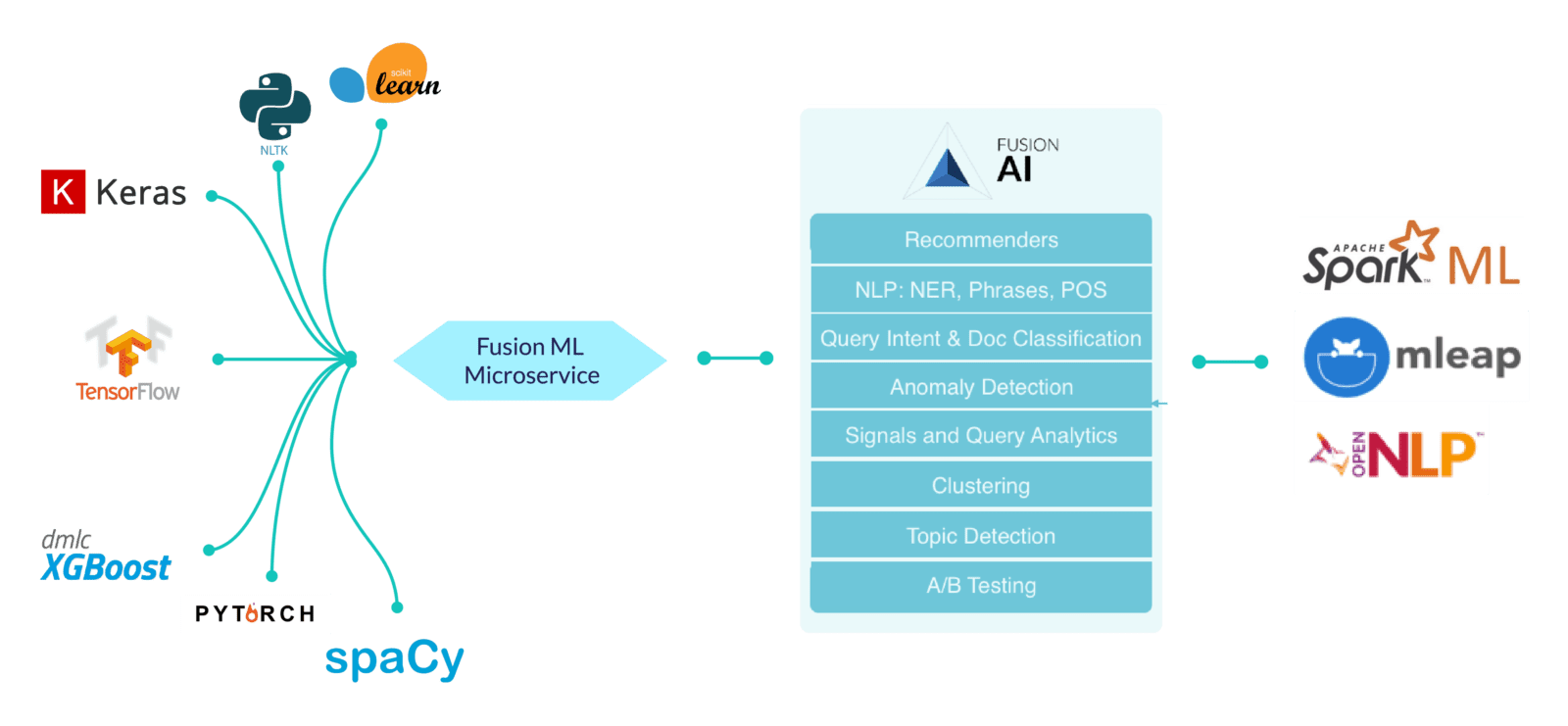
Die cloud-native Architektur von Fusion 5.0, die auf Containern, Microservices und APIs aufbaut, bringt eine neue Dimension der Agilität für Data Science-Aufgaben. Mit dem vielseitigen Python SDK können Modelle direkt von Jupyter Notebook aus trainiert, geändert, getestet und veröffentlicht werden.
Fusion 5.0 bietet die Flexibilität, die Unternehmen für die Entwicklung benötigen, mit der Governance und den Kontrollen, die für Produktionspipelines in Unternehmensqualität erforderlich sind. Durch die Verkürzung der Zeit bis zur Produktion und die tiefere Integration von Data-Science-Aufgaben in die Suchprozesse werden Unternehmen mehr Geschwindigkeit, Skalierbarkeit und Intelligenz bei ihrem Streben nach hochgradig personalisierten Sucherlebnissen für ihre Kunden und Nutzer erreichen.
Interessiert? Erfahren Sie mehr über Fusion 5.0 und sehen Sie sich die Integrationsfunktion des Data Science Toolkits an.