Why Knowledge Management Needs Conversational Search
The knowledge discovery industry has made significant strides in integrating natural language features into the search experience over the years. While there is always room for improvement, Lucidworks is thrilled with the progress we have made. We do still see that most researchers and knowledge workers enter queries of just a few words, perhaps guessing at how the search engine works, or giving up and moving over to the browse experience.
By training users to learn to search using metadata terms (for example, “traffic fatalities 2020”) rather than natural language (how many fatal auto accidents occurred in the US in 2020), we actually encourage ambiguity in query strings. The user wastes time and the search platform misses out on a more explicit expression of what the user is trying to accomplish.
Another aspect of today’s search experience is that the platform must depend on implicit signals in order to predict the user’s general goal. Is this browse related to the same goal as the previous search? Is the knowledge worker searching for documents relevant to a topic of research, or do they need an answer to a question of fact with cited sources? It is difficult to predict the user’s transition from one goal to another.
Why conversational search helps
We, at Lucidworks, believe that generative large language models enable us to accelerate progress towards a more conversational search experience – an experience that encourages users to express their goals in natural language. We intend to enable the search platform to behave as an assistant that guides the user by asking relevant questions and making suggestions rather than being limited to finding things based on what’s in the search box, and guessing at goals based on implicit signals.
An example: Let’s say I am doing market research for a micromobility mobile app. I need some data related to traffic safety but I’m not confident in my knowledge of trusted sources in that area. I’ll reach out to a colleague who is experienced in traffic safety research, and describe my goal.
“I’m doing market research for a new micromobility app for planning safe routes. Can you give me some advice on sources of traffic safety data related to micromobility?”
My colleague will likely ask me questions about geographic regions of interest, specific types of micromobility, etc. We end up having a short conversation, and I come away with a set of trusted sources and perhaps some ways to facet the data that I hadn’t considered.
This person-to-person approach is effective but not very scalable. Generative large language models will enable us to move the online search experience closer to the efficient exchange of information that comes from a person-to-person conversation.
Strategizing conversational search experiences
Okay, let’s talk about how we get there.
We start by considering elements of a good conversation. There are hundreds of lists of “the elements of a good conversation” – here are four I find to be relevant to the idea of conversational search:
#1. Listen actively. Active listening isn’t just repeating the question. It’s about asking clarifying questions and offering suggestions. And it’s about remembering the context of the conversation so the other party doesn’t have to repeat the same information.
#2. Pay attention to non-verbal cues. A search platform can’t see our body language, but it can pay attention to implicit signals. Conversational search delivers a new source of explicit signals, but we still need to pay attention to implicit signals.
#3. Stay on topic. Questions and responses should be relevant to the current conversation. This includes suggestions and other types of personalization.
#4. Build trust. Participants in a conversation build trust by being consistent, truthful, respectful, and willing to admit mistakes.
Our strategy is based on the idea that a generative language model can be instruction-tuned and prompted to perform a task related to an aspect of conversational search, while maintaining the elements of good conversation. We are creating a set of language model-powered agents to perform specific tasks, each of them with access to shared memory of conversations and associated implicit signals. We have built an ML Platform for surfacing conversational search features.
Our strategy can be visualized as such:
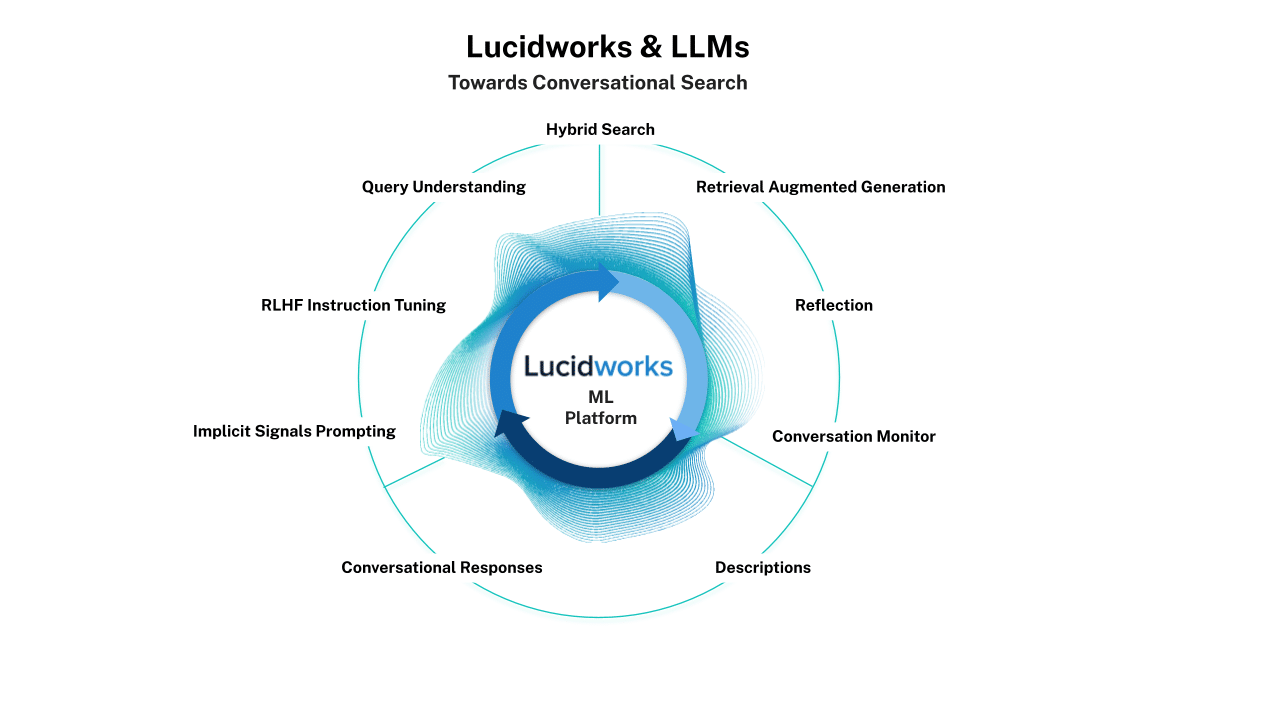
Query Understanding: We will use a generative language model to improve query understanding in order to improve the performance of hybrid search. What specifications are present in the query? Should the query be rewritten to improve recall or relevance ranking? We will also use a generative language model to improve the training of the semantic encoder model used by hybrid search, by generating additional synthetic training data. Pay attention to non-verbal queues. Stay on topic.
Hybrid Search: The system uses hybrid search (semantic + lexical) to cast a wide enough net so that there is a high probability of the most relevant documents being retrieved. The hybrid search is dependent on the semantic model – an encoder language model that represents a semantic vector space – to handle the recall and initial relevance ranking. Hybrid search must adhere to established access control to content, sometimes referred to as security trimming. Build trust. Stay on topic.
Retrieval Augmented Generation: A generative language model reranks and describes the results from hybrid search using natural language. This is an implementation of Retrieval Augmented Generation, where the output of the generative model is limited to the documents recalled by the preceding hybrid search. Some describe this as “grounding”. RAG is a key component of grounding generative language model responses in fact, and allows us to cite references. Build trust. Stay on topic.
Reflection: The generative language model reflects on its output from the previous step. Its task is to determine (by prompting itself!) if it can produce a better response. This step also incorporates a memory feature, so that it can benefit from prior reflections. Build trust. Stay on topic.
Conversation Monitor: We use a generative language model, working outside of the conversation context, to monitor both user and other model responses for respectful content. Some describe this as “alignment”. Build Trust.
Descriptions: We use additional prompts to request the generative language model to describe the individual documents in the results list. What is the most pertinent part of this document given the search conversation so far? Listen Actively.
Conversational Responses: The idea is that an implementation of conversational search should allow the user to ask questions and give additional instructions to continue a conversation after their initial request. And the search platform should respond to those inputs by asking clarifying questions to help refine its understanding of the user’s goal. Listen actively. Build trust.
Implicit Signals Prompting: Let’s assume that, so far, the user has not entered another prompt – they haven’t continued the explicit conversation. However, they have interacted with the system by clicking on results, filtering results, reading, etc. We can incorporate these implicit signals into some behind-the-curtain prompting of our generative language model. Pay attention to non-verbal cues.
RLHF Instruction Tuning: RLHF is reinforcement learning from human feedback. The idea is to continuously update fine-tuning instructions based on the explicit conversations and associated implicit signals. Listen actively. Pay attention to non-verbal queues.
Illustrating an example
First, let’s have a look at what can happen today when a user asks a general purpose chat website powered by an LLM to answer a research question – a question of fact.

Now, assume that we’ve used a conversational search platform to deploy a knowledge management application specific to an area of research. This application will rely on a set of trusted resources to ground LLM responses in fact.

Next Steps
At Lucidworks, we’re already thinking about where we’d like to take the potential of conversational search in a way that makes sense for our product and customers. We’ll be beginning with several implementations, such as:
- Query keyword extraction
- Hybrid search and RAG
- Document summaries
- Improved training of semantic models
- Allowing users to select the conversation they wish to continue.
We’ll be rolling out these features in Beta this coming July. Learn more about our thoughts on the relationship between LLMs like ChatGPT and our Lucidworks Platform, or take a look at our generative AI field guide for more on our approach to the technology. If you’d like to learn more about how Lucidworks solutions can support your brand’s search strategy, contact us today.