Volltextsuchmaschinen vs. DBMS
Die meisten modernen Suchmaschinen bieten Funktionen wie Speicher- und Datenverarbeitungslogik. Gleichzeitig bieten die meisten Datenbanken irgendeine Art von textbasierter Suche an, aber die Fähigkeit einer Datenbank, Relevanz zu liefern, ist entweder nicht vorhanden oder ein nachträglicher Einfall.
Für einige Anwendungen ist natürlich die eine oder andere Technologie am besten geeignet. Einige Anwendungen beginnen vielleicht mit einer relationalen Datenbank als Kernstück, aber wenn das Datenvolumen oder die Benutzerzahl wachsen, kann es sein, dass die Bedürfnisse der Benutzer durch die Migration auf ein Volltextsuchsystem besser erfüllt werden. Viele Anwendungen nutzen beide Technologien im Tandem, entweder für verschiedene Teile der Daten oder durch Duplizieren einiger Daten in den beiden Systemen, um die Vorteile beider Systeme zu nutzen.
Lassen Sie uns einen Blick auf die Vorteile von Volltextsuchsystemen im Vergleich zu einer relationalen Datenbank (RDMS) werfen.
Vergleich von Volltextsuchmaschinen und relationalen Datenbanken
Volltextsysteme eignen sich besser für die schnelle Suche in großen Mengen von unstrukturiertem, halbstrukturiertem oder strukturiertem Text nach einem bestimmten Wort oder bestimmten Wörtern. Sie bieten Funktionen für die Volltextsuche und ein ausgeklügeltes Relevanz-Ranking, mit dem Sie die Ergebnisse danach ordnen können, wie gut sie einer potenziell „unscharfen“ Suchanfrage entsprechen (Wörter, die nicht ganz übereinstimmen, wie Tippfehler oder Homonyme).
Diese Systeme bieten auch verschiedene Formen der Verarbeitung natürlicher Sprache, um die Absicht des Benutzers zu verstehen, und verfügen über starke Empfehlungsalgorithmen. Diese Fähigkeiten ermöglichen es den Suchsystemen, ein viel intuitiveres, personalisiertes Erlebnis für den Benutzer zu bieten.
Relationale Datenbanken hingegen eignen sich hervorragend zum Speichern und Bearbeiten strukturierter Daten – alles, was in einem Tabellenformat mit Zeilen und Spalten vorliegt. Sie unterstützen die flexible Suche in mehreren Datensatztypen nach bestimmten Werten in bestimmten Feldern und eignen sich hervorragend für die schnelle und sichere Aktualisierung bestimmter einzelner Datensätze.
Einige der Felder in den Datensätzen einer Datenbank können Freitext sein (wie eine Produktbeschreibung). Die meisten relationalen Datenbanken bieten Unterstützung für die Stichwortsuche in diesen unstrukturierten Feldern.
Aber die Relevanzeinstufung der Ergebnisse aus einer Datenbank hat nicht die gleiche Qualität oder Ausgereiftheit wie die besten Volltextsuchsysteme. Und wenn der Datenbankadministrator (DBA) nicht weiß, welche Fragen der Benutzer stellen wird, ist die Leistung eines RDBMS ziemlich langsam und bietet ein schlechtes Benutzererlebnis.
Wenn der DBA weiß, dass die Benutzer bestimmte Arten von Fragen stellen werden, kann er die Datenbank/Tabellen so gestalten, dass sie bessere Ergebnisse liefern. Wenn sich jedoch die Anforderungen der Benutzer ändern und weiterentwickeln, kann der DBA mit diesen Änderungen nicht mehr Schritt halten und die Benutzer beginnen, die Abfragemechanismen von RDBMS zu verlassen.
Lassen Sie uns tiefer in die Details eintauchen:
Was Volltextsuchmaschinen gut können
Volltextsuchsysteme zeichnen sich durch die schnelle und effiziente Suche in großen Textmengen aus. Dazu können unstrukturierte Daten wie ein Word-Dokument oder halbstrukturierte Inhalte wie HTML-Webseiten gehören, die zwar eine gewisse Struktur und Metadaten, aber hauptsächlich eine Fülle von Text enthalten.
Sie können diese Informationen auch auf der Grundlage bestimmter Werte innerhalb der Daten kategorisieren (alphabetisch, Preisspanne, Region, Farbe, Größe, Dateityp, Autor). Die Textsuchfunktionen der besten Systeme sind reichhaltig und flexibel und umfassen Unterstützung für die Suche nach grundlegenden Schlüsselwörtern, eine Google-ähnliche +/- Syntax, altmodische boolesche Operatoren, Verarbeitung natürlicher Sprache, Proximity-Operationen, Funktionen zur Suche nach Ähnlichkeiten und andere Funktionen.
Volltextsuchmaschinen verfügen auch über Funktionen zur Ermittlung der Relevanz, um die beste Übereinstimmung für eine Suchanfrage zu bestimmen. Diese Berechnungen berücksichtigen unter anderem die Häufigkeit der Suchbegriffe im Dokument, ihre Häufigkeit im gesamten Korpus und die Nähe zueinander in einem Dokument.
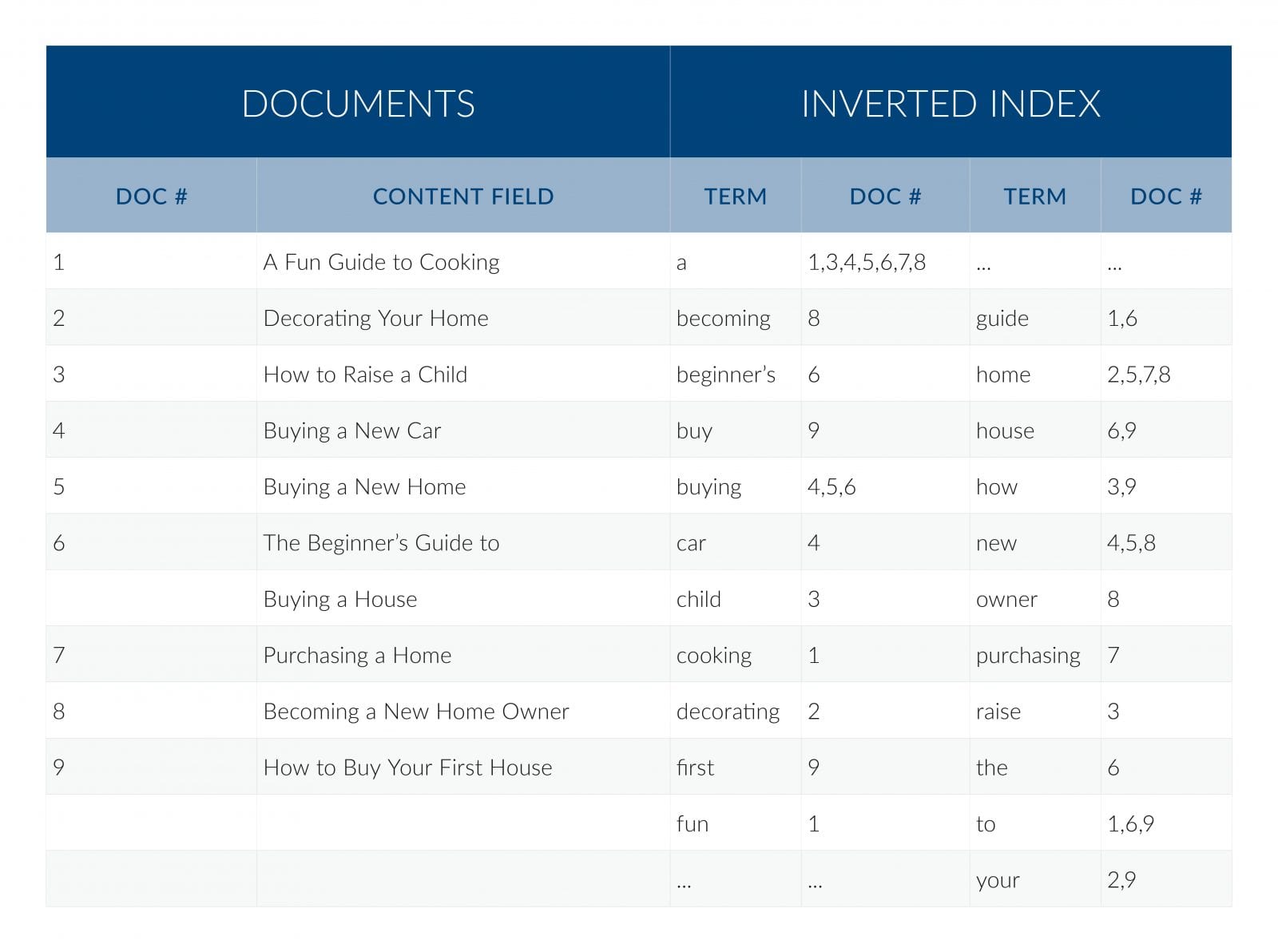
Volltextsuchsysteme stützen sich auf einen Index, um Abfragen durchführen zu können. Der gebräuchlichste Index ist ein invertierter Index, der jeden Begriff – jedes Wort, jede Zahl usw. – in jedem Dokument zählt und angibt, in welchen Dokumenten dieser Begriff enthalten ist und wo er in den Dokumenten vorkommt.
Es kann einen separaten Index für jedes Feld geben, oder alle Felder können in einem einzigen Index enthalten sein. Das System enthält in der Regel Funktionen für die Bearbeitung von Nicht-Textfeldern, wie die Suche nach numerischen Bereichen – insbesondere wenn diese Bereiche im Text vorkommen -, die Möglichkeit, Ergebnisse nach beliebigen Feldern zu sortieren usw., aber diese Funktionen müssen in der Regel in den Dokumenten selbst gefunden werden und werden in der Regel nicht in Echtzeit vom Suchsystem berechnet.
Zusätzlich zur Indizierung der Daten können die meisten Volltextsuchmaschinen die Daten in ihrer ursprünglichen Form speichern und abrufen. Ein Grund dafür ist, dass eine Suchergebnisliste leicht mit tatsächlichen Daten aus den aufgelisteten Dokumenten aufgefüllt werden kann, so dass sich die Benutzer ein besseres Bild von einem Dokument machen können, bevor sie es anklicken, um es zu sehen. Diese Systeme unterstützen auch die inkrementelle Indizierung und die Möglichkeit, einzelne Datensätze hinzuzufügen, zu löschen oder zu aktualisieren.
Suchsysteme sind jedoch nur begrenzt in der Lage, Transaktionsaktualisierungen im Stil von Datenbanken im traditionellen Indexprozess schnell und sicher zu verarbeiten. Sie mussten sich darauf einstellen, dass Änderungen in den Index „gepusht“ werden, anstatt sich auf opportunistische inkrementelle Aktualisierungen des Index zu verlassen. Diese Änderungen, die nahezu in Echtzeit erfolgen, ermöglichen es, dem Benutzer komplexe Produktinformationen anzuzeigen, wie z.B. die Verfügbarkeit von Waren in seinem Geschäft.
Suchsysteme verlassen sich nicht ausschließlich auf Text, der in den Index „eingelesen“ wurde, um die Relevanz zu messen. Sie können sich auch auf KI-Modelle stützen, um die Relevanz für Benutzeranfragen zu beeinflussen. Einzelne Benutzerinteraktionen (Klicks, Aufrufe, Abfragen, Hinzufügen zum Warenkorb – auch Signale genannt) werden aggregiert und in das System zurückgeführt, um relevantere Ergebnisse und ein besseres Benutzererlebnis zu bieten. Diese Personalisierungstechniken, die zuerst in der Welt des Handels eingeführt wurden, halten nun Einzug in den digitalen Arbeitsplatz, um die Produktivität zu steigern und bessere Empfehlungen zu geben.

Ein weiteres Markenzeichen von Suchsystemen ist die Fähigkeit, Daten aus vielen verschiedenen Datenquellen zu indizieren. Der Index kann Daten aus Dateisystemen, Webservern, CRM-Systemen, Datenbanken und vielen anderen Informationsquellen enthalten. Eine Benutzerabfrage kann nach Informationen in allen diesen Systemen suchen und ihnen nur die Dokumente anzeigen, die sie aufgrund ihrer Berechtigungen und Sicherheitsprivilegien sehen dürfen.
Die Möglichkeiten von Volltextsuchsystemen lassen sich wie folgt zusammenfassen:
- Suchantworten in Sekundenschnelle bei der Suche in Millionen, möglicherweise Milliarden von Dokumenten, die einen oder mehrere Begriffe enthalten. Dies umfasst die Suche in Textfeldern und etwas eingeschränktere Möglichkeiten zur Suche in Nicht-Text-Daten. Dazu gehört auch eine effiziente Facettierung oder Kategorisierung von Inhalten oder Suchergebnissen auf der Grundlage bestimmter Werte in bestimmten Feldern.
- Umfangreiche und flexible Textabfragetools und ausgefeilte Ranking-Funktionen zum Auffinden der besten Dokumente und Datensätze.
- Empfehlungen von Inhalten und Experten, um Benutzer zu den Ergebnissen zu führen, die für ihre Anfrage am aussagekräftigsten sind
- Relevanzsteigerung in Echtzeit auf der Grundlage früherer Interaktionen, Abfragen und des Verhaltens anderer Nutzer.
- Funktionen zum Hinzufügen, Löschen oder Aktualisieren von Dokumenten und Datensätzen.
- Grundlegende Funktionen für die Speicherung der Daten, die über die einfache Indizierung und Suche hinausgehen.
- Begrenzte Möglichkeiten für die Suche und Bearbeitung von Daten, die tatsächlich verschiedene Datensatztypen darstellen.
Wann Sie eine Volltextsuchmaschine in Ihrer Anwendung verwenden sollten
Die Anwendungsanforderungen, die dafür sprechen, ein Volltextsuchsystem einer relationalen Datenbank vorzuziehen:
- Die Anwendung wird eine große Menge an hauptsächlich textlichen Informationen indizieren.
Alle möglichen Benutzerinteraktionen und Abfragen können nicht im Voraus angenommen werden und können sich im Laufe der Zeit ändern. - Abfragen können mehrere Systeme und Quellenspeicher umfassen (Dateisysteme, Webserver, CRM, Datenbanken usw.)
- Es wird ein hohes Volumen an Abfragen an das System übermittelt werden.
- Die Anwendung muss eine hochflexible Volltextsuche unterstützen.
- Optimale Relevanz wurde oder kann mit der bestehenden relationalen Datenbanktechnologie nicht erreicht werden.
- Ein anpassungsfähiges Benutzererlebnis ist eine der wichtigsten geschäftlichen Anforderungen.
Verschieben einer App von einer Datenbankarchitektur zur Suche
Die obige Liste enthält einige Gründe für die Wahl eines Volltextsuchsystems zu Beginn eines Projekts. Aber sie kann auch dafür sprechen, eine bestehende Anwendung von einer Datenbank auf ein Volltextsystem zu migrieren.
Eine Datenbank mag bei der Entwicklung einer Anwendung gut geeignet gewesen sein, aber im Laufe der Zeit kann es zu Leistungseinbußen kommen. Das Wachstum des Datenvolumens, der Abfragen oder der Benutzer kann die Leistung beeinträchtigen. In anderen Fällen liegt dies daran, dass die ursprüngliche Entscheidung für eine relationale Datenbank weniger wegen der tatsächlichen Anforderungen an eine „relationale“ (mehrere Tabellen) oder „Datenbankverwaltung“ (Transaktionsverarbeitung) getroffen wurde, sondern eher, weil das Team mit der Datenbankarchitektur und ihren Konventionen besser vertraut war.
Ein Volltextsuchsystem kann ein effektiveres Werkzeug sein, wenn die Daten aus mehreren Tabellen in ein einziges Datensatzformat ‚geglättet‘ werden, das für Volltextoperationen geeignet ist. Dies ist vor allem dann sinnvoll, wenn es nur eine oder eine Handvoll Tabellen gibt und nur begrenzte Anforderungen an eine umfangreiche Transaktionsverarbeitung oder Wiederherstellung bestehen.
In manchen Fällen müssen die Daten aufgrund technischer Anforderungen in der relationalen Datenbank verbleiben, auch wenn die Suche in der Datenbank nicht ausreicht. In diesen Fällen kann die Datenbank indiziert werden, so dass sie über das Volltextsystem durchsuchbar ist.
Zusammenfassung
Suchtechnologien eignen sich hervorragend für die Hochgeschwindigkeitssuche und Facettierung großer Datenmengen. Sie sind nicht so stark in der Handhabung von Multi-Datensatz-Typen oder der Transaktionsverarbeitung wie relationale Datenbanken. Aber die Flexibilität, die ein modernes Suchsystem bietet, ist in den meisten Situationen mehr als ausreichend und oft die einzige Lösung für benutzerintensive Anwendungen.
Viele ältere DBMS-basierte Anwendungen wurden aus Gründen der Bequemlichkeit und der Vertrautheit der Entwickler mit Datenbanken entwickelt, und weniger, weil die Anwendung am besten für die Fähigkeiten einer Datenbank geeignet ist. Viele Anwendungen können migriert und mit einem Suchsystem betrieben werden, wenn das DBMS nicht mehr den Anforderungen der Benutzer oder des Geschäftsinhabers entspricht.
Andere Anwendungen können teilweise in Suchsysteme migriert werden , um die besonderen Suchanforderungen des Projekts zu unterstützen. Weitere Daten können gleichzeitig in beiden Systemen verwendet werden, um die Vorteile jedes dieser nativen Systeme zu nutzen.