example/files – a Concrete Useful Domain-Specific Example of bin/post and /browse
The Series
This is the third in a three part series demonstrating how it’s possible to build a real application using just a few simple commands. The three parts to this are:
- Getting data into Solr using bin/post
- Visualizing search results: /browse and beyond
- ==> (you are here) Putting it together realistically: example/files – a concrete useful domain-specific example of bin/post and /browse
In the previous /browse article, we walked you through to the point of visualizing your search results from an aesthetically friendlier perspective using the VelocityResponseWriter. Let’s take it one step further.
example/files – your own personal Solr-powered file-search engine
The new example/files offers a Solr-powered search engine tuned specially for rich document files. Within seconds you can download and start Solr, create a collection, post your documents to it, and enjoy the ease of querying your collection. The /browse experience of the example/files configuration has been tailored for indexing and navigating a bunch of “just files”, like Word documents, PDF files, HTML, and many other formats.
Above and beyond the default data driven and generic /browse interface, example/files features the following:
- Distilled, simple, document type navigation
- Multi-lingual, localizable interface
- Language detection and faceting
- Phrase/shingle indexing and “tag cloud” faceting
- E-mail address and URL index-time extraction
- “instant search” (as you type results)
Getting started with example/files
Start up Solr and create a collection called “files”:
bin/solr start bin/solr create -c files -d example/files
Using the -d flag when creating a Solr collection specifies the configuration from which the collection will be built, including indexing configuration and scripting and UI templates.
Then index a directory full of files:
bin/post -c files ~/Documents
Depending on how large your “Documents” folder is, this could take some time. Sit back and wait for a message similar to the following:
23731 files indexed. COMMITting Solr index changes to http://localhost:8983/solr/files/update… Time spent: 0:11:32.323
And then open /browse on the files collection:
open http://localhost:8983/solr/files/browse
The UI is the App
With example/files we wanted to make the interface specific to the domain of file search. With that in mind, we implemented a file-domain specific ability to facet and filter by high level “types”, such as Presentation, Spreadsheet, and PDF. Taking a UI/UX-first approach, we also wanted “instant search” and a localizable interface.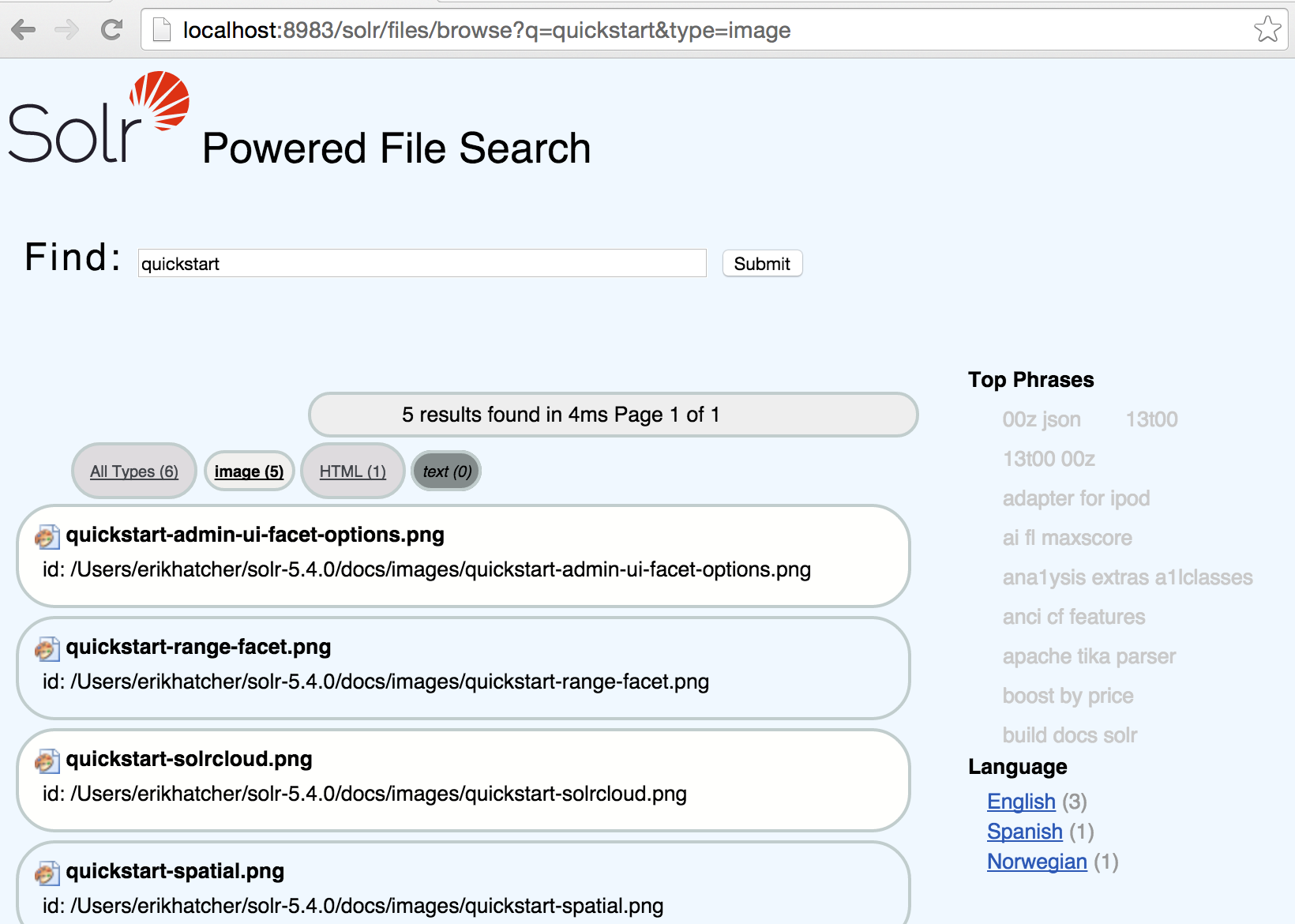
The rest of this article explains, from the outside-in, the design and implementation from UI and URL aesthetics down to the powerful Solr features that make it possible.
URLs are UI too!
“…if you think about how you design them” – Cool URIs
Besides the HTML/JavaScript/CSS “app” of example/files, care was taken on the aesthetics and cleanliness of the other user interface, the URL. The URLs start with /browse, describing the user’s primary activity in this interface – browsing a collection of documents.
Browsing by document type
Results can be filtered by document “type” using the links at the top.

As you click on each type, you can see the “type” parameter changing in the URL request.
For the aesthetics of the URL, we decided filtering by document type should look like this: /browse?type=pdf (or type=html, type=spreadsheet, etc). The interface also supports two special types: “all” to select all types and “unknown” to select documents with no document type.
At index-time, the type of a document is identified. An update processor chain (files-update-processor) is defined to run a script for each document. A series of regular expressions determine the high-level type of the document, based off of the inherent “content_type” (MIME type) field set for each rich document indexed. The current types are doc, html, image, spreadsheet, pdf, and text. If a high-level type is recognized, a doc_type field is set to that value.
defined to run a script for each document. A series of regular expressions determine the high-level type of the document, based off of the inherent “content_type” (MIME type) field set for each rich document indexed. The current types are doc, html, image, spreadsheet, pdf, and text. If a high-level type is recognized, a doc_type field is set to that value.
No doc_type field is added if the content_type does not have an appropriate higher level mapping, an important aspect to the filtering technique specifics. The /browse handler definition was enhanced with the following parameters to enable doc_type faceting and filtering using our own “type=…” URL parameter to filter by any of the types, including “all” or “unknown”:
- facet.field={!ex=type}doc_type
- facet.query={!ex=type key=all_types}*:*
- fq={!switch v=$type tag=type case=’*:*’ case.all=’*:*’ case.unknown=’-doc_type:[* TO *]’ default=$type_fq}
There are some details of how these parameters are set worth mentioning here. Two parameters, facet.field and facet.query, are specified in params.json utilizing the “paramset” feature of Solr. And the fq parameter is appended in the /browse definition in solrconfig.xml (because paramsets don’t currently allow appending, only setting, parameters).
The faceting parameters exclude the “type” filter (defined on the appended fq), such that the counts of the types shown aren’t affected by type filtering (narrowing to “image” types still shows “pdf” type counts rather than 0). There’s a special “all_types” facet query specified, that provides the count for all documents, within the query and other filtering constrained set. And then there’s the tricky fq parameter, leveraging the “switch” query parser that controls how the type filtering works from the custom “type” parameter. When no type parameter is provided, or type=all, the type filter is set to “all docs” (via *:*), effectively not filtering by type. When type=unknown, the special -doc_type:[* TO *] (note the dash/minus sign to negate), matching all documents that do not have a doc_type field. And finally, when a “type” parameter other than all or unknown is provided, the filter used is defined by the “type_fq” parameter which is defined in params.json as type_fq={!field f=doc_type v=$type}. That type_fq parameter specifies a field value query (effectively the same as fq=doc_type:pdf, when type=pdf) using the field query parser (which will end up being a basic Lucene TermQuery in this case).
That’s a lot of Solr mojo just to be able to say type=image from the URL, but it’s all about the URL/user experience so it was worth the effort to implement and hide the complexity.
Localizing the interface
 The example/files interface has been localized in multiple languages. Notice the blue global icon in the top right-hand corner of the /browse UI. Hover over the globe icon and select a language in which to view your collection.
The example/files interface has been localized in multiple languages. Notice the blue global icon in the top right-hand corner of the /browse UI. Hover over the globe icon and select a language in which to view your collection.
Each text string displayed is defined in standard Java resource bundles (see the files under example/files/browse-resources). For example, the text (“Find” in English) that appears just before the search input box is specified in each of the language-specific resource files as:
English: find=Find French: find=Recherche German: find=Durchsuchen
The VelocityResponseWriter’s $resource tool picks up on a locale setting. In the browse.vm (example/files/conf/velocity/browse.vm) template, the “find” string is specified generically like this:
$resource.find: <input name=”q”…/>
From the outside, we wanted the parameter used to select the locale to be clean and hide any implementation details, like /browse?locale=de_DE.
The underlying parameter needed to control the VelocityResponseWriter $resource tool’s locale is v.locale, so we use another Solr technique (parameter substitution) to map from the outside locale parameter to the internal v.locale parameter.
This parameter substitution is different than “local param substitution” (used with the “type” parameter settings above) which only applies as exact param substitution within the {!… syntax} as dollar signed non-curly bracketed {!… v=$foo} where the parameter foo (&foo=…) is substituted in. The dollar sign curly bracketed syntax can be used as an in-place text substitution, allowing a default value too like ${param:default}.
To get the URLs to support a locale=de_DE parameter, it is simply substituted as-is into the actual v.locale parameter used to set the locale within the Velocity template context for UI localization. In params.json we’ve specified v.locale=${locale}
Language detection and faceting
It can be handy to filter a set of documents by its language. Handily, Solr sports two(!) different language detection implementations so we wired one of them up into our update processor chain like this:
<processor class="org.apache.solr.update.processor.LangDetectLanguageIdentifierUpdateProcessorFactory">
<lst name="defaults">
<str name="langid.fl">content</str>
<str name="langid.langField">language</str>
</lst>
</processor>
With the language field indexed in this manner, the UI simply renders its facets (facet.field=language, in params.json), allowing filtering too.
Phrase/shingle indexing and “tag cloud” faceting
Seeing common phrases can be used to get the gist of a set of documents at a glance. You’ll notice the top phrases change as a result of the “q” parameter changing (or filtering by document type or language). The top phrases reflect phrases that appear most frequently in the subset of results returned for a particular query and applied filters. Click on a phrase to display the documents in your results set that contain the phrase. The size of the phrase corresponds to the number of documents containing that phrase.
Phrase extraction of the “content” field text occurs by copying to a text_shingles field which creates phrases using a ShingleFilter. This feature is still a work in progress and needs improvement in extracting higher quality phrases; the current rough implementation isn’t worth adding a code snippet here to imply folks should copy/paste emulate it, but here’s a pointer to the current configuration – https://github.com/apache/lucene-solr/blob/branch_5x/solr/example/files/conf/managed-schema#L408-L427
E-mail address and URL index-time extraction
One, currently unexposed, feature added for fun is the index-time extraction of e-mail addresses and URLs from document content. With phrase extraction as described above, the use is to allow for faceting and filtering, but when looking at an individual document we didn’t need the phrases stored and available. In other words, text_shingles did not need to be a stored field, and thus we could leverage the copyField/fieldType technique. But for extracted e-mail addresses and URLs, it’s useful to have these as stored (multi-valued), not just indexed terms… which means our indexing pipeline needs to provide these independently stored values. The copyField/fieldType-extraction technique won’t suffice here. However, we can use a field type definition to help, and take advantage of its facilities within an update script. Update processors, like the script one used here, allow for full manipulation of an incoming document, including adding additional fields, and thus their value can be “stored”. Here are the configuration pieces that extract e-mail addresses and URLs from text:
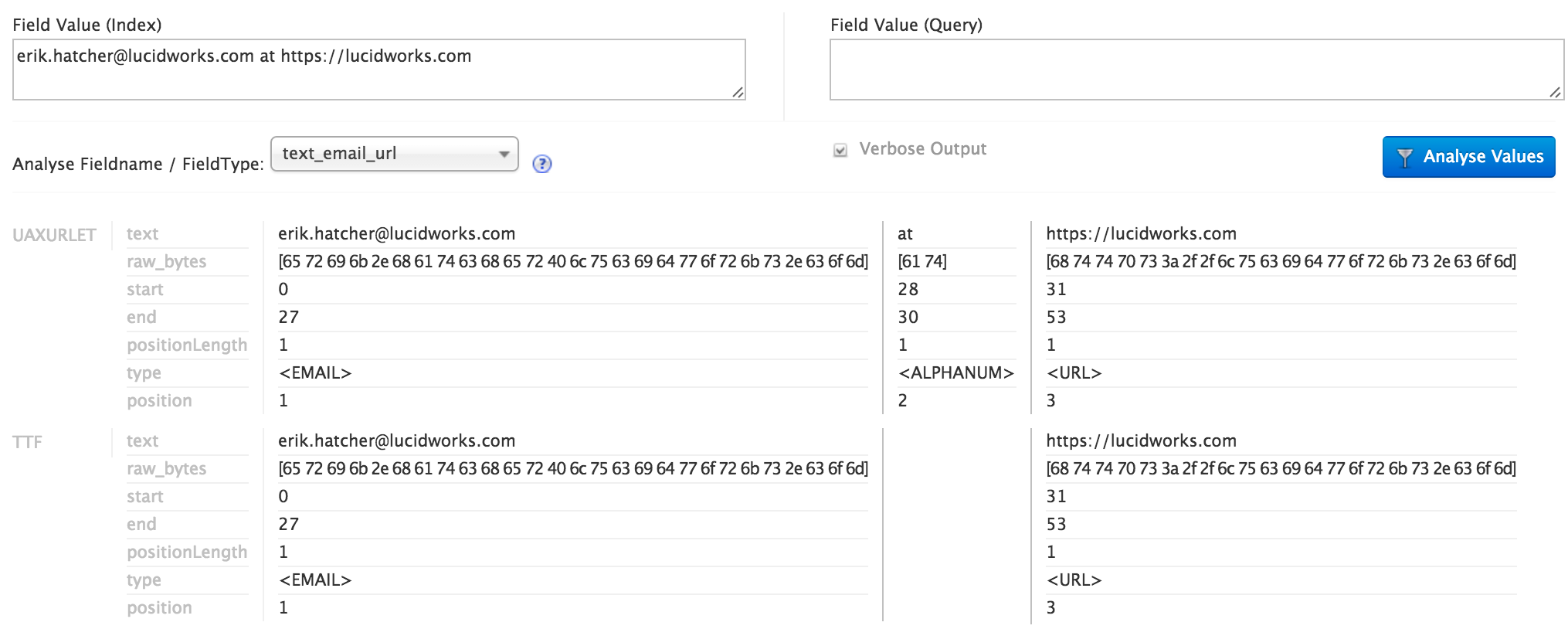
 The Solr admin UI analysis tool is useful for seeing how this field type works. The first step, through the UAX29URLEmailTokenizer, tokenizes the text in accordance with the Unicode UAX29 segmentation specification with the special addition to recognize and keep together e-mail addresses and URLs. During analysis, the tokens produced also carry along a “type”. The following screenshot depicts the Solr admin analysis tool results of analyzing an “e-mail@lucidworks.com https://lucidworks.com” string with the text_email_url field type. The tokenizer tags e-mail addresses with a type of, literally, “<EMAIL>” (angle brackets included), and URLs as “<URL>”. There are other types of tokens that URL/email tokenizer emits, but for this purpose we only want to screen out everything but e-mail addresses and URLs. Enter TypeTokenFilter, allowing only a strictly specified set of token type values to pass through. In the screenshot you’ll notice the text “at” was identified as type “<ALPHANUM>”, and did not pass through the type filter. An external text file (email_url_types.txt) contains the types to pass through, and simply contains two lines with the values “<URL>” and “<EMAIL>”.
The Solr admin UI analysis tool is useful for seeing how this field type works. The first step, through the UAX29URLEmailTokenizer, tokenizes the text in accordance with the Unicode UAX29 segmentation specification with the special addition to recognize and keep together e-mail addresses and URLs. During analysis, the tokens produced also carry along a “type”. The following screenshot depicts the Solr admin analysis tool results of analyzing an “e-mail@lucidworks.com https://lucidworks.com” string with the text_email_url field type. The tokenizer tags e-mail addresses with a type of, literally, “<EMAIL>” (angle brackets included), and URLs as “<URL>”. There are other types of tokens that URL/email tokenizer emits, but for this purpose we only want to screen out everything but e-mail addresses and URLs. Enter TypeTokenFilter, allowing only a strictly specified set of token type values to pass through. In the screenshot you’ll notice the text “at” was identified as type “<ALPHANUM>”, and did not pass through the type filter. An external text file (email_url_types.txt) contains the types to pass through, and simply contains two lines with the values “<URL>” and “<EMAIL>”.
So now we have a field type that can do the recognition and extraction of e-mail address and URLs. Let’s now use it from within the update chain, conveniently possible in update-script.js. With some scary looking JavaScript/Java/Lucene API voodoo, it’s achieved with the code shown above in update-script.js. That code is essentially how indexed fields get their terms, we’re just having to do it ourselves to make the values *stored*.
This technique was originally described in the “Analysis in ScriptUpdateProcessor” section of this this presentation: http://www.slideshare.net/erikhatcher/solr-indexing-and-analysis-tricks
example/files demonstration video
Thanks go to Esther Quansah who developed much of the example/files configuration and produced the demonstration video during her internship at Lucidworks.
What’s next for example/files?
An umbrella Solr JIRA issue has been created to note these desirable fixes and improvements – An umbrella Solr JIRA issue has been created to note these desirable fixes and improvements: https://issues.apache.org/jira/browse/SOLR-8590 – including the following items:
- Fix e-mail and URL field names (<email>_ss and <url>_ss, with angle brackets in field names), also add display of these fields in /browse results rendering
- Harden update-script: it currently errors if documents do not have a “content” field
- Improve quality of extracted phrases
- Extract, facet, and display acronyms
- Add sorting controls, possibly all or some of these: last modified date, created date, relevancy, and title
- Add grouping by doc_type perhaps
- fix debug mode – currently does not update the parsed query debug output (this is probably a bug in data driven /browse as well)
- Filter out bogus extracted e-mail addresses
The first two items were fixed and patch submitted during the writing of this post.
Conclusion
Using example/files is a great way of exploring the built-in capabilities of Solr specific to rich text files.
A lot of Solr configuration and parameter trickery makes /browse?locale=de_DE&type=html a much cleaner way to do this: /select?v.locale=de_DE&fq={!field%20f=doc_type%20v=html}&wt=velocity&v.template=browse&v.layout=layout&q=*:*&facet.query={!ex=type%20key=all_types}*:*&facet=on… (and more default params)
Mission to “build a real application using just a few simple commands” accomplished! It’s so succinct and clean that you can even tweet it!
https://lucidworks.com/blog/2016/01/27/example_files:$ bin/solr start; bin/solr create -c files -d example/files; bin/post -c files ~/Documents #solr