Using Word2Vec in Fusion For Better Search Results
Introduction
The power to have a computer process information the same way a human does has countless applications, but the area in which it is possibly most important is search. The ability to interface with technology in a natural and intuitive way increases search traffic, facilitates ease of querying and, most importantly, gives people what they want… accurate results! But, while it’s clear that Natural Language Processing (NLP) is crucial for good search, actually teaching a computer to understand and mimic natural speech is far easier said than done.
That previous sentence itself is a great example of why that is. The human brain is an efficient language processing engine because humans have access to years of context for all types of speech. Human brains can call upon this context to identify, interpret, and respond to complicated speech patterns including jokes, sarcasm and, as in the case of the of the previous paragraph, bad puns. Computers, on the other hand, have no inherent context and so must be taught which words are associated with which others and what those associations imply. Simply encoding all types of speech patterns into a computer, however, is a virtually endless process. We have had to develop a better way to teach a computer to talk and read like a human.
Enter Word2Vec1. Word2Vec is a powerful modeling technique commonly used in natural language processing. Standard Word2Vec uses a shallow neural network2 to teach a computer which words are “close to” other words and in this way teaches context by exploiting locality. The algorithm proceeds in two steps, Training and Learning. A rough overview of these steps is as follows.
The Algorithm
Training
To train a computer to read we must first give it something to read from. The first step of training the Word2Vec model supplies the algorithm with a corpus of text. It’s important to note that the computer will only be learning context from the input text that we provide it. So, if we provide an obscure training text the model will learn obscure and possibly outdated associations. It is very important that we supply the model with a comprehensive and modern corpus of text.
Each word in the input text gets converted to a position vector, which corresponds to the word’s location in the input text. In this way, the entire training set gets converted to a high dimensional vector space. Below is a trivial example example of what a 2d projection of this vector space might look like for the sentences “Bob is a search engineer. Bob likes search” (removing the stopwords3 ‘is’ and ‘a’ for simplicity)
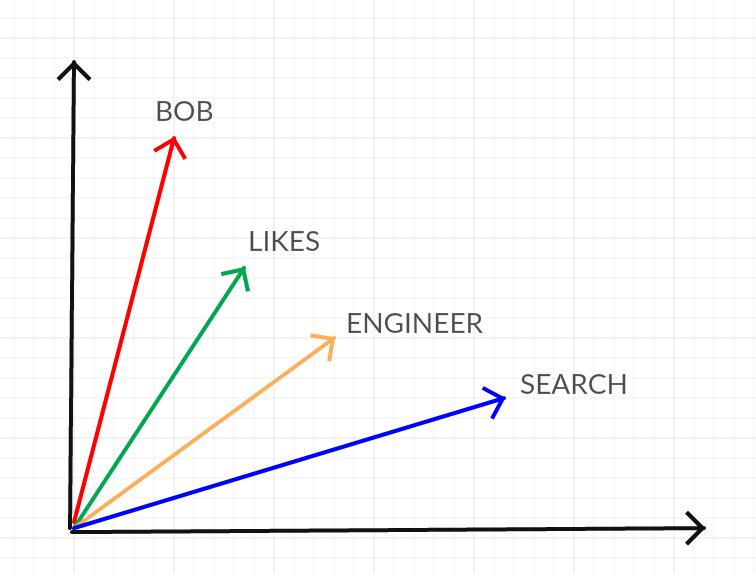
This vector space then gets passed to the learning step of the algorithm.
Learning
Now that we have converting our text into a vector space we can start learning which words are contextually similar in our input text.
To do this, the algorithm uses the corpus of text to determine which words occur close to one another. For example, in the above example of “Bob is a search engineer. Bob likes search” the words “Bob” and “search” occur together twice. Since the two words occurred together more than once, it is likely they are related. To reflect this idea the algorithm will move the vector corresponding to “Bob” closer to the vector corresponding to “search” in the high dimensional space. A 2d projection of this process is illustrated below.
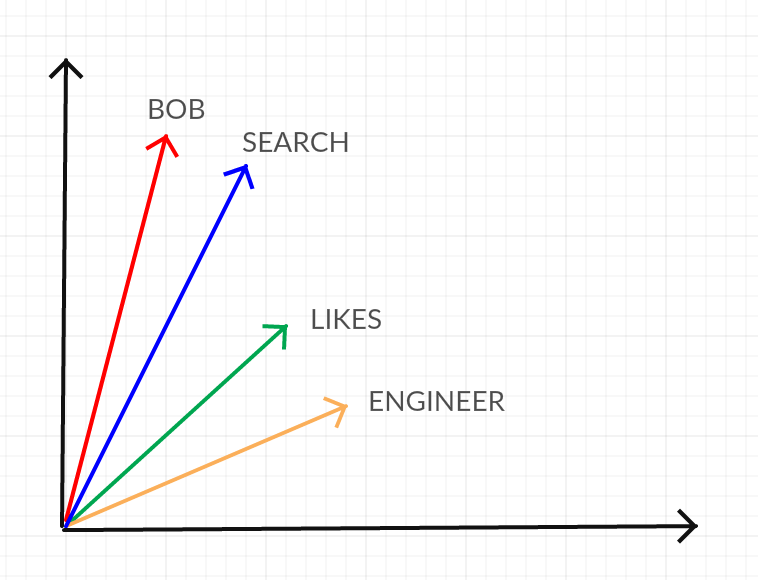
In this way Word2Vec tweaks “nearby words” to have “nearby vectors” and so each word in the corpus of text moves closer to the words it co occurs with.
Word2Vec can use one of two algorithms to learn context: Continuous Bag of Words4 (or CBOW) and SkipGram5 . CBOW seeks to predict a target word from its context while SkipGrams seeks to predict the context given a target word.
Both algorithms employ this vector moving strategy. The slight distinction between the two algorithms is the way in which the vectors are moved. In CBOW we seek to predict a word from its context and so we consider the entire corpus of text in “windows” of a single word and its corresponding context vectors. In the case of, “Bob is a search engineer. Bob likes search.” We would be considering something like below,

Each of the context word vectors serve as the input to a 2 layer neural network. The single word “search” serves as the intended output layer. The internal hidden layer of the network corresponds to the manipulations occurring in the vector space to push each of the context vectors nearer to the word.
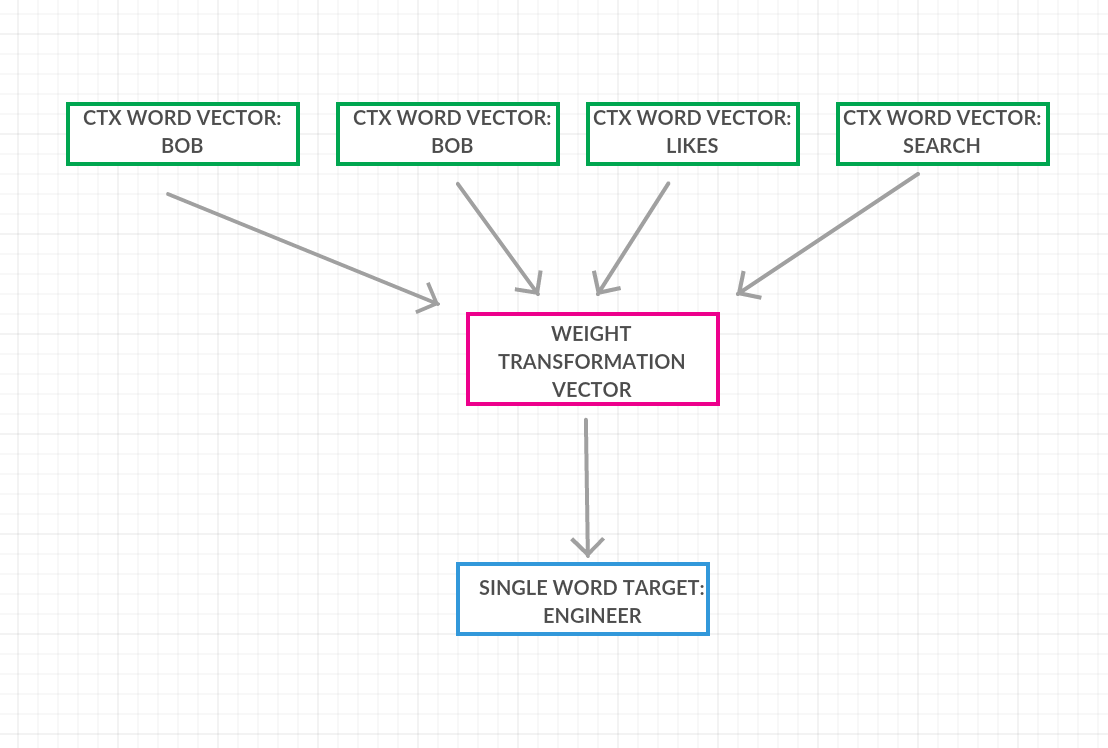
There is one disadvantage to this method. We are taking the context for each given word to be the n words surrounding it. Since each word gets considered to be a context word multiple times we are effectively averaging the the context words in the hidden layer of the neural network and then moving the target vector closer to this average. This may unwittingly cause us to lose some distributional information about the space.
The alternative technique is skip grams which does effectively the opposite of CBOW. Given a specific word skip grams strives to discover the associated context. The 2 layer neural network for skip grams uses the target word as input and trains the weights such that the nearest vectors are the context to that word.

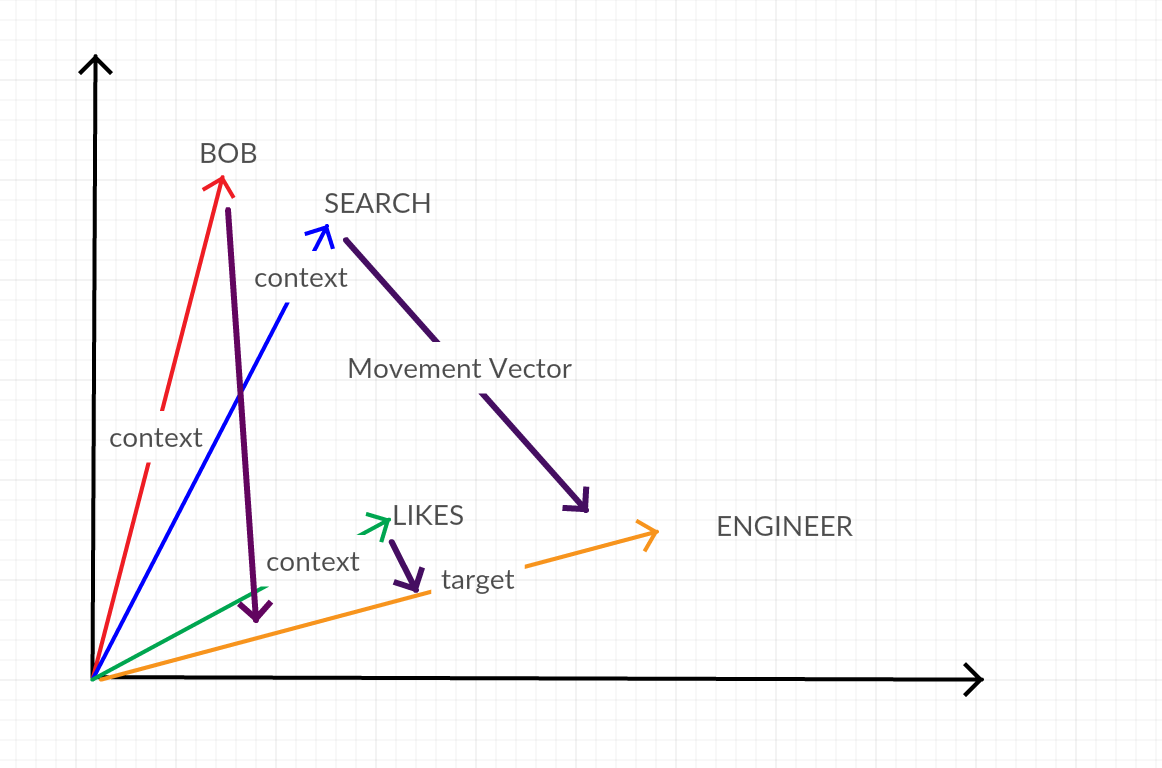
In this case there is no need to average the context vectors. The hidden layer simply maps the target word to the n context words. So, instead of moving the target towards the average of the context vectors (as we do in CBOW) we are simply moving all of the context vectors closer to the target. A 2d projection of these two techniques is below with engineer as the Target Word and “Bob”, Search and Likes as the Context Words.
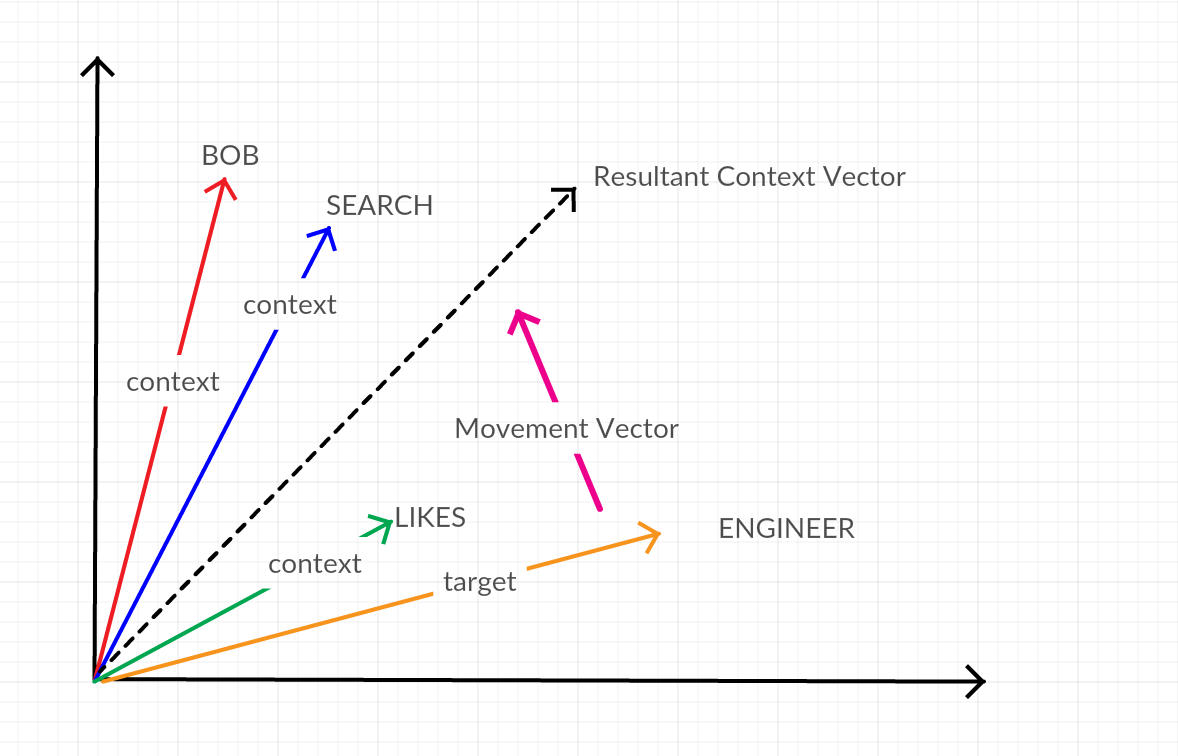
Using in Lucidworks Fusion
Word2Vec has huge applications for automatic synonym and category discovery in large unlabeled datasets. This makes it an useful tool to supplement the existing textual analysis capabilities of Lucidworks Fusion6. Our implementation leverages Apache Spark’s ML Library, which has a convenient implementation of the skip-grams technique7 .
We will be analyzing the Apache projects8 for our input corpus of text. Employing this technique in Lucidworks Fusion has further complications because each mailing list or project configuration coming from Apache is split into ‘documents’ in Fusion. This means generated synonyms will be for the entire corpus of text and not necessarily for the words in each document. To circumvent this problem we train the model on the entire set of documents. We then employ TF-IDF on each individual document to determine which words in the document are the “most important” and query the Word2Vec model for synonyms of those important terms. The effectively generates a topics list for each document in Fusion.
Our preliminary results were subpar because our initial pass through the data employed only minimal stopword removal. In Word2Vec, if certain words are frequently followed or preceded by stop words the algorithm will treat those stop words as important pieces of context whereas in reality they do not provide valuable information.
After more comprehensive stopwords removal we began to see much more reasonable results. For example, for an email thread discussing Kerberos9 (an authentication protocol) the results were as follows.

These are accurate and relevant synonyms to the subject of the email.
Not all the associations are completely accurate however, as evidenced by the next example. The source was an email concerning JIRA issues.

For some context Alexey and Tim are two major Fusion contributors and so it makes sense that they should have high association with a JIRA related email chain. Atlassian, administrators, fileitems, tutorials and architecture are all also reasonable terms to be related to the issue. Donuts, however, is almost completely random (unless Alexey and Tim are bigger fans of Donuts then I realized).
Conclusion
If you want to explore our Word2Vec example for yourself we have implemented Word2Vec as a Fusion plugin in Lucidworks’ demo site, Searchhub.
You can also play around with the plug in on your own data. Just download the plugin, crawl some data, train the model by running the word2vec Spark job and recrawl the data to see the related terms to the “most important terms” for each document. These fields can then be searched against to offer query expansion capabilities, or faceted upon to automatically ‘tag’ each document with its general description.
Word2Vec offers a powerful way to classify and understand both documents and queries. By leveraging the power of Apache Spark ML Word2Vec within Fusion we at Lucidworks are able to offer you this unique insight into your data.