Marry Search and AI With Fusion’s Data Science Toolkit Integration
For data scientists and search engineers, it can be hard work to collaborate and stay in sync. Organizations are increasingly relying on data scientists and machine learning to craft a hyper-personalized experience to meet users’ expectations and increase engagement. However, the process of optimizing these algorithms has typically been time-intensive and slow-moving.
Fusion 5.0 enables easier operationalizing of models to speed time to deployment for data scientists and lighten the load on developers.
“Marrying search and AI is a major challenge and opportunity for organizations that are working to build a more personal user experience. Data scientists want to spend their energy building better models, while search developers’ main drive is to make search relevant in a measurable way. Models are a means to that end,” explains Radu Miclaus, Lucidworks Director of Product, AI and Cloud.
“This new feature in Fusion 5.0 makes the hand-off between these two key players completely seamless and collaborative without forcing either outside their wheelhouse. Magic happens when robust models can be serviced directly into search without human-intensive processes.”
With Fusion 5.0, data scientists don’t have to rely on developers to translate and recode algorithms into production system languages (like Java) before they can be deployed for indexing and querying. They can continue to use favorite tools like scikit-learn, spaCy, and TensorFlow to develop models for a wide spectrum of NLP, machine learning, and deep learning techniques and immediately deploy them through a native Python connector into Fusion.
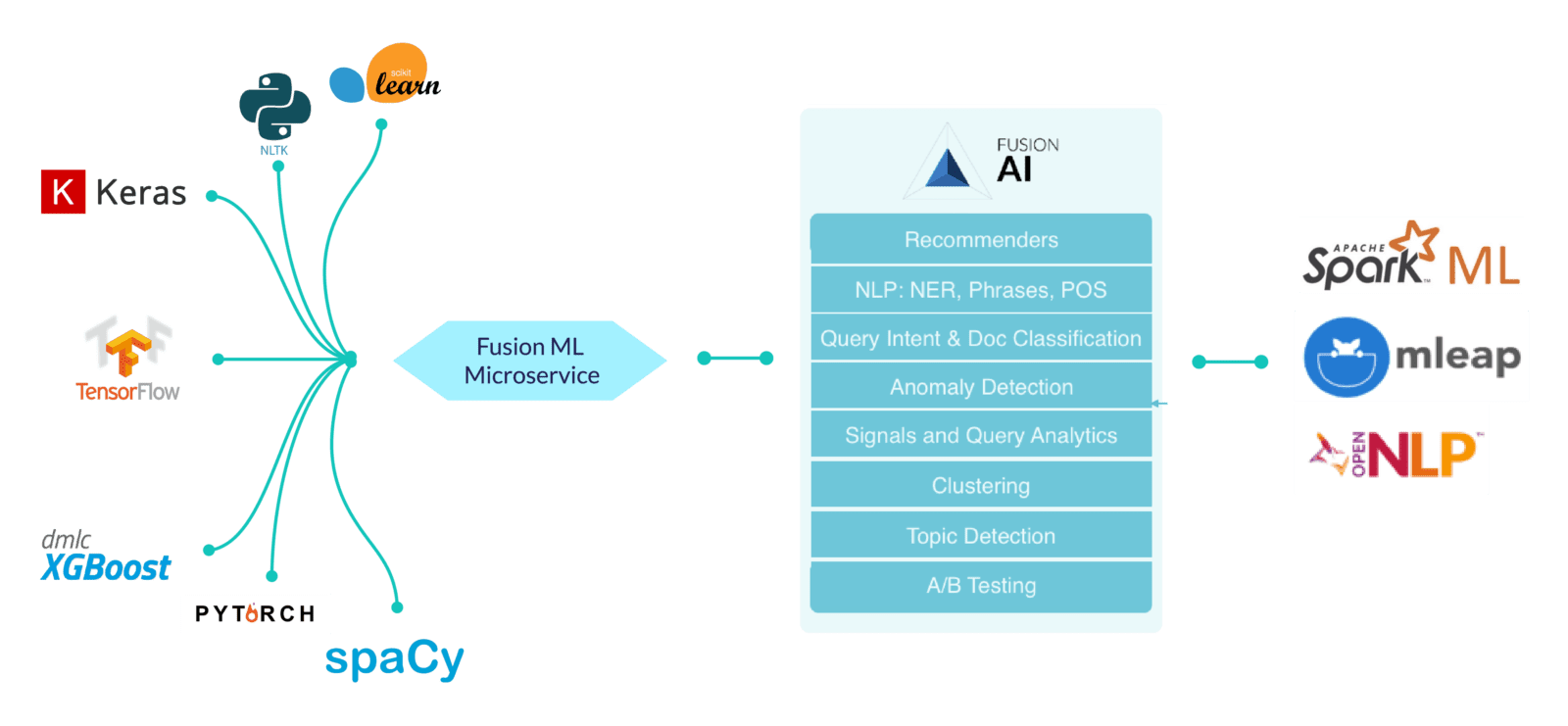
The Fusion 5.0 cloud-native architecture, built on containers, microservices, and APIs, brings a new dimension of agility for data science tasks. Using the versatile Python SDK, models can be trained, modified, tested, and published directly from Jupyter Notebook.
Fusion 5.0 provides all the flexibility organizations need for development with the governance and controls afforded by enterprise-grade production pipelines. By shortening the time to production and more deeply integrating data science tasks into search processes, organizations will drive more speed, scale, and intelligence in their pursuit of highly personalized search experiences for their customers and users.
Interested? Learn more about Fusion 5.0 and check out the data science toolkit integration feature.