Beschleunigen Sie die Time to Value für die Informationsbeschaffung mit KI
„Von 0 auf 60“ ist eine der wichtigsten Angaben in der Autoindustrie. Tesla hat diese Spezifikation mit einem großartig aussehenden Elektroauto kombiniert, und dieses Paket ist der Gipfel des Wertes in der Autowelt geworden. Lassen Sie uns nun über das Sucherlebnis nachdenken und darüber, was wir in diesem speziellen Bereich für den Höhepunkt des Wertes halten. Da fallen mir sofort die Erfahrungen von Google (allgemeine Suche) und Amazon (E-Commerce) ein. Sie sind die frühen Marktteilnehmer, die etablierten Unternehmen, und sie sind aufgrund der Menge an Daten, die sie sammeln, der Zeit voraus. Diese Daten führen dazu, dass die Intelligenz des Erlebnisses immer ausgefeilter wird.
Alle Unternehmen möchten ihren Suchnutzern das gleiche Erlebnis bieten, aber sie alle haben mit einem einzigartigen, mehrdimensionalen Kaltstartproblem zu kämpfen.
Überwindung des Kaltstartproblems
Kaltstartprobleme stellen die meisten Herausforderungen dar , mit denen Unternehmen konfrontiert sind, wenn es darum geht, die besten Geschäftsergebnisse für das Information Retrieval (IR) zu erzielen, und zwar in einer beschleunigten Weise und mit dem geringsten Aufwand. Die Ursachen für die Kaltstartprobleme können je nach Unternehmen unterschiedlich sein und umfassen
- Fehlendes – oder sehr geringes – historisches Nutzerverhalten für die Suche
- Manuelle Prozesse zur Anreicherung von Domänendaten
- Nicht genügend internes Fachwissen im Bereich Datenwissenschaft
- Unzusammenhängende Übergaben zwischen den Personen, die für die Entwicklung leistungsstarker Suchanwendungen benötigt werden (Suchingenieure, Datenwissenschaftler, Betrieb, IT usw.)
Aufgrund unserer Erfahrung mit Hunderten von Kunden weiß Lucidworks, dass die Beschleunigung der Time-to-Value durch den Umgang mit den Dimensionen des Kaltstartproblems der Schlüssel zu besseren Geschäftsergebnissen ist. Unser Fokus liegt vor allem auf dem gezielten Einsatz von KI zur Beschleunigung der Time-to-Value in den folgenden Funktionsbereichen: Datenkuratierung und -anreicherung, Abfrageverständnis und Relevanzabstimmung.
Intelligente IR ist als ein sich entwickelndes Konzept gedacht. Es ist ein Kreislauf der kontinuierlichen Verbesserung, der von selbst lernt und sich anpasst, aber auch von Fachleuten auf die sich ändernden Geschäftsziele ausgerichtet werden kann. Bei Lucidworks sind wir davon besessen, diesen Kreislauf für die an der Suchkuration beteiligten Personen zu schließen und ihnen dabei zu helfen, die Verbesserung der Relevanz durch Zusammenarbeit und den Einsatz aller ihnen zur Verfügung stehenden Ressourcen (Daten, Workflows und KI-Methoden) zu beschleunigen – sowohl intern als auch in der Branche.
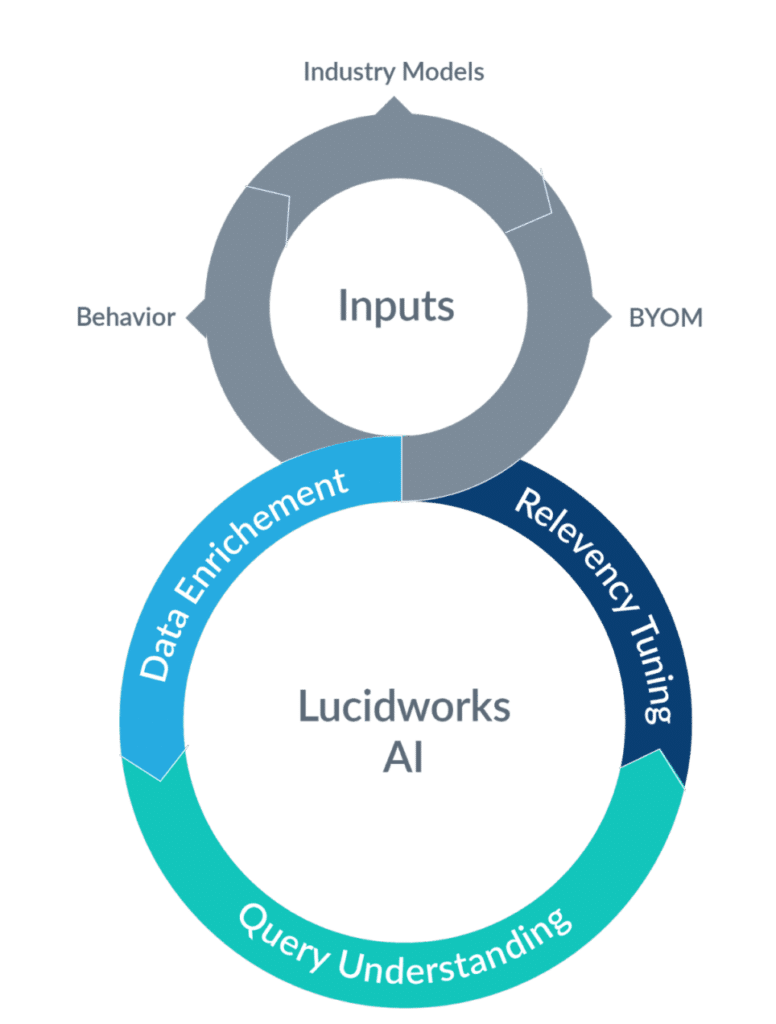
Wir werden auf jede Komponente im Detail eingehen und darüber sprechen, wie wir unsere Kunden bei dem allgegenwärtigen Problem des Kaltstarts unterstützen.
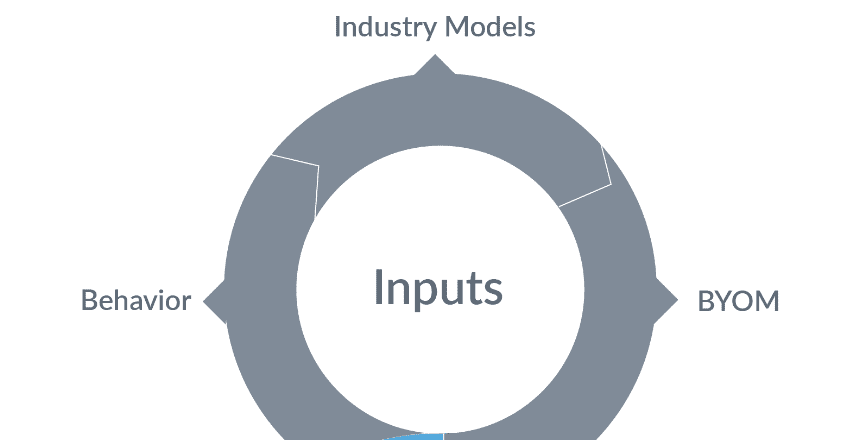
1. Das gesamte verfügbare Wissen
Um im Bereich der Personalisierung konkurrieren zu können, müssen Unternehmen das gesamte ihnen zur Verfügung stehende Wissen nutzen. Dazu gehören Populationen/Segmente/Nutzerverhalten, KI-Methoden und -Modelle, die in der Branche bereits weit verbreitet sind, und die Möglichkeit, ihre eigenen entwickelten Modelle in die Suchplattform zu integrieren. Als IR-Partner ist die Lucidworks-Plattform so konzipiert, dass sie die Integration dieser Ressourcen in die für die Dateneingabe und -abfrage erforderlichen Prozesse über leistungsstarke workflowbasierte Pipelines erleichtert.
Signale und Verhalten
Signale bestehen aus dem gesamten Nutzerverhalten, das durch eine Suchaktivität ausgelöst wird. Sie können Ereignisse wie Klicks, Anmerkungen, Anfragen, Antworten, Aktionen (z. B. in den Warenkorb legen oder kaufen), Teilen usw. umfassen. KI nutzt Signale, um die Verarbeitung von Suchanfragen zu verbessern und sie für die Suchmaschine neu zu interpretieren (umzuschreiben), die Ergebnisse auf der Grundlage früherer Aktivitäten zu personalisieren (Boosten von Ergebnissen) und uns zu helfen, Empfehlungen zu verbessern. Der Mangel an Signaldaten ist eine der Hauptursachen für Kaltstartprobleme bei der Suche. Unsere KI-Methoden sind so konzipiert, dass sie in Ermangelung von Signalen sofortigen Nutzen bringen und schrittweise verbessert und verfeinert werden, wenn Signale verfügbar werden.
Industrie-Modelle
Das wirklich Positive an den großen Daten- und Sozialplattformen (Google, Amazon, Facebook usw.) ist, dass sie sich an der Spitze der Forschung befinden und auch viel zu den Open-Source-Communities beitragen. Sie nutzen ihre riesigen Datenmengen, um vortrainierte Modelle in den Bereichen Deep Learning für die Verarbeitung natürlicher Sprache (NLP), Verstehen (NLU) und Generierung (NLG) zu erstellen und zu veröffentlichen. Wir bei Lucidworks haben den Wert der Integration dieser Modelle direkt in die Plattform erkannt und können so unseren Kunden helfen, das Problem des Kaltstarts zu lösen.
Bring-Your-Own-Modelle
Lucidworks hat schon früh erkannt, dass es von großem Vorteil ist, wenn Unternehmen über sehr ausgeprägte Domaindaten verfügen und in ihre Data-Science-Fähigkeiten investieren, um eigene Modelle zu erstellen. Wir ermöglichen diese Modelle und fördern die Anschlussfähigkeit an unsere Data-Science-Expertise, um den Erfolg zu steigern. Die innovative servicebasierte Architektur von Fusion ermöglicht es Data-Science-Teams, ihre Fähigkeiten ohne Unterbrechung, Dev-Ops-Prozesse oder Infrastrukturänderungen zu erweitern oder zu verbessern. Die fehlende Integration zwischen Data Science und Suchoperationen kann ein Problem des Kaltstarts sein, das Lucidworks mit dieser Bring-your-own-Models-Fähigkeit beheben will.
2. Datenanreicherung
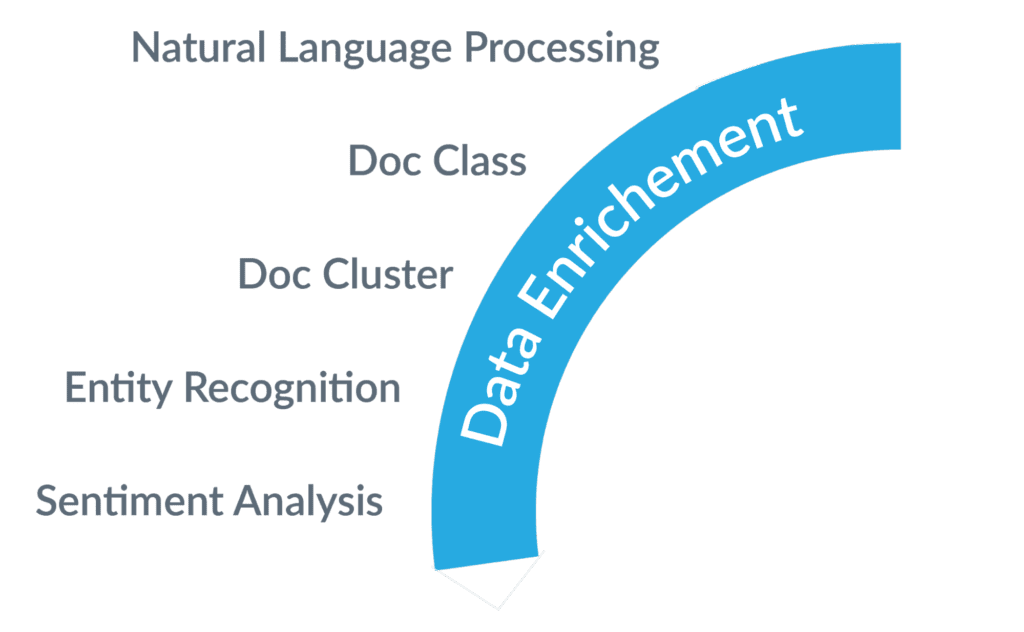
Die Datenkuratierung und -anreicherung kann ein Hindernis für eine schnelle Implementierung sein, da die Domänenkuratierung der Daten manuell erfolgt. Wir haben in der Vergangenheit Erfahrungen gemacht, insbesondere im Bereich des Wissensmanagements in Unternehmen, bei denen das Eigentum an den Datendomänen nicht bei den Suchmaschinenbetreibern lag und die fehlende Domänenanreicherung der Daten einen negativen Einfluss auf die Suchrelevanz hatte. Wir sind der Meinung, dass die Automatisierung der Datenanreicherung durch den Einsatz von fortschrittlicher natürlicher Sprachverarbeitung (NLP) und KI die Suche beschleunigt, indem sie die für die Datenkuratierung erforderlichen Anstrengungen angeht. Ohne angereicherte Daten wird die Art und Weise, wie Suchingenieure das Verständnis von Suchanfragen und die Abstimmung der Relevanz angehen, eingeschränkt.
Verarbeitung natürlicher Sprache
NLP ist der Eckpfeiler von IR. Sie ist im Daten-Workflow allgegenwärtig, und zwar vor allem bei der Datenaufnahme und -vorverarbeitung. Spracherkennung, fortgeschrittenes Parsing, Tokenisierung, Lemmatisierung, Decompounding und Part-of-Speech (POS)-Erkennung werden mit den besten linguistischen Methoden und Workflows(Index-Pipelines) durchgeführt. Weitere Informationen finden Sie in unseren Advanced Linguistic Packages.
Dokument-Klassifizierung
Die Dokumentenklassifizierung ist eine Technik des maschinellen Lernens (ML), die analysiert, wie vorhandene Dokumente kategorisiert sind, und dann ein Klassifizierungsmodell erstellt, das zur Vorhersage der Kategorien neuer Dokumente zum Zeitpunkt der Indexierung verwendet werden kann. Die Integration dieses Fachwissens in automatisierte Klassifizierungsprozesse ist eine Möglichkeit, das Problem des Kaltstarts zu lösen und den manuellen Prozess des Domain-Tagging zu minimieren.
Clustering von Dokumenten
Das Clustering von Dokumenten ist eine Methode, mit der eine Reihe von Dokumenten geclustert wird und die es dem Benutzer ermöglicht, zu verstehen, wie sich Dokumente auf natürliche Weise gruppieren. Clustering ermöglicht dem Benutzer im Allgemeinen einen Moment der Erkundung und hilft ihm, Dokumente zu entdecken, die Ausreißer im Wissensbestand sind.
Extraktion von Entitäten
Mit ML extrahieren wir automatisch interessante Elemente aus Dokumenten. Personen, Orte, Organisationen, Daten – all dies sind Beispiele für wichtige Elemente, die Benutzer benötigen, wenn sie Dokumente durchsuchen. Sie können bei der Optimierung von Suchergebnissen nachgeschaltet werden. Unser Advanced Language Package unterstützt 21 Sprachen und extrahiert 29 Entitätstypen und mehr als 450 Untertypen, und zwar sofort.
Stimmungsanalyse
Die Sentiment-Analyse ist die Interpretation von Abfragen oder Dokumenten, die dabei hilft, durch maschinelles Lernen festzustellen, ob sie positiv oder negativ sind. Die Sentiment-Analyse erstellt ein Sentiment-Modell, das Fusion für die Sentiment-Vorhersage bei der Datenaufnahme oder bei der Abfrage verwenden kann. Die Sentiment-Analyse kann mit vortrainierten Branchenmodellen implementiert werden, die qualitativ hochwertige Sentiment-Vorhersagen für eine Vielzahl von Domänen bieten.
3. Abfrage verstehen
Der Schlüssel zur Bereitstellung relevanter Ergebnisse liegt darin, die Absicht der Benutzer zu verstehen, indem die Abfrage intelligent interpretiert wird. Die Anbieter des IR-Dienstes haben die „Kontrolle“ über die indizierten Daten (Produktkataloge, Webseiten, Dokumente). Diese Anbieter können die Daten bereits vor dem Auslösen des Suchvorgangs bearbeiten und erweitern.
Die eingehenden Abfragen von Nutzern sind dagegen viel weniger leicht zu kontrollieren. Wir müssen so viel Intelligenz und Automatisierung wie möglich einsetzen, um die eingehende Anfrage zu interpretieren, zu verstehen, zu ergänzen und/oder zu modifizieren, um die besten Ergebnisse zu erzielen. All dies muss in einer Reaktionszeit von weniger als einer Sekunde geschehen, um dem Benutzer ein optimales Sucherlebnis zu bieten. Die Modelle müssen leistungsfähig sein, durch Domänenregeln und Überschreibungen erweitert werden und außerdem so konzipiert sein, dass sie in Millisekunden dargestellt werden können.
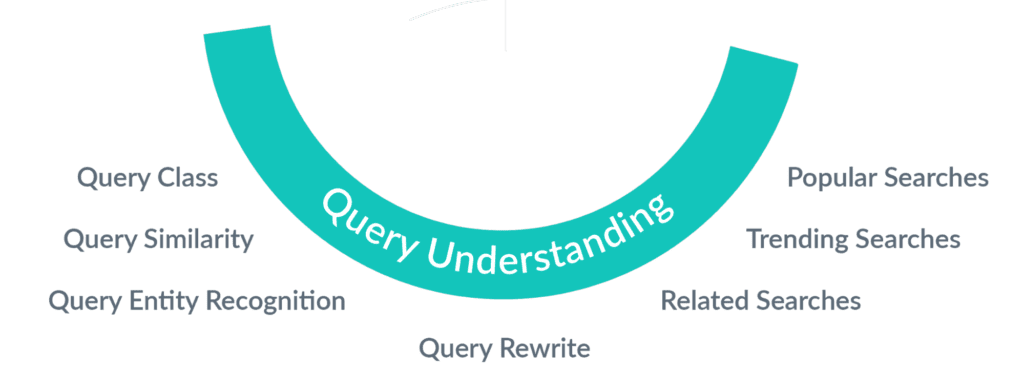
Umformulierung von Abfragen
Query Rewriting ist eine Strategie zur Verbesserung der Relevanz durch die Verwendung von KI-generierten Regeln für die Interpretation von Suchanfragen auf der Grundlage von Signalen. Die Funktionen von Fusion AI werden verwendet, um eingehende Suchanfragen umzuschreiben, bevor sie an die Suchmaschine übermittelt werden. Diese Neuformulierung führt zu relevanteren Suchergebnissen mit höheren Konversionsraten, indem Rechtschreibfehler, Synonyme, Phrasen und Kopf-Schwanz-Anfragen behandelt werden. Domain-Overrides werden über ein robustes Regelwerk bereitgestellt, um die Konversionsraten insgesamt zu verbessern.
Klassifizierung von Abfragen
Diese Technik des maschinellen Lernens analysiert, wie die eingehenden Anfragen kategorisiert sind, und erstellt ein Klassifizierungsmodell, das zur Vorhersage der Kategorien der neu eingehenden Anfragen verwendet werden kann.
Ähnlichkeit der Abfrage
Dies ist ein Empfehlungsmodell, das auf dem gemeinsamen Auftreten von Suchanfragen im Kontext von angeklickten Dokumenten und Sitzungen basiert. Es ist nützlich, wenn Ihre Signaldaten zeigen, dass Benutzer dazu neigen, in einer einzigen Suchanfrage nach ähnlichen Artikeln zu suchen.
Klassifizierung von Suchbegriffen
Im Rahmen des Abfrageverständnisses können wir Entitäten aus den Abfragen extrahieren, die auf einem vorgefertigten Vokabular von Begriffen basieren (z.B. ein Produktkatalog im E-Commerce). Auf diese Weise können wir die In-Session-Filter auf der Grundlage der bei der Abfrage extrahierten Entitäten weiter personalisieren.
Verwandte/Trends/Beliebte Suchanfragen
Dies sind sehr nützliche Analyse-Aggregate, die den Suchenden Optionen und Alternativen bieten, um weiter nach Themen und Bereichen zu suchen, die sie interessieren könnten oder die in ihren Communities von Interesse sind.
4. Relevanz-Tuning
Bei der Relevanzabstimmung kommt alles zusammen, um die wirkungsvollsten Suchergebnisse zu erzielen und das Erlebnis mit Empfehlungen zu verbessern. Die Intelligenz, die durch die Anreicherung von Daten und das Verständnis von Suchanfragen hinzugefügt wird, ermöglicht es uns, die Ergebnisse von Suchanfragen zu verfeinern. Die lexikalische Suche (auf der Basis von Schlüsselwörtern), ergänzt durch die Anreicherung von Signalen, entwickelt sich weiter. Wir haben jetzt fortschrittliche Methoden auf der Grundlage von Deep Learning eingeführt, um eine Vektorsuche zu ermöglichen, die uns Ergebnisse auf der Grundlage semantischer Ähnlichkeit (nicht nur Wortübereinstimmungen) liefert.
Dieser Raum hat Möglichkeiten eröffnet, das Problem des Kaltstarts auf mehreren Ebenen besser anzugehen. Wir können den Mangel an Signalen und sogar den Mangel an Trainingsdaten mit vorgefertigten Branchenmodellen beheben. Wir entwickeln jetzt skalierbare Backends für Konversationen sowie leistungsfähigere Empfehlungen, die semantische Ähnlichkeit nutzen und iterativ mit Signalen verbessert werden können.
Signale verstärken
Verhaltensdaten wie Klicks und Aktionen (in den Warenkorb legen, kaufen usw.) können verwendet werden, um die Ergebnisse auf der Grundlage der Popularität der Anfrage zu verbessern. Dies erhöht die Relevanz, wenn sie über die regulären Ergebnisse der lexikalischen Suche (Stichwort) gelegt werden.
Verwandte/Trendende/beliebte Produkte oder Dokumente
Anhand von historischen Signaldaten können wir grundlegende Aggregationsanalysen durchführen und den Nutzern Empfehlungen präsentieren, die ihr Navigationserlebnis verbessern, und zwar auf der Grundlage der ursprünglichen Suchergebnisse.
Collaborative Filtering-Empfehlungen
Anhand von Signalen aus der gesamten Nutzerpopulation berechnen wir Nutzer-Element-Empfehlungen oder Element-Element-Empfehlungen. Wir verwenden fortschrittliche kollaborative Filtermethoden wie Alternating Least Squares (ALS) und Bayesian Personalized Ranking (BPR), um Empfehlungen von Artikel zu Artikel oder von Benutzer zu Artikel zu geben. Diese Methoden sind jedoch immer noch von Signalen abhängig, was für Unternehmen ein Problem beim Kaltstart darstellen kann.
Inhaltsbasierte Empfehlungssysteme
Um das Problem des Kaltstarts (Mangel an Signalen) zu bekämpfen, kommen Deep-Learning-Methoden wie die Vektorsuche ins Spiel. Wir verwenden die Vektorsuche, um Produkte/Dokumente auf der Grundlage der Ähnlichkeit zwischen der Suchanfrage und der Produktbeschreibung oder dem Dokumentinhalt zu empfehlen.
Kluge Antworten:
Konversationelle KI hat zwei Hauptkomponenten. Erstens gibt es die Benutzereingabekomponente, die mit der Anwendung zusammenhängt, in die der Benutzer seine Anfragen eingibt. Diese Anwendung verarbeitet die Anfrage und gibt dann die Ergebnisse zurück – in der Regel in Suchleisten, Chatbots oder virtuellen Assistenten. Zweitens gibt es die Backend-Komponente, die die Eingaben umwandelt und mit den Wissensdatenbanken interagiert, um die beste Antwort abzurufen und diese dann zurückzuschicken. Smart Answers von Lucidworks bietet leistungsstarke konversationelle KI-Backends, die vektorbasierte Deep-Learning-Modelle verwenden, um die Antworten aufzufüllen.
Smart Answers arbeitet in mehreren Modi, um das Problem des Kaltstarts zu lösen. Branchenmodelle werden für Abfragen eingesetzt, wenn das Unternehmen über keine Ausgangswissensbasis (Dokumente oder FAQs) verfügt. Wenn Dokumente vorhanden sind, verwendet Smart Answers Kaltstart-Trainingsmodelle, um die Dokumente zu verstehen und präsentiert dann die richtige Antwort, die extrahiert wurde, um die eingehenden Anfragen präzise zu beantworten. Wenn Unternehmen über kuratierte FAQs für Benutzer verfügen, verfügt Smart Answers über einen Workflow für die Schulung und Bereitstellung von FAQs, um diese Informationen den Benutzern zur Verfügung zu stellen und die Erfahrung von Self-Service und Anrufumleitung zu verbessern.
Begleiten Sie uns auf unserer Reise
Nachdem wir nun einen Überblick über unsere Philosophie und den Schwerpunkt von Lucidworks im Bereich der KI-gestützten Suche gegeben haben, werden wir in einer Reihe von Blogs auf technische Bereiche wie Architektur, tiefe Methodikanwendungen und Geschäftsanwendungen eingehen, in denen wir diese Methodik in realen Kundenszenarien anwenden. In der Zwischenzeit können Sie auf unserer Kundenseite Beispiele aus dem wirklichen Leben sehen, wie wir einige der größten Marken der Welt unterstützen .