Promoting self-service is a win/win/win. Customers get the answers they want quickly; support engineers, once burdened with mundane cases, can focus on outlier requests that require engineering acumen to resolve; and, often, operational costs see a marked decrease. According to the Harvard Business Review, “self-service offers companies a tantalizing opportunity to reduce spending, often drastically. The cost of a do-it-yourself transaction is measured in pennies, while the average cost of a live service interaction (phone, e-mail, or webchat) is more than $7 for a B2C company and more than $13 for a B2B company.“
So how did Red Hat streamline its data access and varied customer requests to create one of “The Ten Best Web Support Sites,” according to The Association of Support Professionals, for nine years running? By providing an intuitive UX and functional, relevant search using Lucidworks Fusion.
A Self-Service Portal That Understands Intent
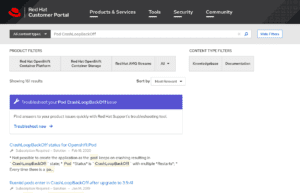
To satisfy their customers’ inclinations, Red Hat made self-service the default and integrated a troubleshooting experience into their standard case creation process.
Leveraging a machine learning model, Red Hat detects the intent behind a user’s search query and drives them to the UI that best supports their resolution efforts. Does the customer want to learn about product usage or troubleshoot a problem? If the model infers that the user is searching an error code, he is sent to a dedicated troubleshooting tool designed to make the experience intuitive.
In order to apply that same intuition to search results, feedback from both customers and support engineers is used to promote relevancy.
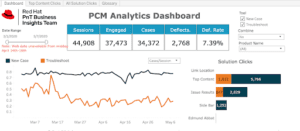
Customer feedback comes from clickstream data extracted from the subscriber’s behavior in the support portal. What article did they click, what pages did they visit, how long did they stay on each page, etc: all of this data is captured and aggregated using Fusion signals.
Support engineer feedback comes when a customer chooses to open a support case rather than self-solve. The support engineer records support case diagnostic data in a structured way, then attaches any of the over 600k documents in the knowledgebase used to solve the case to the record.