Using Intent Data to Optimize the Self-Solve Experience
Self-serve support options are more ubiquitous than ever, from printing out movie theatre tickets to self-checkout at grocery stores to scanning a QR code at a cafe for a contact-less digital menu. This emphasis on self-service is even more important than ever with the COVID-19 pandemic as governments enforce rules and restrictions on businesses and commerce to minimize human touch points. Similarly, for customers that are using a digital product or service, they don’t want to wait in a live chat or phone queue to get help. They want to go to your customer portal and find what they need to to get answers quickly.
With the move to remote work and more time spent at home, companies are seeing a large increase in support case volume. At the same time, the market downturn is forcing companies to cut costs wherever they can. It’s estimated that live support channels like phones, live chat, and email cost about $8 per contact. Compare this to self-serve channels like support portals and mobile apps that cost just 10 cents per contact.
Lucidworks customer Red Hat presented at our annual Activate Search & AI conference, held virtually this year. Their session was titled, “Optimizing Customer Self-Solve Experience Using Intent at Red Hat.” Senior Data Scientist Jaydeep Rane and Principal Software Engineer Manikandan Sivanesan presented a session on how they improved findability in their self-solve customer support experience and established new patterns to improve workflow efficiency.
 Customers subscribe to Red Hat products with varying levels of operational complexity. Ensuring customers have the right resources such as knowledge base, tooling, and support for troubleshooting is the key to customer renewal and retention. To this end, Red Hat uses a robust array of self-solve options to help customers save time and reduce customer frustration.
Customers subscribe to Red Hat products with varying levels of operational complexity. Ensuring customers have the right resources such as knowledge base, tooling, and support for troubleshooting is the key to customer renewal and retention. To this end, Red Hat uses a robust array of self-solve options to help customers save time and reduce customer frustration.
Search Is Critical for Self-Solve
With self-solve a key component in delivering on the value of a subscription, search is critical. Search connects users to knowledge resources, documentation, and the deployment tools they need to self-solve using their customer portal. Ideally, if a customer faces an outage or a bug, they quickly find the root cause or error, go to the customer support portal, and find the answer to diagnose and solve the problem themselves, saving time and money and also saving potential revenue loss for their customers.
Red Hat has two search interfaces. One is their site search for their entire customer portal. This is where all the resources are available from one unified search experience. The second search interface is the troubleshooting interface or Solution Engine. In both of these search experiences, the option to open a support case immediately is always prominent, visible, and available if the customer wants to start a support case.
The customer portal is a gateway for Red Hat’s customers to either find solutions to a problem they are facing with a Red Hat product – to self-solve – or open a support case with a live agent. Customers are more likely to self-solve when they visit Red Hat’s troubleshooting experience, the Solution Engine. Customer surveys showed that four out of five customers visiting their customer portal are motivated to self-solve on the Solution Engine rather than open a support case.
What is the right step in the self-solve process to introduce recommendations from the Solution Engine? This is where the intent classification model comes into the picture.
The Two Types of Searches
The team reviewed search logs to examine their own unique mix of queries from users of all types, hoping that certain words or phrases would point them towards the motivation of the users. What emerged was two types of intentions:
- Usage queries which are when the customer wants to know how to use a specific Red Hat product or component, these are considered informational queries
- Troubleshooting queries which are when the customer has encountered a particular problem or significant error in trying to use a product or component
Both of these intentions can result in case creation, but by fine-tuning search, the team hoped to guide customers towards a self-solve solution in the Solution Engine rather than opening a case.
The team built a supervised learning model to find latent intents for better data labeling and creating a high quality data set. They looked at queries from the first half of the year. They used domain exports and lists of keywords to manually label queries For example, words such as what, why, where, how, install indicate a usage query. So any time you saw a query with these words, it would be tagged as usage. For troubleshoot, words like fail, failure, error often occur in the query. This hand-labeled data set was fed into an active learning tool which helped label several thousand datapoints to enable rapid prototyping while building their model.

Data Pre-Processing to Cook Data Down
Data pre-processing was also used to convert and clean strings so the output would be more valuable to the learning model. The raw text of queries contains language components that actually hinder the performance of the model.
Take the example of the query, Hi, please help me with the OpenShift installation.

- In the first step, all characters are converted to lowercase for the sake of uniformity across all queries.
- In step two, punctuation and symbols are removed
- The third step removes traditional stop words using the popular NLTK stop-word list
- The final step removes specific corpus-specific stop words (like the company name) that frequently occur in this specific data set and are not really important to the model.
With the cleaned up queries, the next step to classification was converting this text into a numeric vector. The Red Hat team chose the popular term frequency–inverse document frequency or TD-IDF approach.
Putting TF-IDF to Work
This approach ran through thousands of queries in a matter of seconds to calculate how often a given word appears in the string and then downscale words that appear more frequently across different strings. Essentially this approach calculates the importance of each word in the overall data set.

But how exactly does this convert these words to numbers? The team used the TF-IDF vectorization technique – short for term frequency–inverse document frequency.
Let’s say we have a data set consisting of two strings:
- The first string is my cat is not like my dog
- The second string is my dog is like an elephant
We calculate the term frequency score and the inverse document frequency score for the word in the first string. After doing all this heavy lifting and data cleaning of identifying the problem statement and now, it all boils down to the kind of model we run our data through. The team chose the linear support vector machine classifier that uses classification algorithms to put groups of things into two discrete groups, in this case usage and troubleshooting.
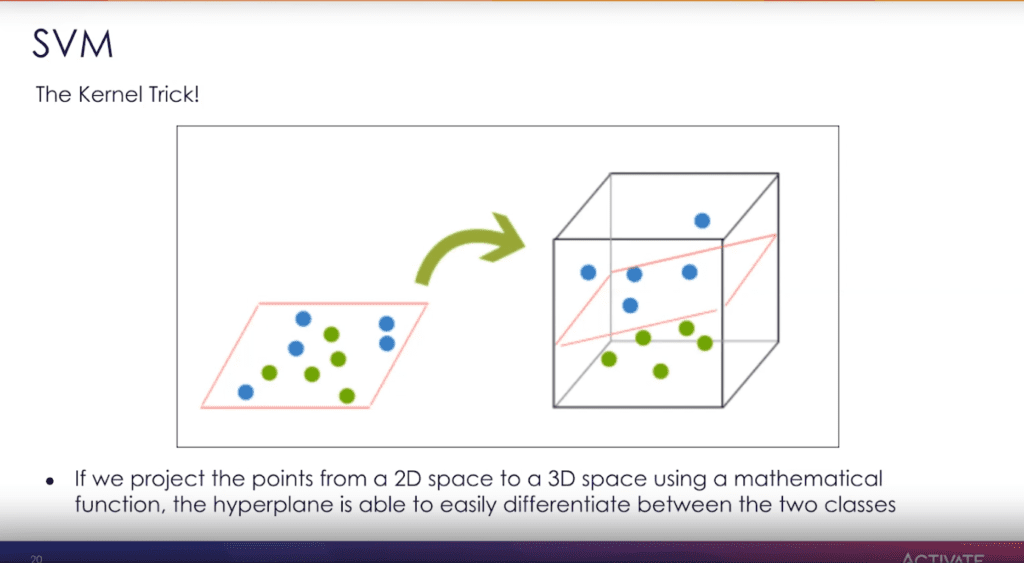
By projecting the points from a 2D space to a 3D space using a mathematical function, the hyperplane is more easily differentiated between the two classes. This is called the Kernel Trick.
So after the data cleaning, after the data vectorization, all these parts come together to deliver impact at the moment of customer need.
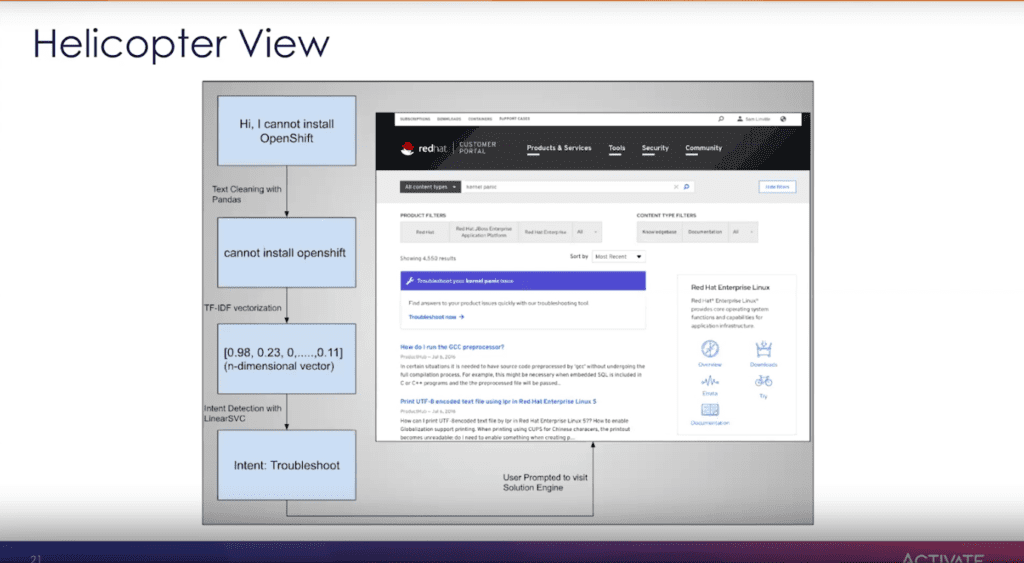
The user enters a search query in the customer portal: I cannot install OpenShift which is cleaned to cannot install openshift and then vectorization calculates that this is a troubleshooting intention and in the search results, in-line, the system prompts the user to go to the troubleshooting tool, the Solution Engine, to continue to self-resolve.
This is how Red Hat used intent classification to influence the customer’s behavior and encourage self-resolution – while still always offering the option to open a support case and engage with an agent.
To measure the business impact of the intent classifier, the team performed multivariate testing and found:
- An 11.6 % reduction in case creation when customers were exposed to the intent classifier and recommendations
- Pageviews and the time spent per visit started to decrease, indicating that the users were finding pertinent content more efficiently because of the troubleshooting experience induced by the intent classifier
Every Red Hat customer comes to their customer portal with different motives and different problems. By identifying the broad high-level intents of these users, the team at Red Hat was able to deliver a better user experience that encouraged self-solve outcomes, reduced opened cases, and increased renewals and retention.