Preliminary Data Analysis with Fusion
Lucidworks Fusion is the platform for search and data engineering. In article Search Basics for Data Engineers, I introduced the core features of Lucidworks Fusion 2 and used it to index some blog posts from the Lucidworks blog, resulting in a searchable collection. Here is the result of a search for blog posts about Fusion:
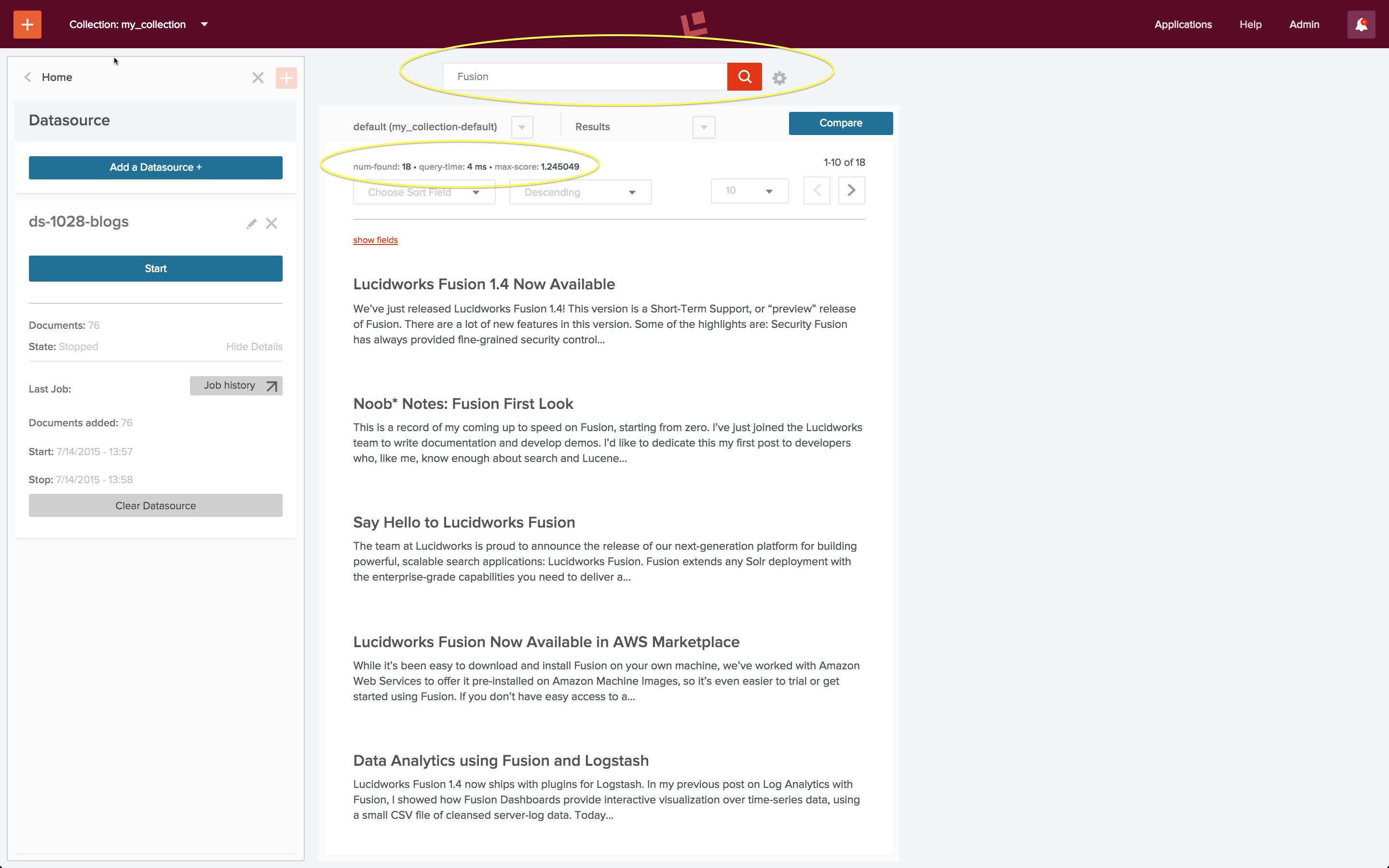
Bootstrapping a search app requires an initial indexing run over your data, followed by successive cycles of search and indexing until your application does what you want it to do and what search users expect it to do. The above search results required one iteration of this process. In this article, I walk through the indexing and query configurations used to produce this result.
Look
Indexing web data is challenging because what you see is not always what you get. That is, when you look at a web page in a browser, the layout and formatting is guiding your eye, making important information more prominent. Here is what a recent Lucidworks blog entry looks like in my browser:
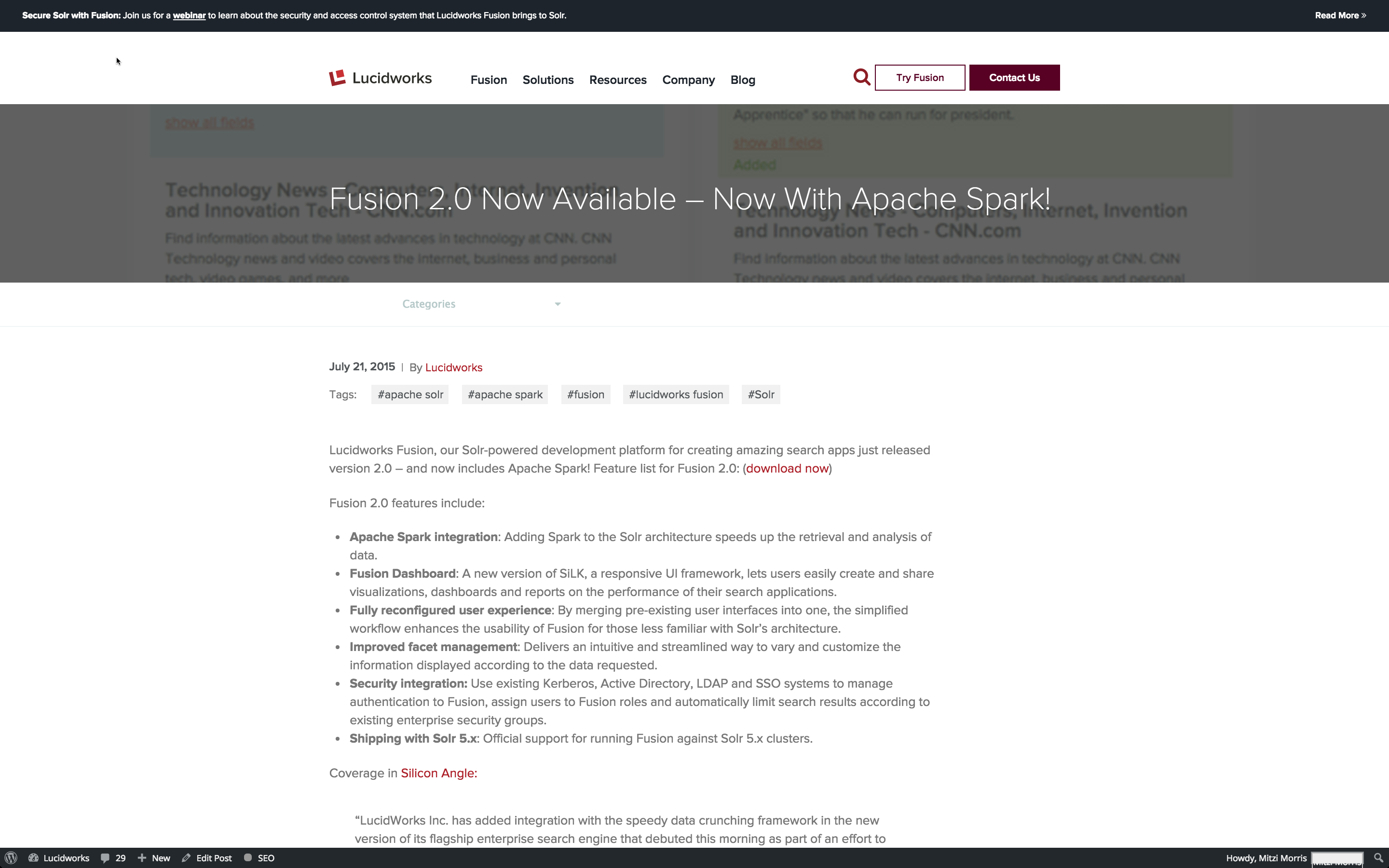
There are navigational elements at the top of the page, but the most prominent element is the blog post title, followed by the elements below it: date, author, opening sentence, and the first visible section heading below that.
I want my search app to be able to distinguish which information comes from which element, and be able to tune my search accordingly. I could do some by-hand analysis of one or more blog posts, or I could use Fusion to index a whole bunch of them; I choose the latter option.
Leap
Pre-configured Default Pipelines
For the first iteration, I use the Fusion defaults for search and indexing. I create a collection “lw_blogs” and configure a datasource “lw_blogs_ds_default”. Website access requires use of the Anda-web datasource, and this datasource is pre-configured to use the “Documents_Parsing” index pipeline.
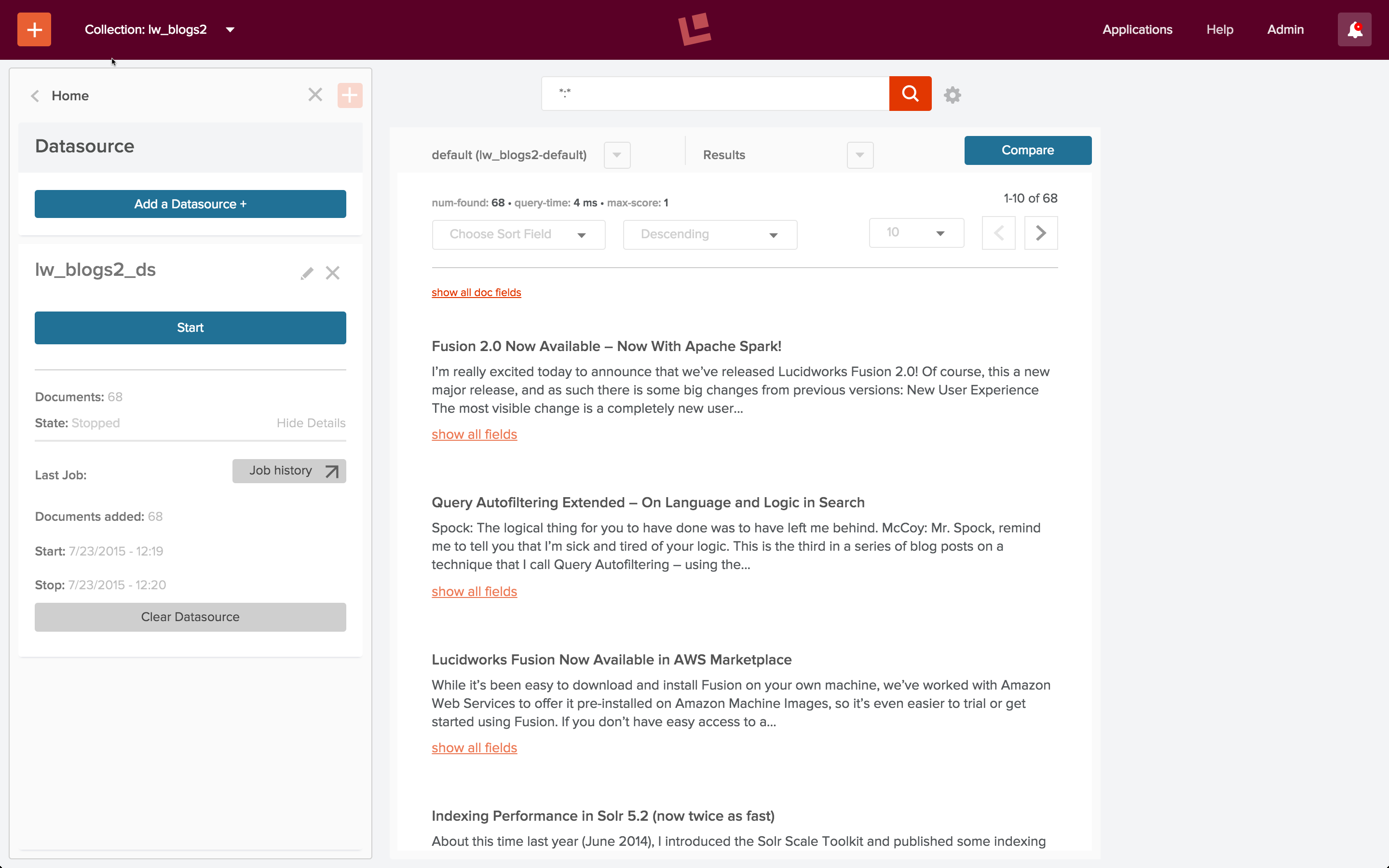
I start the job, let it run for a few minutes, and then stop the web crawl. The search panel is pre-populated with a wildcard search using the default query pipeline. Running this search returns the following result:
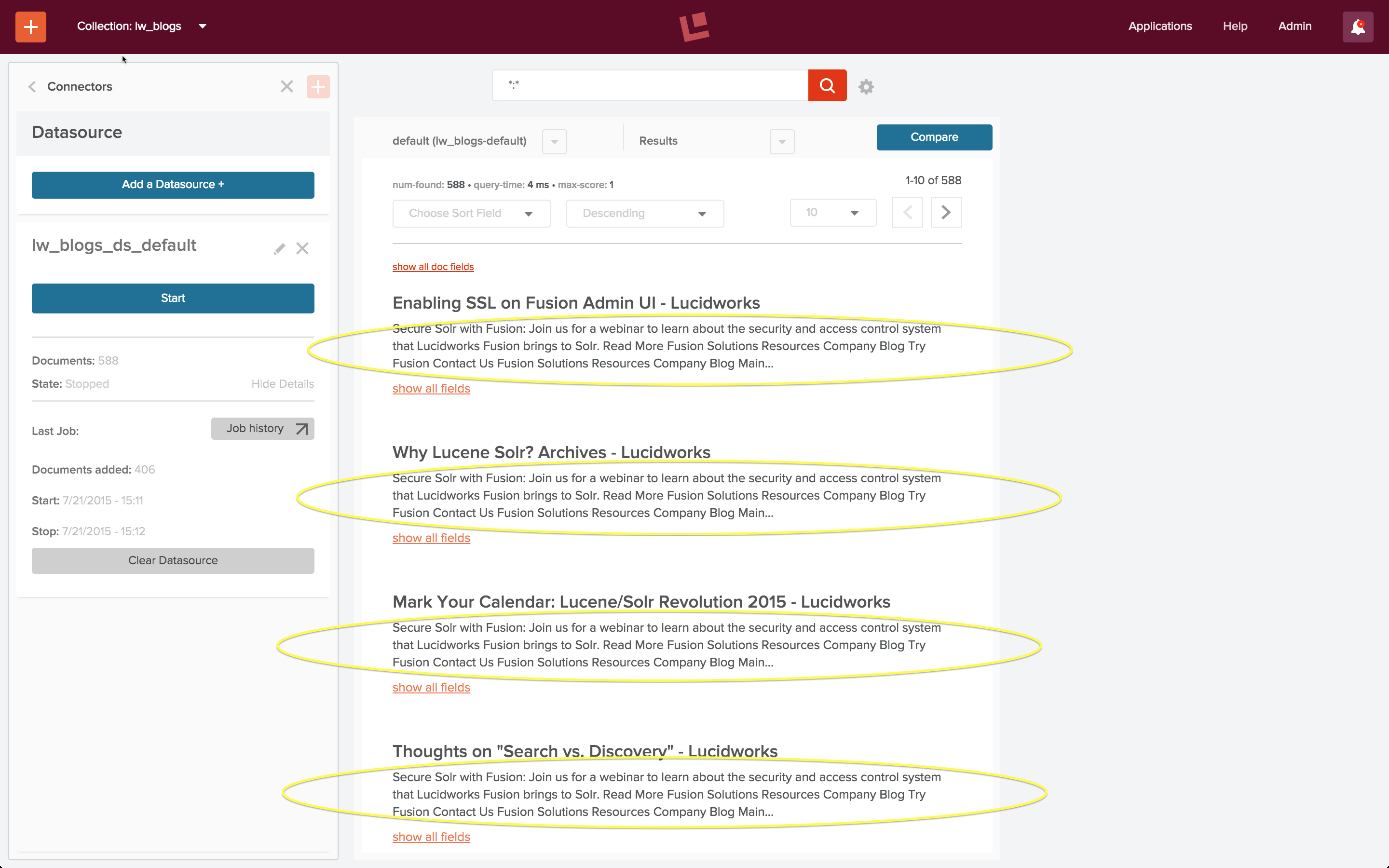
At first glance, it looks like all the documents in the index contain the same text, despite having different titles. Closer inspection of the content of individual documents shows that this is not what’s going on. I use the “show all fields” control on the search results panel and examine the contents of field “content”:
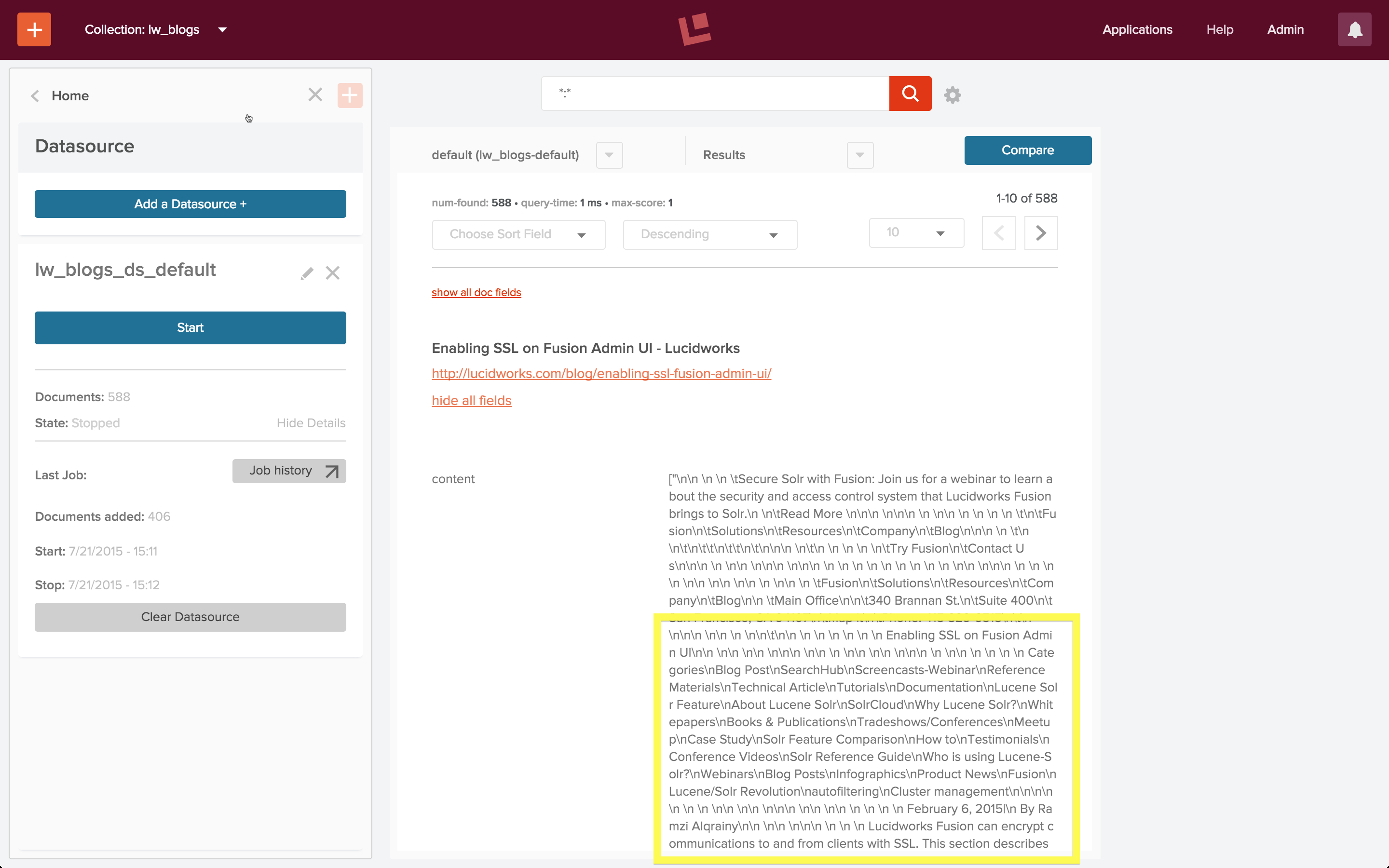
Reading further into this field shows that the content does indeed correspond to the blog post title, and that all text in the body of the HTML page is there. The Apache Tika parser stage extracted the text from all elements in the body of the HTML page and added it to the “content” field of the document, including all whitespace between and around nested elements, in the order in which they occur in the page. Because all the blog posts contain a banner announcement at the top and a set of common navigation elements, all of them have the same opening text:
nn n n tSecure Solr with Fusion: Join us for a webinar to learn about the security and access control system that Lucidworks Fusion brings to Solr.n ntRead More nnn nnn n nn n n n n tntFusionn ...
This first iteration shows me what’s going on with the data, however it fails to meet the requirement of being able to distinguish which information comes from which element, resulting in poor search results.
Repeat
Custom Index Pipeline
Iteration one used the “Documents_Parsing” pipeline, which consists of the following stages:
- Apache Tika Parser – recognizes and parses most common document formats, including HTML
- Field Mapper – transforms field names to valid Solr field names, as needed
- Language Detection – transforms text field names based on language of field contents
- Solr Indexer – transforms Fusion index pipeline document into Solr document and adds (or updates) document to collection.
In order to capture the text from a particular HTML element, I need to add an HTML transform stage to my pipeline. I still need to have an Apache Tika parser stage as the first stage in my pipeline in order to transform the raw bytes sent across the wire by the web crawler via HTTP into an HTML document. But instead of using the Tika HTML parser to extract all text from the HTML body into a single field, I use the HTML transform stage to harvest elements of interest each into its own field. As a first cut at the data, I’ll use just two fields: one for the blog title and the other for the blog text.
I create a second collection “lw_blogs2”, and configure another web datasource, “lw_blogs2_ds”. When Fusion creates a collection, it also creates an indexing and query pipeline, using the naming convention collection name plus “-default” for both pipelines. I choose the index pipeline “lw_blogs2-default”, and open the pipeline editor panel in order to customize this pipeline to process the Lucidworks blog posts:
The initial collection-specific pipeline is configured as a “Default_Data” pipeline: it consists of a Field Mapper stage followed by a Solr Indexer stage.
Adding new stages to an index pipeline pushes them onto the pipeline stages stack, therefore first I add and HTML Transform stage then I add an Apache Tika parser stage, resulting in a pipeline which starts with an Apache Tika Parser stage followed by an HTML Transform stage. First I edit the Apache Tika Parser stage as follows:
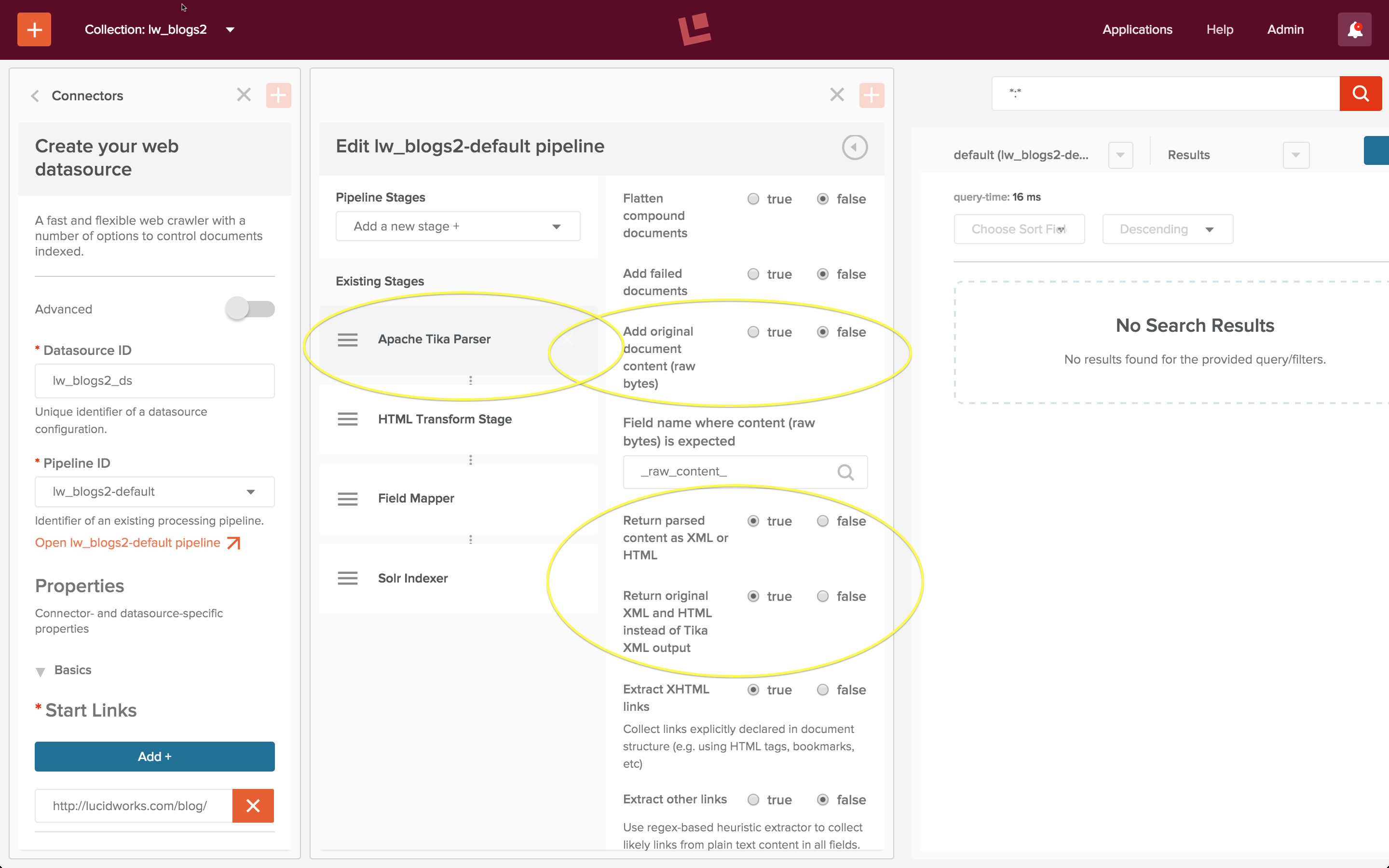
When using an Apache Tika parser stage in conjunction with an HTML or XML Transform stage the Tika stage must be configured:
- option “Add original document content (raw bytes)” setting: false
- option “Return parsed content as XML or HTML” setting: true
- option “Return original XML and HTML instead of Tika XML output” setting: true
With these settings, Tika transforms the raw bytes retrieved by the web crawler into an HTML document. The next stage is an HTML Transform stage which extracts the elmenets of interest from the body of the HTML document:
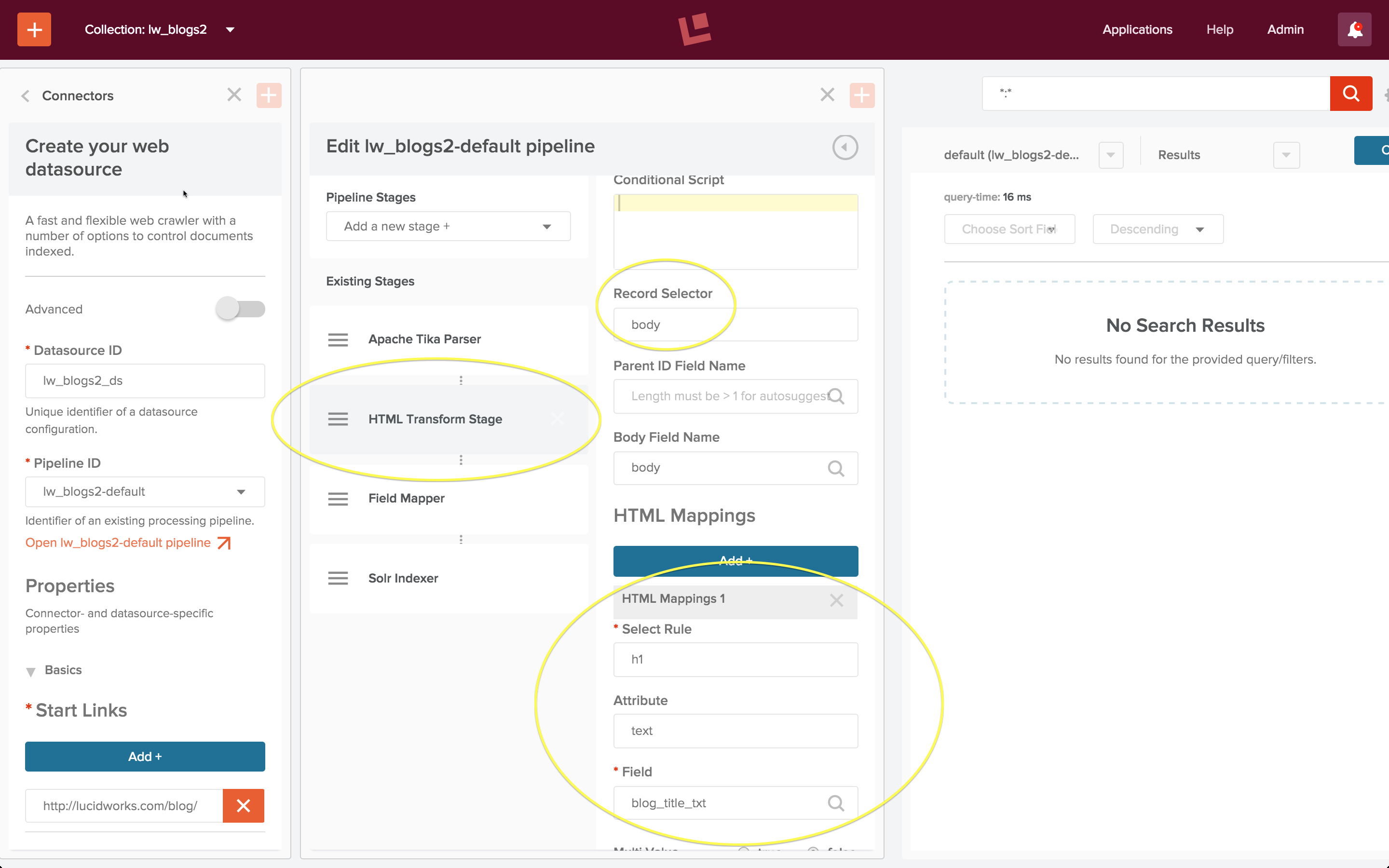
An HTML transform stage requires the following configuration:
- property “Record Selector”, which specifies the HTML element that contains the document.
- HTML Mappings, a set of rules which specify how different HTML elements are mapped to Solr document fields.
Here the “Record Selector” property “body” is the same as the default “Body Field Name” because each blog post contains is a single Solr document. Inspection of the raw HTML shows that the blog post title is in an “h1” element, therefore the mapping rule shown above specifies that the text contents of tag “h1” is mapped to the document field named “blog_title_txt”. The post itself is inside a tag “article”, so the second mapping rule, not shown, specifies:
- Select Rule: article
- Attribute: text
- Field: blog_post_txt
The web crawl also pulled back many pages which contain summaries of ten blog posts but which don’t actually contain a blog post. These are not interesting, therefore I’d like to restrict indexing to only documents which contain a blog post. To do this, I add a condition to the Solr Indexer stage:
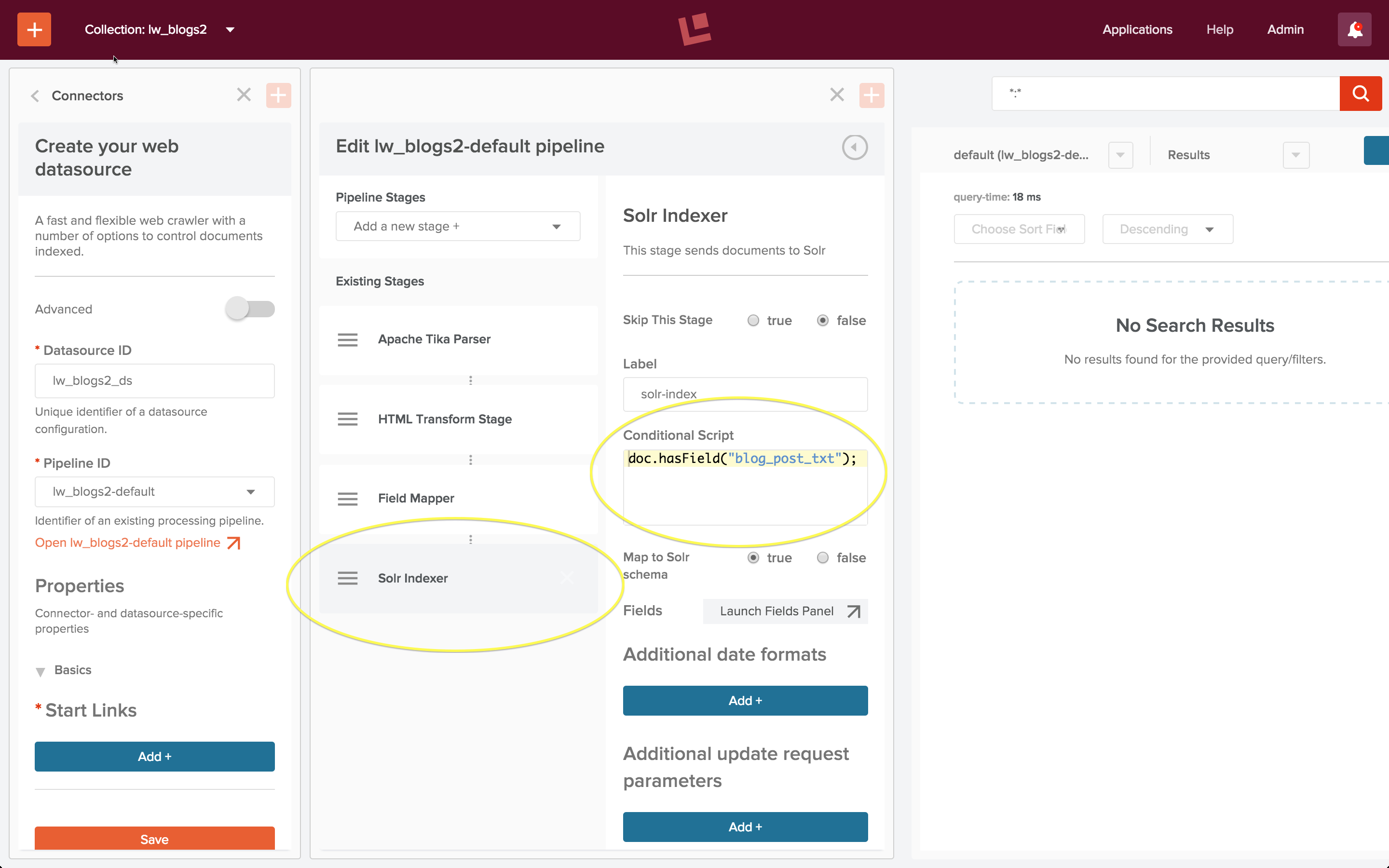
I start the job, let it run for a few minutes, and then stop the web crawl. I run a wildcard search, and it all just works!
Custom Query Pipeline
To test search, I do a query on the words “Fusion Spark”. My first search returns no results. I know this is wrong because the articles pulled back by the wildcard search above mention both Fusion and Spark.
The reason for this apparent failure is that search is over document fields. The blog title and blog post content are now stored in document fields named “blog_title_txt” and “blog_post_txt”. Therefore, I need to configure the “Search Fields” stage of the query pipeline to specify that these are search fields.
The left-hand collection home page control panel contains controls for both search and indexing. I click on the “Query Pipelines” control under the “Search” heading, and choose to edit the pipeline named “lw_blogs2-default”. This is the query pipeline that was created automatically when the collection “lw_blogs2” was created. I edit the “Search Fields” stage and specify search over both fields. I also set a boost factor of 1.3 on the field “blog_title_txt”, so that documents where there’s a match on the title are considered more relevant that documents where there’s a match in the blog post. As soon as I save this configuration, the search is re-run automatically:
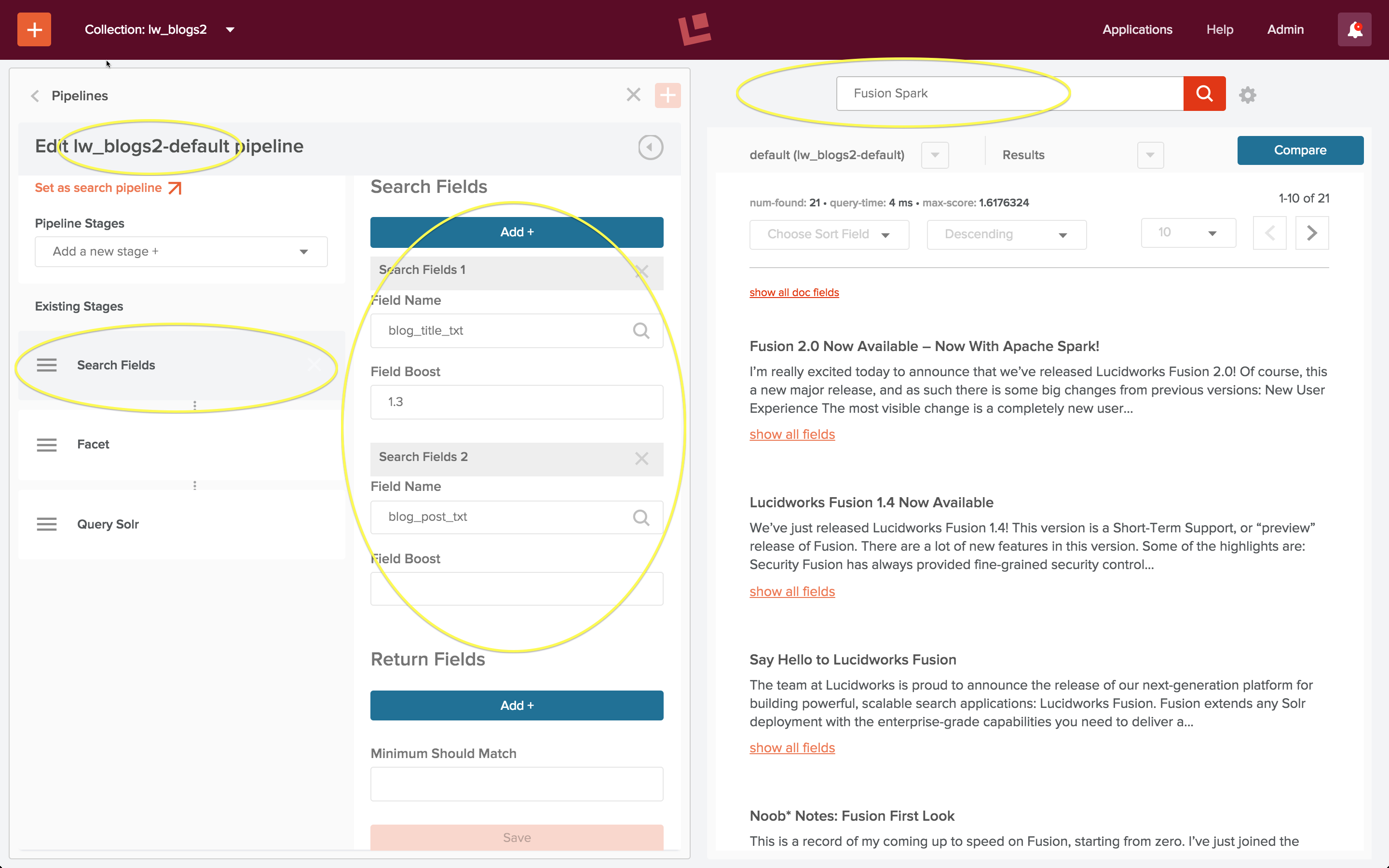
The results look good!
Conclusion
As a data engineer, your mission, should you accept it, is to figure out how to build a search application which bridges the gap between the information in the raw search query and what you know about your data in order to to serve up the document(s) which should be at the top of the results list. Fusion’s default search and indexing pipelines are a quick and easy way to get the information you need about your data. Custom pipelines make this mission possible.