Vorläufige Datenanalyse mit Fusion
Lucidworks Fusion ist die Plattform für Suche und Data Engineering. Im Artikel Search Basics for Data Engineers habe ich die Kernfunktionen von Lucidworks Fusion 2 vorgestellt und einige Blogbeiträge aus dem Lucidworks-Blog damit indiziert, so dass eine durchsuchbare Sammlung entstanden ist. Hier sehen Sie das Ergebnis einer Suche nach Blogbeiträgen über Fusion:
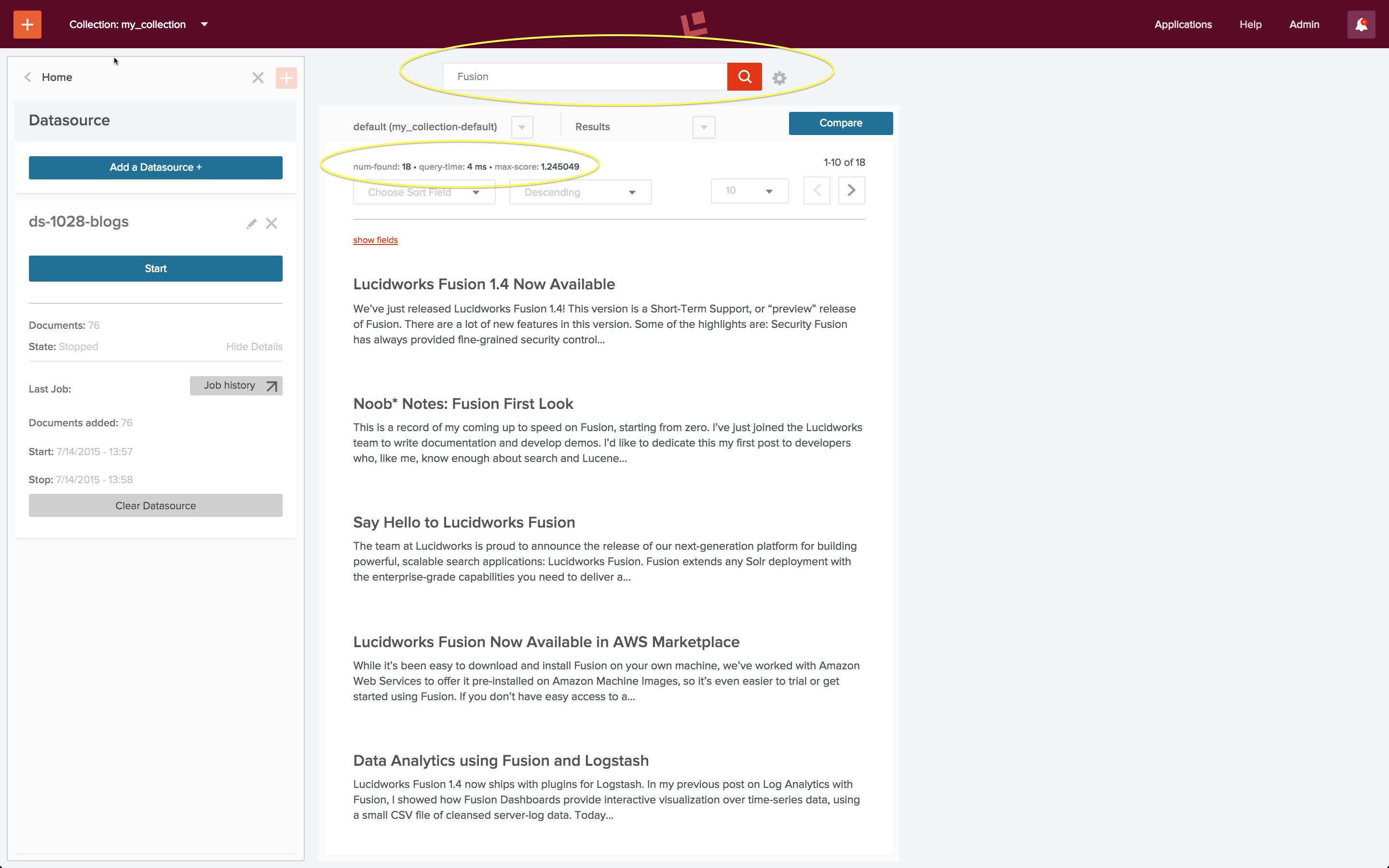
Das Bootstrapping einer Suchanwendung erfordert einen ersten Indizierungslauf über Ihre Daten, gefolgt von aufeinanderfolgenden Such- und Indizierungszyklen, bis Ihre Anwendung das tut, was Sie wollen und was die Suchbenutzer von ihr erwarten. Die obigen Suchergebnisse erforderten eine Iteration dieses Prozesses. In diesem Artikel gehe ich auf die Indizierungs- und Abfragekonfigurationen ein, mit denen dieses Ergebnis erzielt wurde.
Siehe
Die Indizierung von Webdaten ist eine Herausforderung, denn was Sie sehen, ist nicht immer das, was Sie bekommen. Das heißt, wenn Sie eine Webseite in einem Browser betrachten, lenken das Layout und die Formatierung Ihr Auge und machen wichtige Informationen deutlicher sichtbar. Hier sehen Sie, wie ein aktueller Blogeintrag von Lucidworks in meinem Browser aussieht:
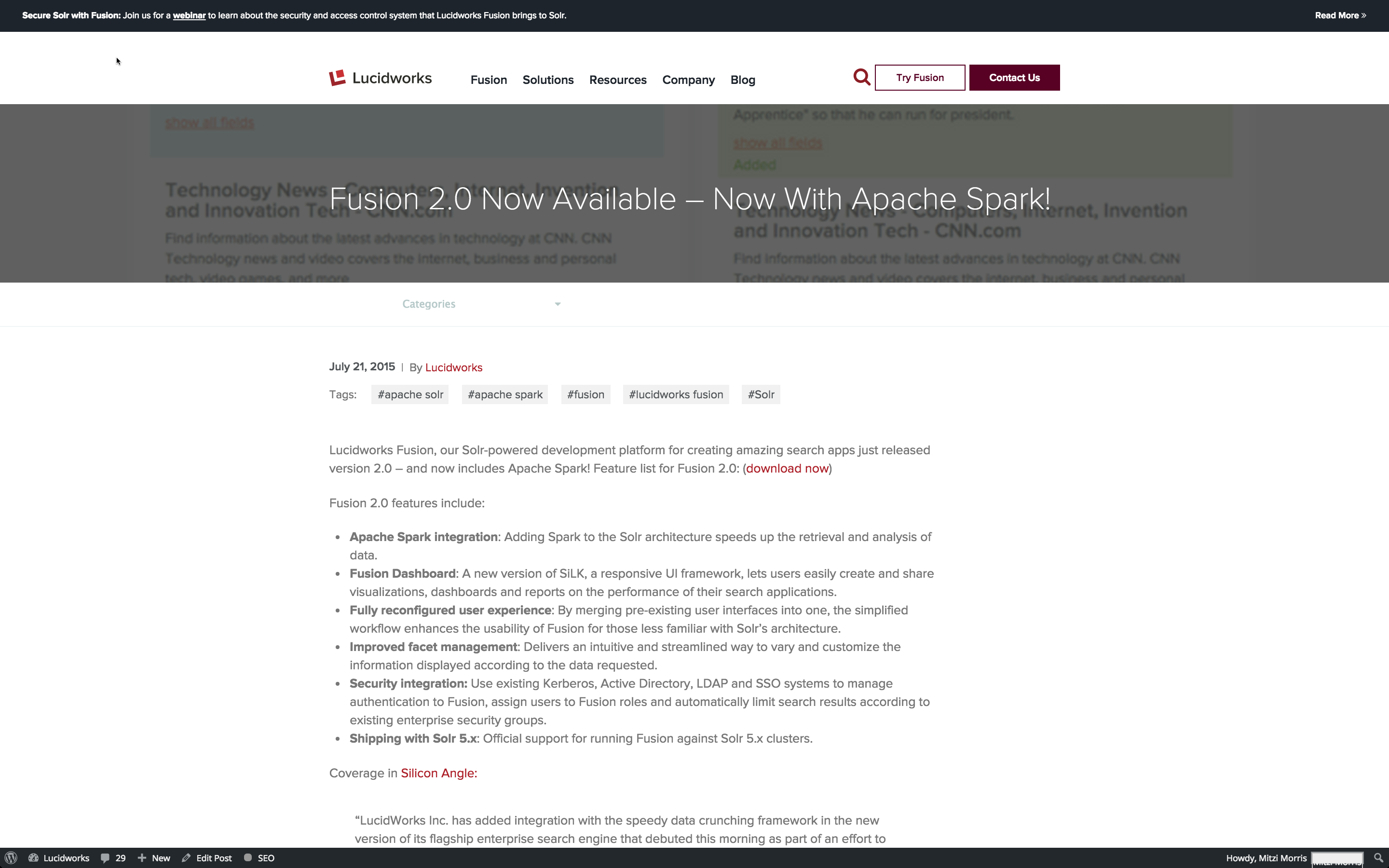
Oben auf der Seite befinden sich Navigationselemente, aber das auffälligste Element ist der Titel des Blogbeitrags, gefolgt von den Elementen darunter: Datum, Autor, Eröffnungssatz und die erste sichtbare Abschnittsüberschrift darunter.
Ich möchte, dass meine Suchanwendung in der Lage ist, zu unterscheiden, welche Informationen von welchem Element stammen, und dass ich meine Suche entsprechend abstimmen kann. Ich könnte einen oder mehrere Blog-Einträge von Hand analysieren oder Fusion verwenden, um eine ganze Reihe von Einträgen zu indizieren; ich entscheide mich für letzteres.
Springen
Vorkonfigurierte Standard-Pipelines
Für die erste Iteration verwende ich die Fusion-Standardeinstellungen für Suche und Indizierung. Ich erstelle eine Sammlung „lw_blogs“ und konfiguriere eine Datenquelle „lw_blogs_ds_default“. Der Zugriff auf die Website erfordert die Verwendung der Anda-web-Datenquelle, und diese Datenquelle ist so vorkonfiguriert, dass sie die Indexpipeline „Documents_Parsing“ verwendet.
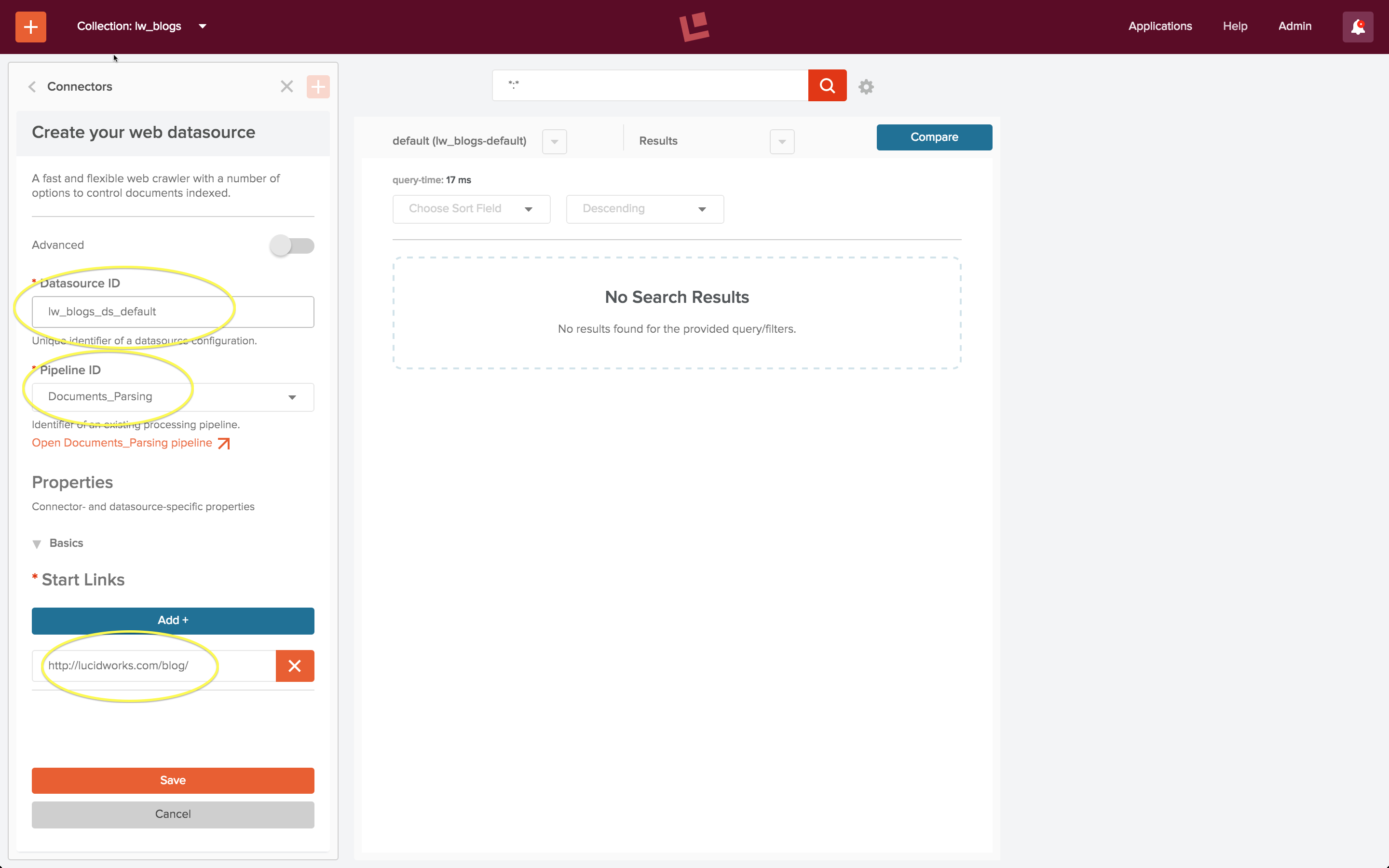
Ich starte den Auftrag, lasse ihn ein paar Minuten lang laufen und beende dann das Web Crawling. Das Suchfeld ist mit einer Platzhaltersuche unter Verwendung der Standardabfrage-Pipeline vorbelegt. Wenn Sie diese Suche ausführen, erhalten Sie das folgende Ergebnis:
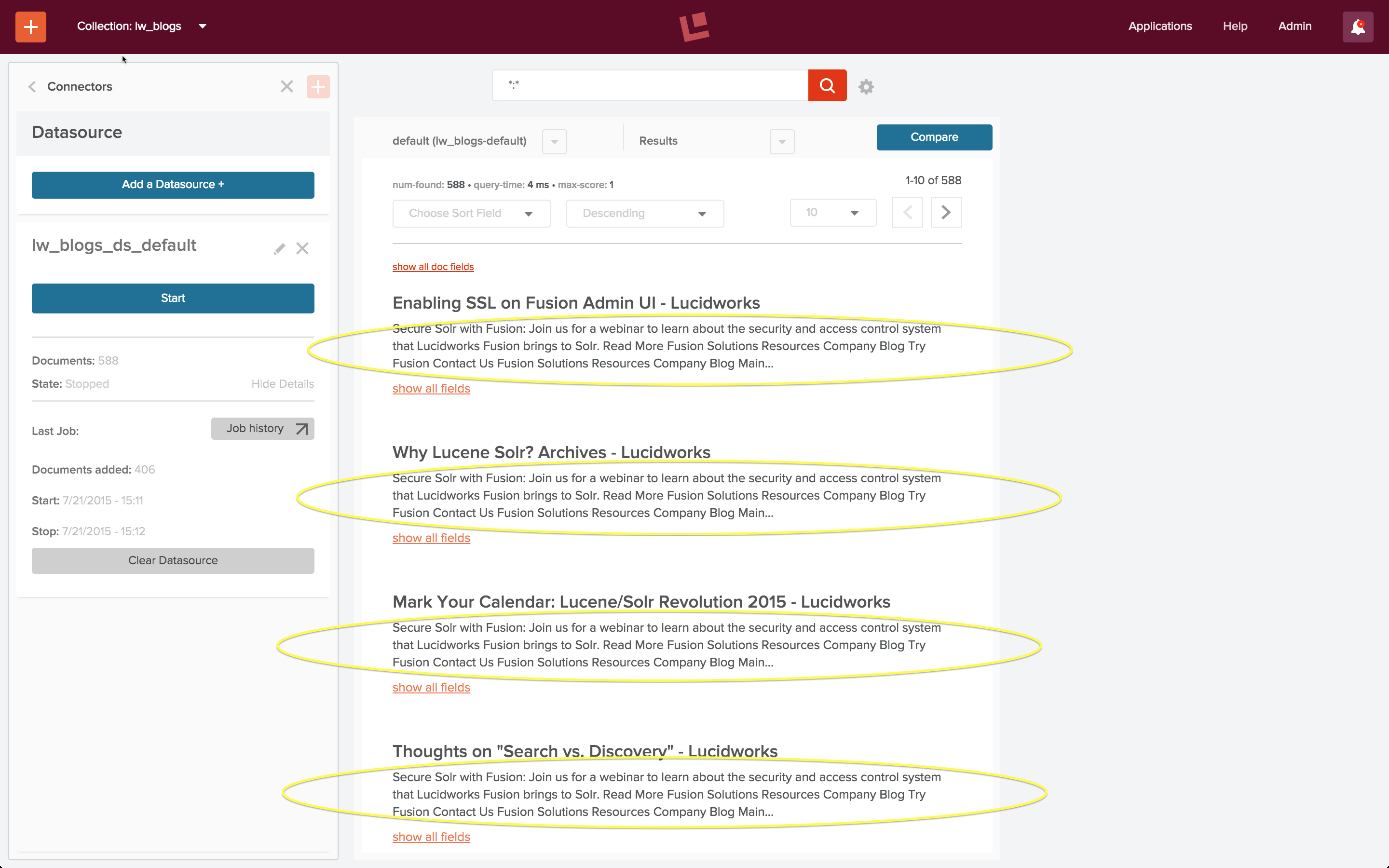
Auf den ersten Blick sieht es so aus, als ob alle Dokumente im Index denselben Text enthalten, obwohl sie unterschiedliche Titel haben. Eine genauere Betrachtung des Inhalts der einzelnen Dokumente zeigt, dass dies nicht der Fall ist. Ich verwende das Steuerelement „Alle Felder anzeigen“ im Suchergebnisfenster und untersuche den Inhalt des Feldes „Inhalt“:
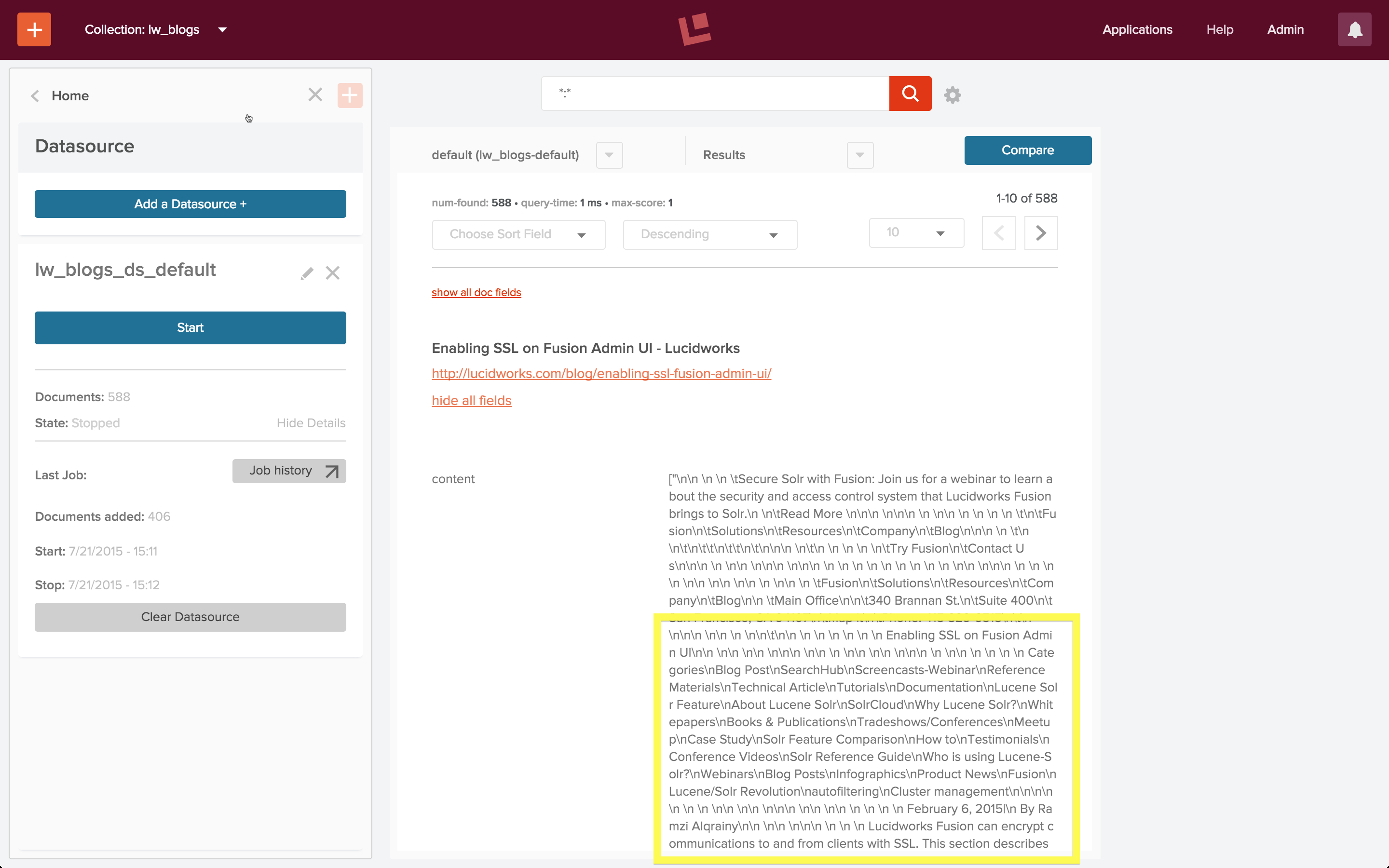
Wenn Sie sich dieses Feld genauer ansehen, sehen Sie, dass der Inhalt tatsächlich dem Titel des Blogbeitrags entspricht und dass der gesamte Text im Textkörper der HTML-Seite vorhanden ist. Der Apache Tika-Parser hat den Text aus allen Elementen im Textkörper der HTML-Seite extrahiert und ihn in das Feld „Inhalt“ des Dokuments eingefügt, einschließlich aller Leerzeichen zwischen und um verschachtelte Elemente, und zwar in der Reihenfolge, in der sie auf der Seite vorkommen. Da alle Blogeinträge oben ein Banner und eine Reihe gemeinsamer Navigationselemente enthalten, haben sie alle den gleichen Einleitungstext:
nn n n tSecure Solr with Fusion: Join us for a webinar to learn about the security and access control system that Lucidworks Fusion brings to Solr.n ntRead More nnn nnn n nn n n n n tntFusionn ...
Diese erste Iteration zeigt mir, was in den Daten vor sich geht, aber sie erfüllt nicht die Anforderung, zu unterscheiden, welche Informationen von welchem Element stammen, was zu schlechten Suchergebnissen führt.
Wiederholen Sie
Benutzerdefinierte Index-Pipeline
In der ersten Iteration wurde die Pipeline „Documents_Parsing“ verwendet, die aus den folgenden Schritten besteht:
- Apache Tika Parser – erkennt und parst die meisten gängigen Dokumentformate, einschließlich HTML
- Field Mapper – wandelt bei Bedarf Feldnamen in gültige Solr-Feldnamen um
- Spracherkennung – wandelt Textfeldnamen basierend auf der Sprache des Feldinhalts um
- Solr Indexer – wandelt ein Dokument aus der Fusion-Index-Pipeline in ein Solr-Dokument um und fügt es der Sammlung hinzu (oder aktualisiert es).
Um den Text eines bestimmten HTML-Elements zu erfassen, muss ich eine HTML-Transformationsstufe zu meiner Pipeline hinzufügen. Ich brauche immer noch einen Apache Tika-Parser als erste Stufe in meiner Pipeline, um die rohen Bytes, die der Web-Crawler per HTTP über die Leitung schickt, in ein HTML-Dokument zu verwandeln. Aber anstatt den Tika-HTML-Parser zu verwenden, um den gesamten Text aus dem HTML-Textkörper in ein einziges Feld zu extrahieren, verwende ich die HTML-Transformationsstufe, um Elemente von Interesse jeweils in ein eigenes Feld zu übertragen. Für einen ersten Schnitt der Daten verwende ich nur zwei Felder: eines für den Blogtitel und das andere für den Blogtext.
Ich erstelle eine zweite Sammlung „lw_blogs2“ und konfiguriere eine weitere Webdatenquelle, „lw_blogs2_ds“. Wenn Fusion eine Sammlung erstellt, wird auch eine Indizierungs- und Abfrage-Pipeline erstellt, wobei die Namenskonvention Sammlungsname plus „-default“ für beide Pipelines verwendet wird. Ich wähle die Index-Pipeline „lw_blogs2-default“ und öffne das Pipeline-Editor-Panel, um diese Pipeline für die Verarbeitung der Lucidworks-Blogbeiträge anzupassen:
Die erste sammlungsspezifische Pipeline ist als „Default_Data“-Pipeline konfiguriert: Sie besteht aus einer Field Mapper-Stufe, gefolgt von einer Solr Indexer-Stufe.
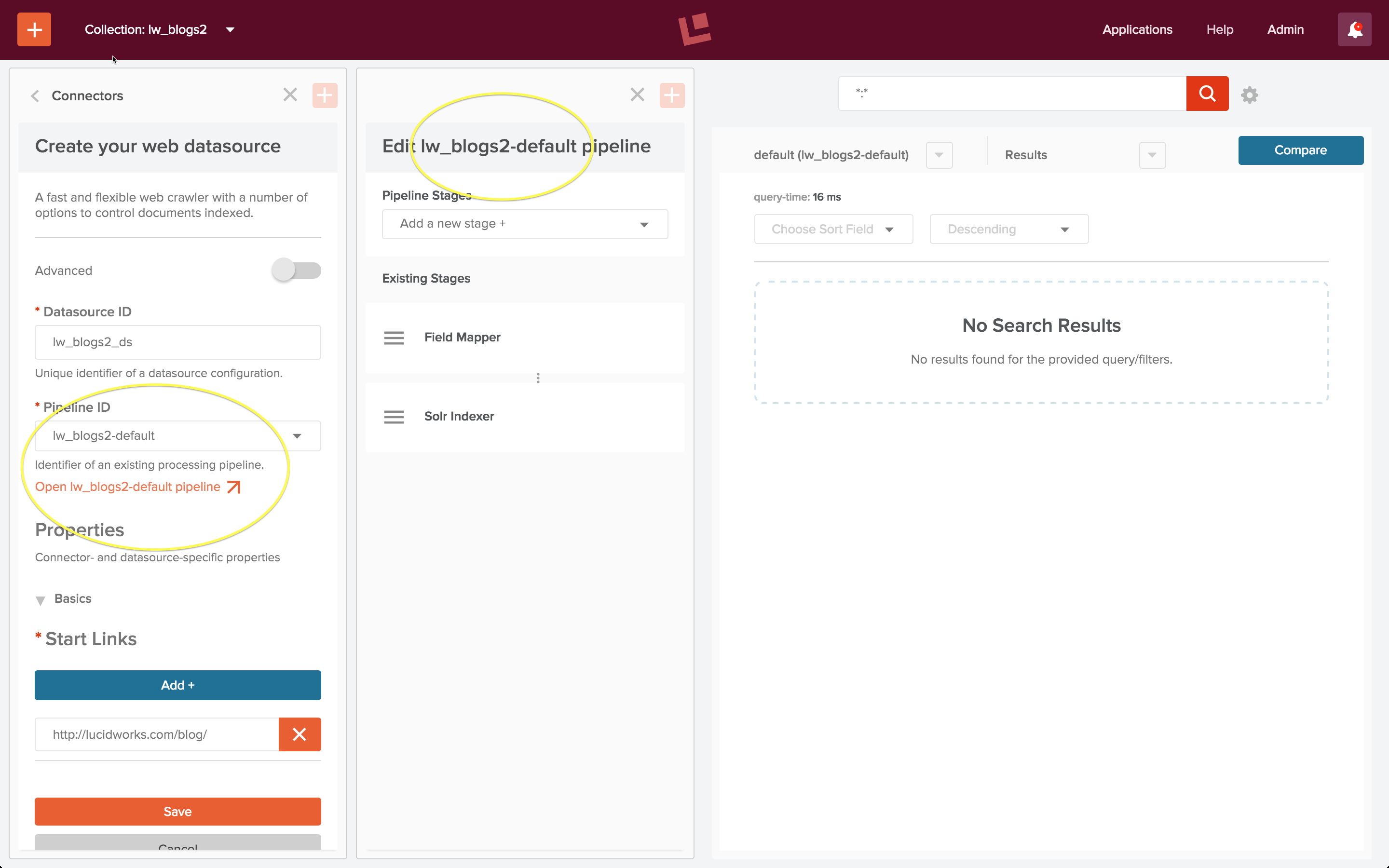
Wenn Sie einer Index-Pipeline neue Stufen hinzufügen, werden diese auf den Stapel der Pipeline-Stufen geschoben. Daher füge ich zuerst eine HTML-Transform-Stufe und dann eine Apache Tika-Parser-Stufe hinzu, so dass eine Pipeline entsteht, die mit einer Apache Tika-Parser-Stufe und einer HTML-Transform-Stufe beginnt. Zunächst bearbeite ich die Apache Tika Parser-Stufe wie folgt:
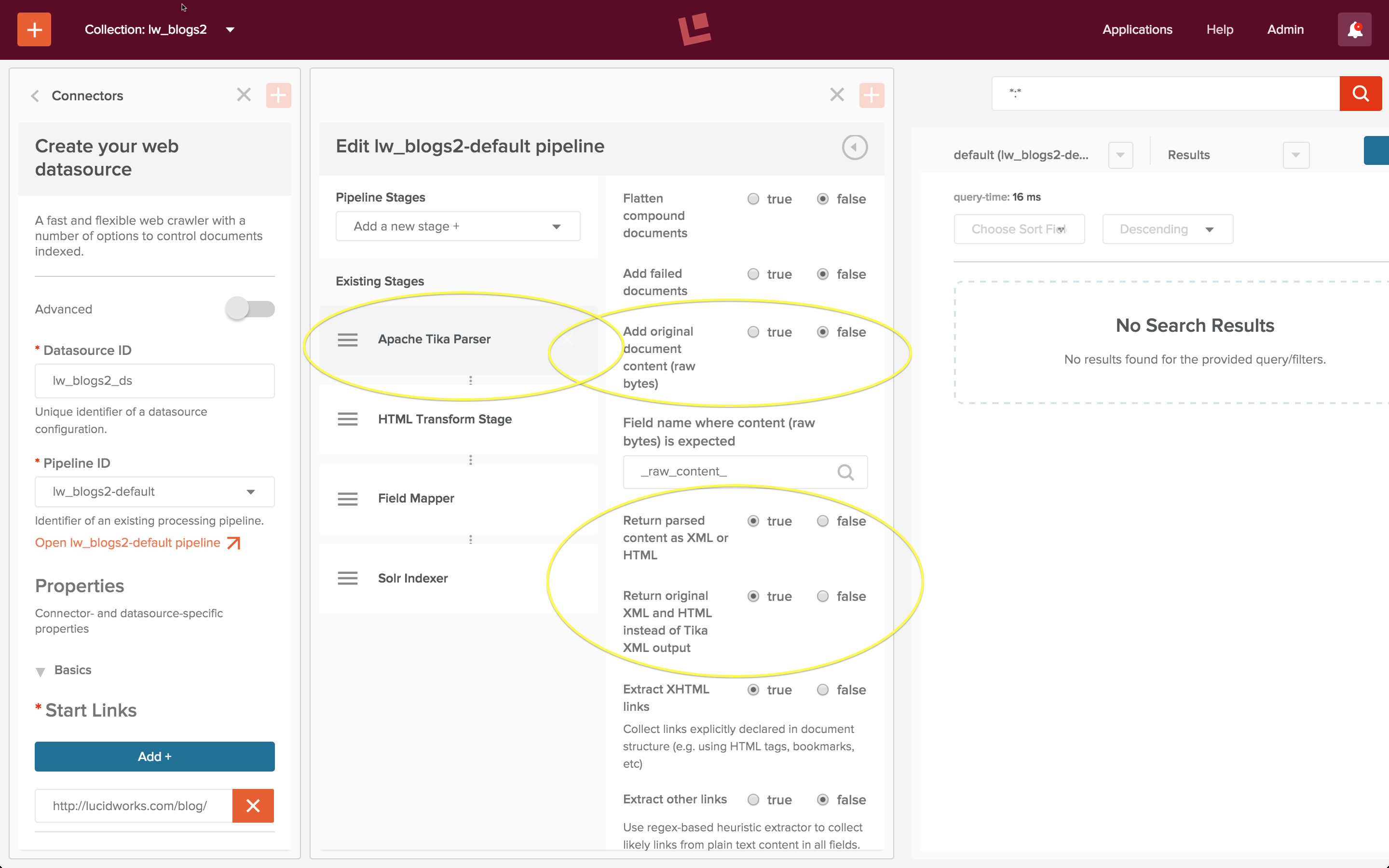
Wenn Sie eine Apache Tika-Parserstufe in Verbindung mit einer HTML- oder XML-Transformationsstufe verwenden, muss die Tika-Stufe konfiguriert werden:
- Option „Originaldokumentinhalt hinzufügen (Rohbytes)“ Einstellung: false
- Option „Geparste Inhalte als XML oder HTML zurückgeben“ Einstellung: true
- Option „Original XML und HTML statt Tika XML-Ausgabe zurückgeben“ Einstellung: true
Mit diesen Einstellungen wandelt Tika die vom Webcrawler abgerufenen Rohbytes in ein HTML-Dokument um. Die nächste Stufe ist eine HTML-Transformationsstufe, die die interessanten Elemete aus dem Textkörper des HTML-Dokuments extrahiert:
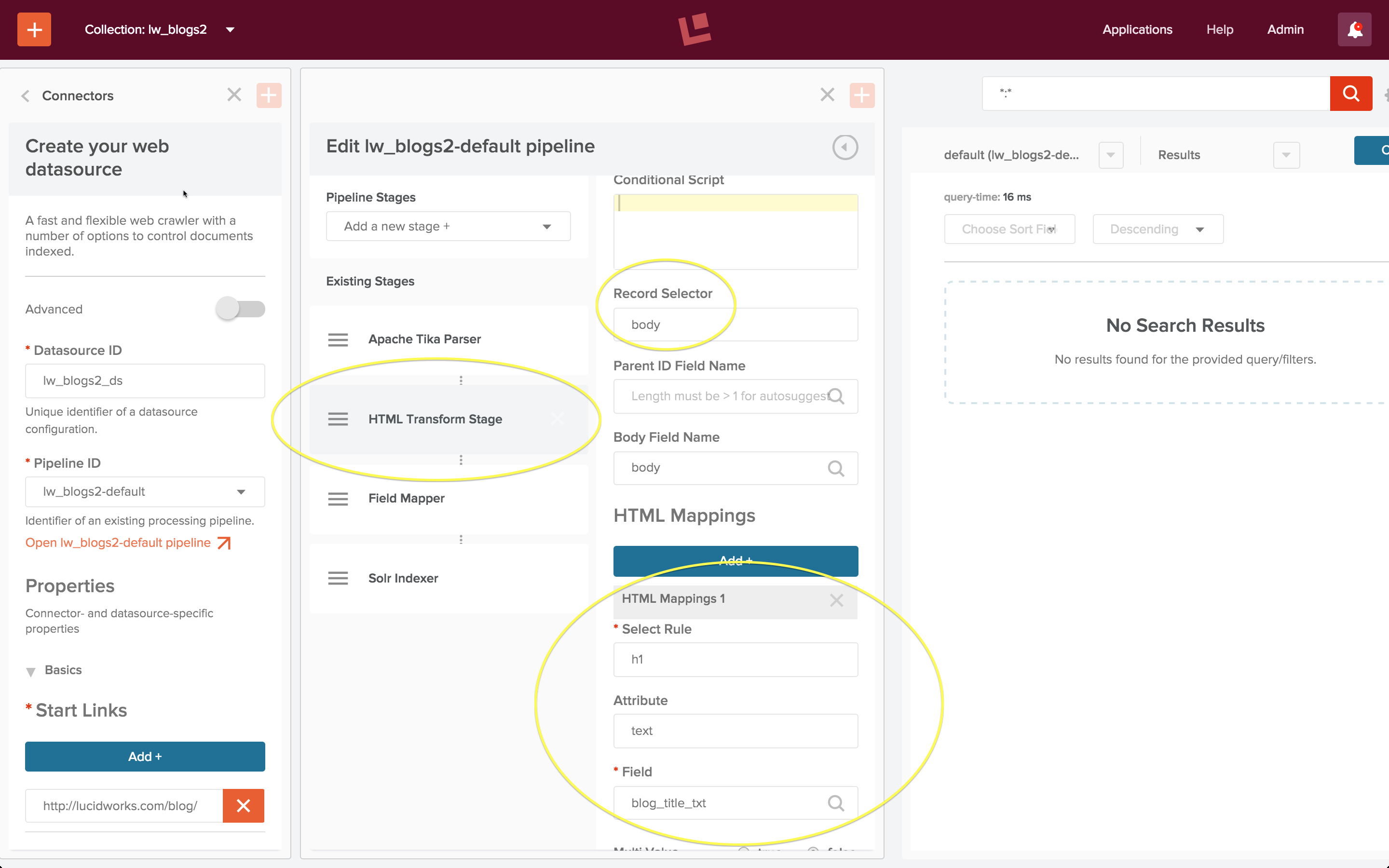
Eine HTML-Transformationsstufe erfordert die folgende Konfiguration:
- Eigenschaft „Record Selector“, die das HTML-Element angibt, das das Dokument enthält.
- HTML Mappings, eine Reihe von Regeln, die festlegen, wie verschiedene HTML-Elemente auf Solr-Dokumentfelder abgebildet werden.
Hier entspricht die „Record Selector“-Eigenschaft „body“ der Standardeinstellung „Body Field Name“, da jeder Blogbeitrag ein einzelnes Solr-Dokument ist. Ein Blick auf das rohe HTML zeigt, dass sich der Titel des Blogposts in einem „h1“-Element befindet. Daher legt die oben gezeigte Zuordnungsregel fest, dass der Textinhalt des Tags „h1“ dem Dokumentfeld mit dem Namen „blog_title_txt“ zugeordnet wird. Der Beitrag selbst befindet sich in einem Tag „article“, so dass die zweite Mapping-Regel, die nicht gezeigt wird, festlegt:
- Regel auswählen: Artikel
- Attribut: Text
- Feld: blog_post_txt
Der Web Crawl hat auch viele Seiten gefunden, die Zusammenfassungen von zehn Blogbeiträgen enthalten, aber keinen Blogbeitrag. Diese Seiten sind uninteressant, daher möchte ich die Indizierung auf Dokumente beschränken, die einen Blogbeitrag enthalten. Dazu füge ich der Solr Indexer-Stufe eine Bedingung hinzu:
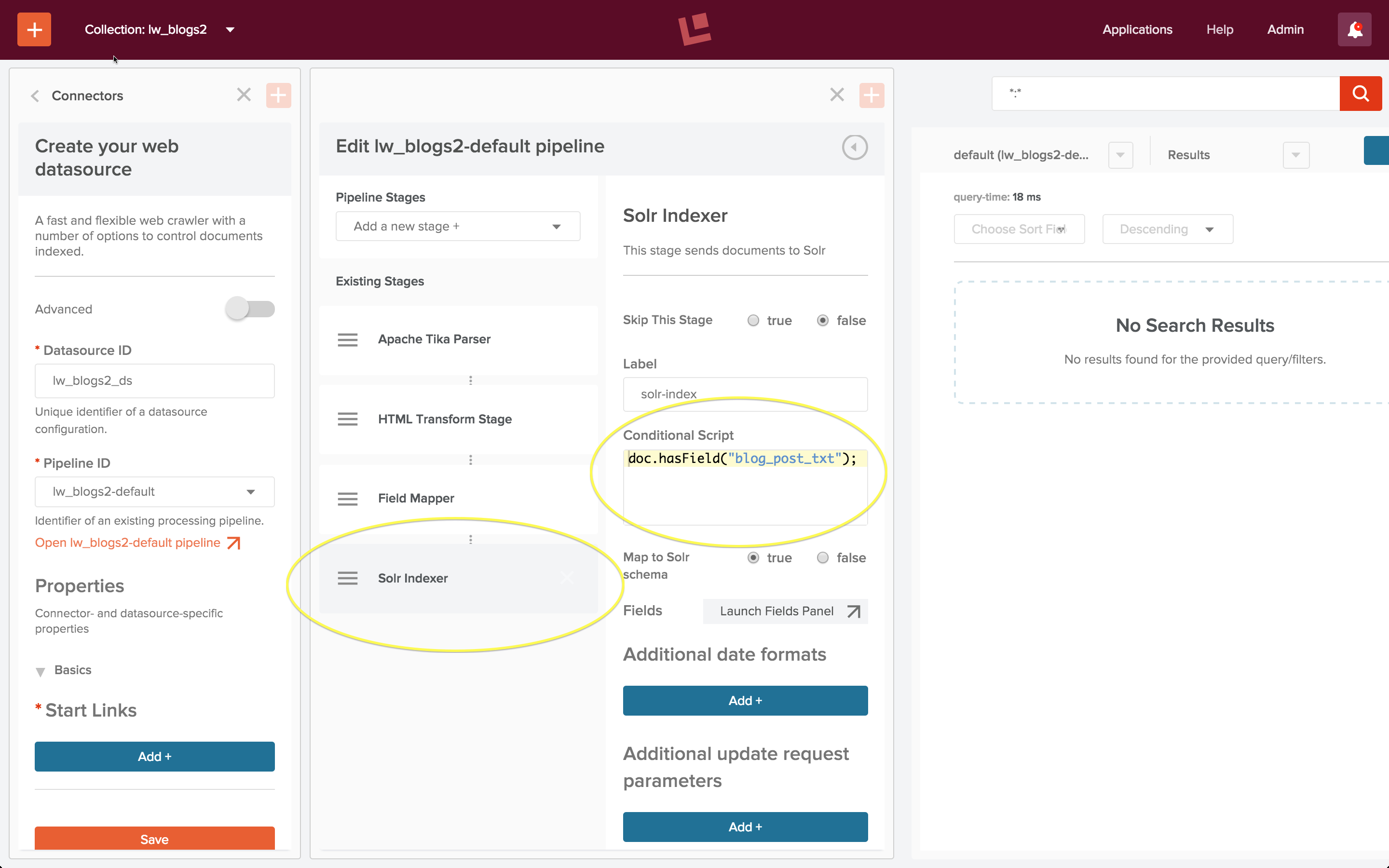
Ich starte den Auftrag, lasse ihn ein paar Minuten laufen und stoppe dann das Web Crawling. Ich führe eine Platzhaltersuche durch, und alles funktioniert!
Benutzerdefinierte Abfrage-Pipeline
Um die Suche zu testen, führe ich eine Abfrage nach den Wörtern „Fusion Spark“ durch. Meine erste Suche liefert keine Ergebnisse. Ich weiß, dass dies falsch ist, denn in den Artikeln, die von der obigen Wildcard-Suche zurückgegeben werden, werden sowohl Fusion als auch Spark erwähnt.
Der Grund für diesen offensichtlichen Fehler ist, dass die Suche über Dokumentfelder erfolgt. Der Blogtitel und der Inhalt des Blogposts sind jetzt in Dokumentfeldern mit den Namen „blog_title_txt“ und „blog_post_txt“ gespeichert. Daher muss ich die Stufe „Suchfelder“ der Abfrage-Pipeline so konfigurieren, dass diese Felder als Suchfelder definiert werden.
Das Bedienfeld auf der linken Seite der Startseite der Sammlung enthält Steuerelemente für die Suche und die Indizierung. Ich klicke auf das Steuerelement „Abfrage-Pipelines“ unter der Überschrift „Suche“ und wähle die Pipeline mit dem Namen „lw_blogs2-default“ zur Bearbeitung aus. Dies ist die Abfrage-Pipeline, die automatisch erstellt wurde, als die Sammlung „lw_blogs2“ angelegt wurde. Ich bearbeite die Stufe „Suchfelder“ und lege die Suche über beide Felder fest. Außerdem lege ich für das Feld „blog_title_txt“ einen Verstärkungsfaktor von 1,3 fest, so dass Dokumente, bei denen es eine Übereinstimmung im Titel gibt, als relevanter angesehen werden als Dokumente, bei denen es eine Übereinstimmung im Blogpost gibt. Sobald ich diese Konfiguration speichere, wird die Suche automatisch erneut ausgeführt:
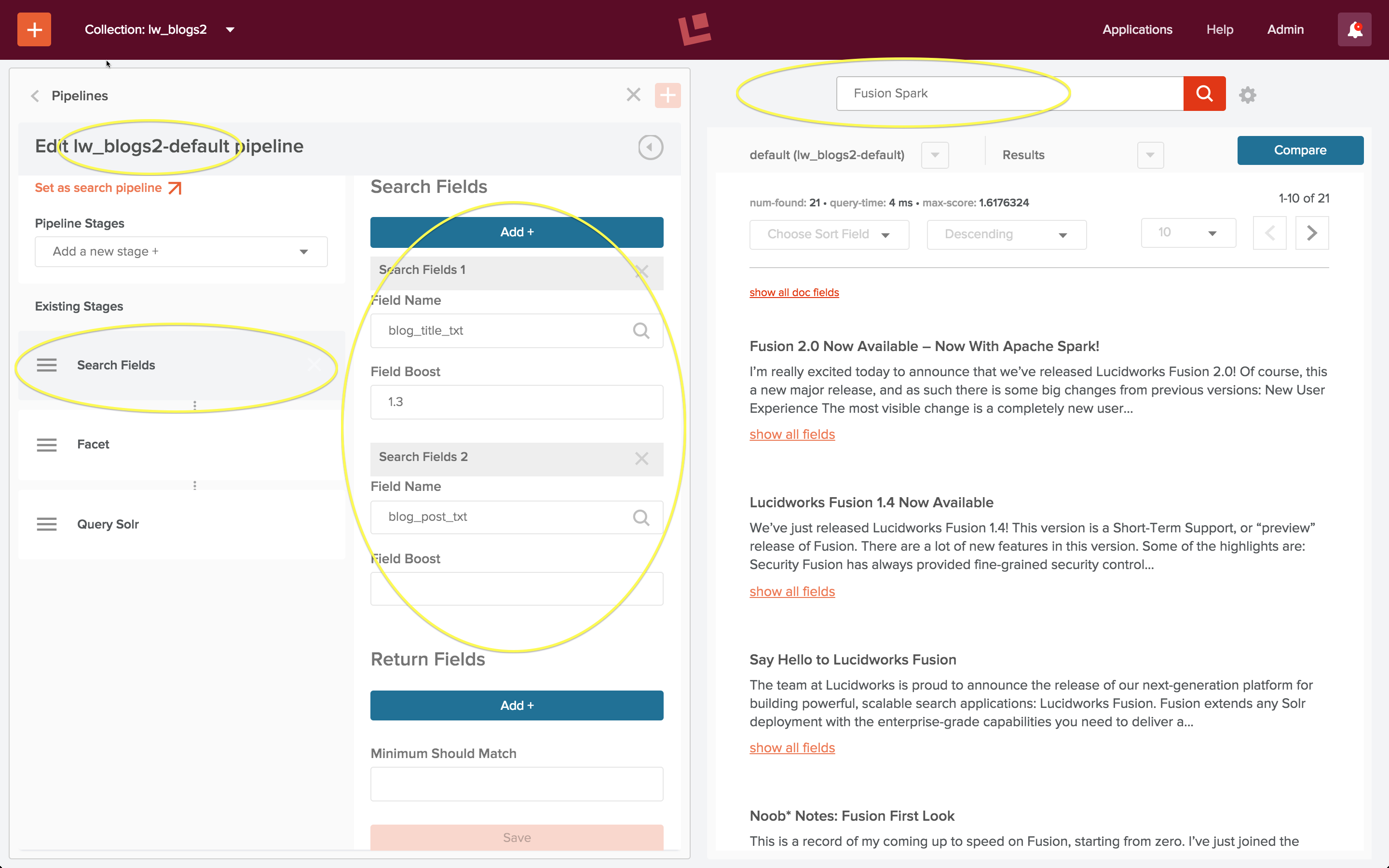
Die Ergebnisse sehen gut aus!
Fazit
Als Data Engineer ist es Ihre Aufgabe, wenn Sie sie annehmen, herauszufinden, wie Sie eine Suchanwendung erstellen können, die die Lücke zwischen den Informationen in der rohen Suchanfrage und dem, was Sie über Ihre Daten wissen, überbrückt, um das/die Dokument(e) zu liefern, das/die ganz oben in der Ergebnisliste stehen sollte (n). Die Standard-Such- und Indizierungspipelines von Fusion sind ein schneller und einfacher Weg, um die Informationen zu erhalten, die Sie über Ihre Daten benötigen. Benutzerdefinierte Pipelines machen diesen Einsatz möglich.