

Solr Payloads
Before we delve into the technical details, what’s the big picture? What real-world challenges are made better with these new Solr capabilities? Here’s some use cases where payloads can help:
- per-store pricing
- weighted terms, such as the confidence or importance of a term
- weighting term types, like factoring synonyms lower, or verbs higher
Now on to the technical details, starting with how payloads are implemented in Lucene, and then to Solr’s integration.
Payloads in Lucene
The heart of Solr is powered by our favorite Java library of all-time, Lucene. Lucene has had this payload feature for a while, but hasn’t seen much light of day partly because until now it hasn’t been supported natively in Solr.
Let’s take a moment to refresh ourselves on how how Lucene works, and then show where payloads fit in.
Lucene Index Structure
Lucene builds an inverted index of the content fed to it. An inverted index is, at a basic level, a straightforward dictionary of words from the corpus alphabetized for easy finding later. This inverted index powers keyword searches handily. Want to find documents with “cat” in the title? Simply look up “cat” in the inverted index, and report all of the documents listed that contain that term – very much like looking up words in the index at the back of books to find the referring pages.
Finding documents super fast based off words in them is what Lucene does. We may also require matching words in proximity to one another, and thus Lucene optionally records the position information to allow for phrase matching, words or terms close to one another. Position information provides the word number (or position offset) of a term: “cat herder” has “cat” and “herder” in successive positions.
For each occurrence of an indexed word (or term) in a document, the positional information is recorded. Additionally, and also optionally, the offsets (the actual character start and end offset) can be encoded per term position.
Payloads
Available alongside the positionally related information is an optional general purpose byte array. At the lowest-level, Lucene allows any term in any position to store whatever bytes it’d like in its payload area. This byte array can be retrieved as the term’s position is accessed.
These per-term/position byte arrays can be populated in a variety of ways using some esoteric built-in Lucene TokenFilter‘s, a few of which I’ll de-cloak below.
A payload’s primary use case is to affect relevancy scoring; there are also other very interesting ways to use payloads, discussed here later. Built-in at Lucene’s core scoring mechanism is float Similarity#computePayloadFactor() which until now has not been used by any production code in Lucene or Solr; though to be sure, it has been exercised extensively within Lucene’s test suite since inception. It’s hardy, just under-utilized outside custom expert-level coding to ensure index-time payloads are encoded the same way they are decoded at query time, and to hook this mechanism into scoring.
Payloads in Solr
One of Solr’s value-adds is providing rigor to the fields and field types used, keeping index and query time behavior in sync. Payload support followed along, linking index-time payload encoding with query time decoding through the field type definition.
The payload features described here were added to Solr 6.6, tracked in SOLR-1485.
Let’s start with an end-to-end example…
Solr 6.6 Payload Example
Here’s a quick example of assigning per-term float payloads and leveraging them:
bin/solr start bin/solr create -c payloads bin/post -c payloads -type text/csv -out yes -d $'id,vals_dpfn1,one|1.0 two|2.0 three|3.0n2,weighted|50.0 weighted|100.0'
If that last command gives you any trouble, navigate to http://localhost:8983/solr/#
id,vals_dpf 1,one|1.0 two|2.0 three|3.0 2,weighted|50.0 weighted|100.0
Two documents are indexed (id 1 and 2) with a special field called vals_dpf. Solr’s default configuration provides *_dpf, the suffix indicating it is of “delimited payloads, float” field type.
Let’s see what this example can do, and then we’ll break down how it worked.
The payload() function returns a float computed from the numerically encoded payloads on a particular term. In the first document just indexed, the term “one” has a float of 1.0 encoded into its payload, and likewise “two” with the value of 2.0, “three” with 3.0. The second document has the same term, “weighted” repeated, with a different (remember, payloads are per-position) payload for each of those terms’ positions.
Solr’s pseudo-fields provide a useful way to access payload function computations. For example, to compute the payload function for the term “three”, we use payload(vals_dpf,three). The first argument is the field name, and the second argument is the term of interest.http://localhost:8983/solr/
id,p 1,3.0 2,0.0
The first document has a term “three” with a payload value of 3.0. The second document does not contain this term, and the payload() function returns the default 0.0 value.
Using the above indexed data, here’s an example that leverages all the various payload() function options:
id,def,first,min,max,avg 2,37.0,50.0,50.0,100.0,75.0
There’s a useful bit of parameter substitution indirection to allow the field name to be specified as
f=vals_dpfonce and referenced in all the functions. Similarly, the termweightedis specified as the query parametertand substituted in the payload functions.
Note that this query limits to q=id:2 to demonstrate the effect with multiple payloads involved. The fl expression def:payload($f,not_there,37) finds no term “not_there” and returns the specified fall-back default value of 37.0, and avg:payload($f,$t,0.0,average) takes the average of the payloads found on all the positions of the term “weighted” (50.0 and 100.0) and returns the average, 75.0.
Indexing terms with payloads
The default (data_driven) configuration comes with three new payload-using field types. In the example above, the delimited_payloads_float field type was used, which is mapped to a *_dpf dynamic field definition making it handy to use right away. This field type is defined with a WhitespaceTokenizer followed by a DelimitedPayloadTokenFilter. Textually, it’s just a whitespace tokenizer (case and characters matter!). If the token ends with a vertical bar (|) delimiter followed a floating point number, the delimiter and number are stripped from the indexed term and the number encoded into the payload.
Solr’s analysis tool provides introspection into how these delimited payloads field types work. Using the first document in the earlier example, keeping the output simple (non-verbose), we see the effect of whitespace tokenization followed by delimited payload filtering, with the basic textual indexing of the term being the base word/token value, stripping off the delimiter and everything following it. Indexing-wise, this means the terms “one”, “two”, and “three” are indexed and searchable with standard queries, just as if we had indexed “one two three” into a standard text field.

Looking a little deeper into the indexing analysis by turning on verbose view, we can see in the following screenshot a hex dump view of the payload bytes assigned to each term in the last row labeled “payload”.
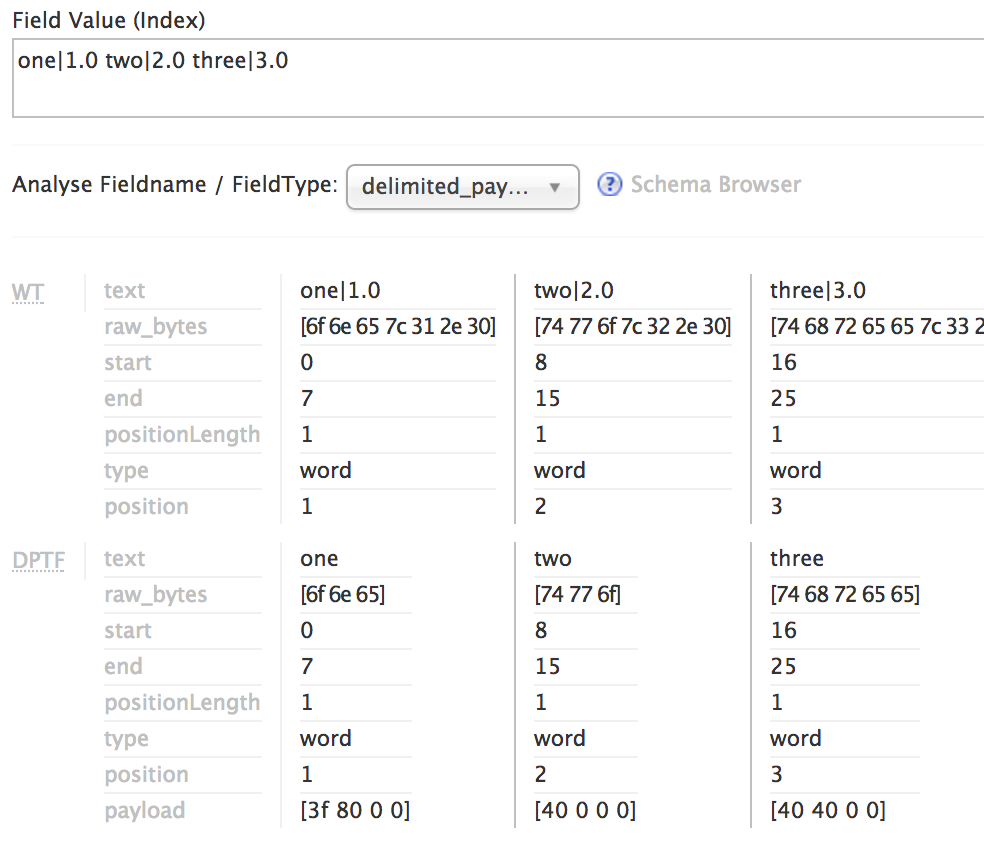
Payloaded field types
These new payloaded field types are available in Solr’s data_driven configuration:
| field type | payload encoding | dynamic field mapping |
delimited_payloads_float | float | *_dpf |
delimited_payloads_int | integer | *_dpi |
delimited_payloads_string | string, as-is | *_dps |
Each of these is whitespace tokenized with delimited payload filtering, the difference being the payload encoding/decoding used.
payload() function
The payload() function, in the simple case of unique, non-repeating terms with a numeric (integer or float) payload, effectively returns the actual payload value. When the payload() function encounters terms that are repeated, it will either take the first value it encounters, or iterate through all of them returning the minimum, maximum, or average payload value.
The payload() function signature is this:
payload(field,term[,default, [min|max|average|first]])
where the defaults are 0.0 for the default value, and for averaging the payload values.
Back to the Use Cases
That’s great, three=3.0, and the average of 50.0 and 100.0 is 75.0. Like we needed payloads to tell us that. We could have indexed a field, say words_t with “three three three” and done termsfreq(words_t,three) and gotten 3 back. We could have fields min_f set to 50.0 and max_f set to 100.0 and used div(sum(min_f,max_f),2) to get 75.0.
Payloads give us another technique, and it opens up some new possibilities.
Per-store Pricing
Business is booming, we’ve got stores all across the country! Logistics is hard, and expensive. The closer a widget is made to the store, the less shipping costs; or rather, it costs more for a widget the further it has to travel. Maybe not so contrived rationale aside, this sort of situation with per-store pricing of products is how it is with some businesses. So, when a customer is browsing my online store they are associated with their preferred or nearest physical store, where all product prices seen (and faceted and sorted don’t forget!) are specific to the pricing set up for that store for that product.
Let’s whiteboard that one out and be pragmatic about the solutions available: if you’ve got five stores, maybe have five Solr collections even with everything the same but the prices? What if there are 100 stores and growing, managing that many collections becomes a whole new level of complexity, so then maybe have a field for each store, on each product document? Both of those work, and work well…. to a point. There are pro’s and con’s to these various approaches. But what if we’ve got 5000 stores? Things get unwieldy with lots of fields due Solr’s caching and per-field machinery; consider one user from each store region doing a search with sorting and faceting, multiplying a traditional numeric sorting requirement times 5000. Another technique that folks implement is to cross products with stores and have a document for every store-product, which is similar to a collection per store but very quickly explodes to lots of documents (num_stores * num_products can be a lot!). Let’s see how payloads gives us another way to handle this situation.
Create a product collection with bin/solr create -c products and then CSV import the following data; using the Documents tab in CSV mode is easiest, paste in this and submit:
id,name,default_price_f,store_prices_dpf SB-X,Snow Blower,350.37,STORE_FL|275.99 AC-2,Air Conditioner,499.50,STORE_AK|312.99
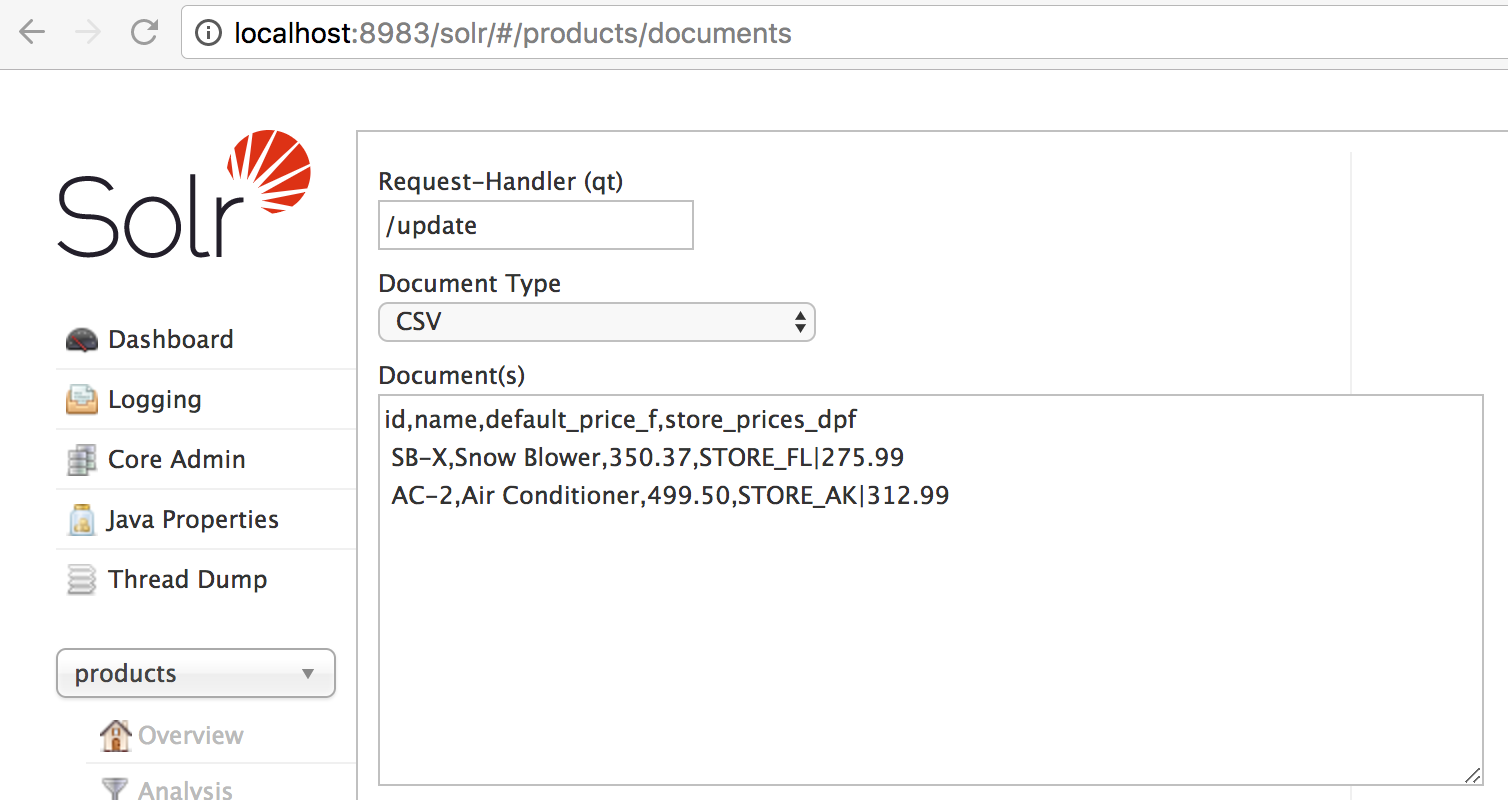
I stuck with dynamic field mappings to keep things working easily out of the box in this example, but I’d personally use cleaner names for real such as default_price instead of default_price_fandstore_prices instead of store_prices_dpf.
Let’s find all products, sorted by price, first by default_price_f: http://localhost:8983/
In Alaska, though, that’s not the correct sort order. Let’s associate the request with STORE_AK, using &store_id=STORE_AK, and see the computed price based on the payload associated with the store_id for each product document with &computed_price=payload(store_prices_dpf,$store_id,default_price_f). Note that those two parameters are ours, not Solr’s. With a function defined as a separate parameter, we can re-use it where we need it. To see the field, add it to fl with &fl=actual_price:${computed_price}, and to sort by it, use &sort=${computed_price} asc.
Circling back to the approaches with per-store pricing as if we had 5000 stores. 5000*number_of_products documents versus 5000 collections versus 5000 fields versus 5000 terms. Lucene is good at lots of terms per field, and with payloads along for the ride it’s a good fit for this many-value-per-document scenario.
Faceting on numeric payloads
Faceting is currently a bit trickier with computed values, since facet.range only works with actual fields not pseudo ones. In this price case, since there aren’t usually many price ranges needed we can use facet.query‘s along with {!frange} on the payload(). With the example data, let’s facet on (computed/actual) price ranges. The following two parameters define two price ranges:
facet.query={!frange key=up_to_400 l=0 u=400}${computed_price}(includes price=400.00)facet.query={!frange key=above_400 l=400 incl=false}${computed_price}(excludes price=400.00, with “include lower” incl=false)
Depending on which store_id we pass, we either have both products in the up_to_400 range (STORE_AK) or one product in each bucket (STORE_FL). The following link provides the full URL with these two price range facets added: /products/query?…
Here’s the price range facet output with store_id=STORE_AK:
facet_queries: {
up_to_400: 2,
above_400: 0
} Weighted terms
This particular use case is implemented exactly as the pricing example, using whatever terms appropriate instead of store identifiers. This could be, for example, useful for weighting the same words differently depending on the context in which they appear – words being parsed into an <H1> html tag could be assigned a payload weight greater than other terms. Or perhaps during indexing, entity extraction can assign confidence weights about the confidence of the entity choice.
To assign payloads to terms using the delimited payload token filtering, the indexing process will need to craft the terms in the “term|payload” delimited fashion.
Synonym weighting
One technique many of us have used is the two-field copyField trick where one field has synonyms enabled, and another without synonym filtering, and using query fields (edismax qf) to weight the non-synonym field higher than the synonym field allowing closer to exact matches a relevancy boost.
Instead, payloads can be used to down-weight synonyms within a single field. Note this is an index-time technique with synonyms, not query-time. The secret behind this comes from a handy analysis component called NumericPayloadTokenFilterFactory – this handy filter assigns the specified payload to all terms matching the token type specified, “SYNONYM” in this case. The synonym filter injects terms with this special token type value; token type is generally ignored and not indexed in any manner, yet being useful during the analysis process to key off of for other operations like this trick of assigning a payload to only certain tagged tokens.
For demonstration purposes, let’s create a new collection to experiment with: bin/solr create -c docs
There’s no built-in field type that has this set up already, so let’s add one:
curl -X POST -H 'Content-type:application/json' -d '{
"add-field-type": {
"name": "synonyms_with_payloads",
"stored": "true",
"class": "solr.TextField",
"positionIncrementGap": "100",
"indexAnalyzer": {
"tokenizer": {
"class": "solr.StandardTokenizerFactory"
},
"filters": [
{
"class": "solr.SynonymGraphFilterFactory",
"expand": "true",
"ignoreCase": "true",
"synonyms": "synonyms.txt"
},
{
"class": "solr.LowerCaseFilterFactory"
},
{
"class": "solr.NumericPayloadTokenFilterFactory",
"payload": "0.1",
"typeMatch": "SYNONYM"
}
]
},
"queryAnalyzer": {
"tokenizer": {
"class": "solr.StandardTokenizerFactory"
},
"filters": [
{
"class": "solr.LowerCaseFilterFactory"
}
]
}
},
"add-field" : {
"name":"synonyms_with_payloads",
"type":"synonyms_with_payloads",
"stored": "true",
"multiValued": "true"
}
}' http://localhost:8983/solr/docs/schema With that field, we can add a document that will have synonyms assigned (the out of the box synonyms.txt contains Television, Televisions, TV, TVs), again adding it through the Solr admin Documents area, for the docs collection just created using Document Type CSV:
id,synonyms_with_payloads 99,tv
Using the {!payload_score} query parser this time, we can search for “tv” like this: http://localhost:8983/solr/docs/select?
which returns:
id,score 99,1.0
Changing &payload_term=television reduces the score to 0.1.
This term type to numeric payload mapping can be useful beyond synonyms – there are a number of other token types that various Solr analysis components can assign, including <EMAIL> and <URL>tokens that UAX29URLEmailTokenizer can extract.
Payload-savvy query parsers
There are two new query parsers available that leverage payloads, payload_score and payload_check. The following table details the syntax of these parsers:
| query parser | description | specification |
{!payload_score} | SpanQuery/phrase matching, scores based on numerically encoded payloads attached to the matching terms | |
{!payload_check} | SpanQuery/phrase matching that have a specific payload at the given position, scores based on SpanQuery/phrase scoring | |
Both of these query parsers tokenize the query string based on the field type’s query time analysis definition (whitespace tokenization for the built-in payload types) and formulates an exact phrase (SpanNearQuery) query for matching.
{!payload_score} query parser
The {!payload_score} query parser matches on the phrase specified, scoring each document based on the payloads encountered on the query terms, using the min, max, or average. In addition, the natural score of the phrase match based off the usual index statistics for the query terms can be multiplied into the computed payload scoring factor using includeSpanScore=true.
{!payload_check} query parser
So far we’ve focused on numeric payloads, however strings (or raw bytes) can be encoded into payloads as well. These non-numeric payloads, while not usable with the payload() function intended solely for numeric encoded payloads, they can be used for an additional level of matching.
Let’s add another document to our original “payloads” collection using the *_dps dynamic field to encode payloads as strings:
id,words_dps 99,taking|VERB the|ARTICLE train|NOUN
The convenient command-line to index this data is:
bin/post -c payloads -type text/csv -out yes -d $'id,words_dpsn99,taking|VERB the|ARTICLE train|NOUN'
We’ve now got three terms, payloaded with their part of speech. Using {!payload_check}, we can search for “train” and only match if it was payloaded as “NOUN”:
q={!payload_check f=words_dps v=train payloads=NOUN} if instead payloads=VERB, this document would not match. Scoring from {!payload_check} is the score of the SpanNearQuery generated, using payloads purely for matching. When multiple words are specified for the main query string, multiple payloads must be specified, and match in the same order as the specified query terms. The payloads specified must be space separated. We can match “the train” in this example when those two words are, in order, an ARTICLE and a NOUN:
q={!payload_check f=words_dps v='the train' payloads='ARTICLE NOUN'} whereas payloads='ARTICLE VERB' does not match.
Conclusion
The payload feature provides per-term instance metadata, available to influence scores and provide additional level of query matching.
Next steps
Above we saw how to range facet using payloads. This is less than ideal, but there’s hope for true range faceting over functions. Track SOLR-10541 to see when this feature is implemented.
Just after this Solr payload work was completed, a related useful addition was made to Lucene to allow term frequency overriding, which is a short-cut to the age-old repeated keyword technique. This was implemented for Lucene 7.0 at LUCENE-7854. Like the payload delimiting token filters described above, there’s now also a DelimitedTermFrequencyTokenFilter. Payloads, remember, are encoded per term position, increasing the index size and requiring an additional lookup per term position to retrieve and decode them. Term frequency, however, is a single value for a given term. It’s limited to integer values and is more performantly accessible than a payload. The payload() function can be modified to transparently support integer encoded payloads and delimited term frequency overrides (note: the termfreq() function would work in this case already). Track SOLR-11358 for the status of the transparent term frequency / integer payload() implementation.
Also, alas, there was a bug reported with debug=true mode when using the payload() when assertions are enabled. A fix is on the patch at SOLR-10874, included from 7.2 onward.