Clustering und Klassifizierung im E-Commerce
Im Jahr 2023 ist der Anteil des E-Commerce am Einzelhandelsumsatz laut Mastercard SpendingPulse um 6,3 % gestiegen. Dieses massive Umsatzwachstum geht einher mit einem massiven Anstieg der Daten zum Kundenverhalten. Fortschritte in der generativen KI geben Einzelhändlern noch nie dagewesene, detaillierte Einblicke in das Kundenverhalten und ermöglichen es ihnen so, das Kundenerlebnis auf verschiedene Weise zu verbessern: Produktempfehlungen, personalisierte Suchtechnologie, Kundensupport und dynamische Preisgestaltung.
Angesichts der Fülle an verfügbaren Kundendaten stehen Einzelhändler jedoch vor der Herausforderung, diese Daten effektiv zu organisieren und zu nutzen, um ihre Geschäftsziele zu erreichen. Hier kommen Clustering- und Klassifizierungsalgorithmen ins Spiel. Diese Techniken des maschinellen Lernens können Einzelhändlern helfen, ihre riesigen Mengen an Kundendaten sinnvoll zu nutzen und ihre E-Commerce-Strategien zu verbessern.
Wenn wir von KI sprechen, meinen wir maschinelles Lernen, ein Teilgebiet der KI, das Maschinen das Lernen beibringt und Erkenntnisse aus Eingabedaten ableitet. In diesem Artikel werden zwei bekannte Techniken des maschinellen Lernens – Klassifizierung und Clustering – vorgestellt, die die Suche nach E-Commerce-Websites beeinflusst haben. Außerdem stellen wir Ihnen einige statistische Modelle vor, die Ihre Datenwissenschaftler zum Trainieren der Maschine verwenden können.
Wenn Sie diese verschiedenen Modelle kennen, können Sie besser verstehen, welche Suchtechnologie Sie benötigen, wenn Präzision für die Zufriedenheit Ihrer Kunden entscheidend ist. Es ist weniger wichtig, ein Experte für statistische Modelle zu sein, als eine Suchtechnologie zu haben, die Sie unterstützen kann. Stellen Sie es sich so vor: Wenn Sie eine Bäckerei sind und glutenfreies Brot anbieten möchten, müssen Sie jede Zutat kennen, die in Ihrem Produkt enthalten ist.
Überwachtes vs. Unüberwachtes Lernen
Bevor wir uns mit der statistischen Modellierung befassen, sollten wir ein paar Begriffe klären. Kunden wollen die relevantesten Ergebnisse (Qualität), die Präzision genannt wird. Sie wollen aber auch eine große Auswahl (Quantität), die als Recall bezeichnet wird. Es geht also darum, ihnen viele Optionen zu bieten und sich auf die relevantesten zu beschränken. Als Händler müssen Sie sicherstellen, dass Ihre Datenwissenschaftler die Kontrolle über die Modelle haben, um die größtmögliche Präzision zu erzielen.
Einige dieser Präzisions- und Wiedererkennungswerte können mit einer starken Suchmaschine für E-Commerce-Websites erzielt werden. Darüber hinaus können wir aber auch sehen, was ein einzelner Nutzer – und andere einzelne Nutzer insgesamt – in der Vergangenheit getan haben. So können Sie die Wahrscheinlichkeit einschätzen, dass ein Kunde eher etwas kauft als etwas anderes – und das gibt Ihnen die Möglichkeit, Empfehlungen auszusprechen.
Wir haben zwei Methoden, um der Maschine beizubringen, welche Empfehlungen funktionieren und welche nicht: überwachtes und unüberwachtes Lernen. Beim überwachten Lernen geben wir eine Zielvariable vor und bitten dann die Maschine, aus unseren Daten zu lernen.
Wir haben zum Beispiel viele Fotos oder Produkte mit verschiedenen Modeartikeln wie Schuhen, Hemden, Kleidern, Jeans, Jacken usw. Wir können ein überwachtes Lernmodell auf diesen Fotos trainieren, um die Artikel auf jedem Foto zu lernen und dieses Modell dann verwenden, um die gleichen Artikel auf neuen Fotos zu erkennen. Diese Gegenstände sind die Zielvariablen, die das Modell lernen soll. Für das überwachte Lernen benötigen Sie eindeutig gekennzeichnete Daten.
Aber was, wenn Sie das nicht tun? Oder was ist, wenn nur ein Teil Ihrer Daten eindeutig beschriftet ist? Wir verzichten auf die Idee, eine Zielvariable zu haben und nennen dies unbeaufsichtigtes Lernen. Wir werden den Unterschied zwischen überwachtem und unüberwachtem Lernen weiter unten erklären.
Die Bedeutung der Klassifizierung im E-Commerce
Geldbörse oder Handtasche? Turnschuhe oder Sportschuhe? Oberbekleidung oder Mantel? Menschen bezeichnen Dinge unterschiedlich, und im Einzelhandel ist es das Schlimmste, wenn eine Suchmaschine auf einer E-Commerce-Website dem Kunden nichts liefert, weil er ein anderes Wort oder Synonym eingegeben hat. Diese Ausgaben werden diskrete Ausgabevariablen genannt, und wir verwenden eine Methode namens „Klassifizierung“, um den Computer anhand einer Reihe von Eingaben zu trainieren.
Um der Maschine beizubringen, alle Objekte einer bestimmten Klasse zu finden, müssen Ihre Trainingsdaten eindeutig beschriftet sein. Sobald diese bereinigt sind, können Sie Algorithmen für maschinelles Lernen verwenden, um die Daten zu trainieren. Hier sind ein paar davon:
1 – Der k-Nächste-Nachbarn-Algorithmus (KNN) ist sehr einfach und effektiv. Vorhersagen werden für einen neuen Datenpunkt gemacht, indem der gesamte Trainingssatz nach den ähnlichsten K Instanzen (den Nachbarn) durchsucht und die Ausgangsvariable für diese K Instanzen zusammengefasst wird. Der wichtigste Anwendungsfall für k-Nächste Nachbarn sind Empfehlungssysteme. Wenn wir wissen, dass ein Benutzer einen bestimmten Artikel mag, können wir ihm ähnliche Artikel empfehlen.
Im Einzelhandel verwenden Sie diese Methode, um wichtige Muster im Kaufverhalten der Kunden zu erkennen und anschließend den Umsatz und die Kundenzufriedenheit zu steigern, indem Sie das Kundenverhalten vorhersehen.
2 – Entscheidungsbäume sind eine weitere wichtige Klassifizierungstechnik für das maschinelle Lernen von Vorhersagemodellen. Die Darstellung des Entscheidungsbaummodells ist ein binärer Baum. Jeder Knoten repräsentiert eine einzelne Eingabevariable (x) und einen Teilungspunkt auf dieser Variable (vorausgesetzt, die Variable ist numerisch). Die Blattknoten des Baums enthalten eine Ausgangsvariable (y), die zur Erstellung einer Vorhersage verwendet wird.
Vorhersagen werden gemacht, indem man „die Splits des Baums abläuft“, bis man zu einem Blattknoten gelangt und den Klassenwert an diesem Blattknoten ausgibt. Entscheidungsbäume haben viele reale Anwendungen, von der Auswahl der zu kaufenden Waren bis hin zur Wahl des Outfits für eine Büroparty.
3 – Die logistische Regression ist die Methode der Wahl, wenn unsere Zielvariable kategorisch ist und zwei oder mehr Stufen hat. Einige Beispiele sind das Geschlecht eines Benutzers, das Ergebnis eines Sportspiels oder die politische Zugehörigkeit einer Person.
4 – Das Naive Bayes-Modell umfasst zwei Arten von Wahrscheinlichkeiten, die direkt aus Ihren Trainingsdaten berechnet werden können: 1) die Wahrscheinlichkeit für jede Klasse und 2) die bedingte Wahrscheinlichkeit für jede Klasse bei jedem x-Wert. Sobald das Wahrscheinlichkeitsmodell berechnet ist, kann es zur Vorhersage neuer Daten unter Verwendung des Bayes’schen Theorems verwendet werden.
Naive Bayes kann in verschiedenen Szenarien angewandt werden: Markieren einer E-Mail als Spam oder nicht, Vorhersage des Wetters, ob es sonnig oder regnerisch ist, Überprüfung einer Kundenrezension auf positive oder negative Stimmung, und vieles mehr. Es ist eine einfache, aber effektive Methode für Klassifizierungsaufgaben und wird oft als Basismodell für den Vergleich mit komplexeren Modellen verwendet.

Training eines Datensatzes mit statistischen Modellen
Nehmen wir an, Ihre Datenwissenschaftler haben sich für einen Machine-Learning-Algorithmus zur Klassifizierung entschieden. Als nächstes müssen wir den Algorithmus trainieren oder ihn lernen lassen. Um den Algorithmus zu trainieren, füttern wir ihn mit Qualitätsdaten, dem so genannten Trainingsset, dem Satz von Trainingsbeispielen, mit dem wir unsere Algorithmen trainieren. Wir werden versuchen, die Zielvariable mit unseren Machine-Learning-Algorithmen vorherzusagen.
In einem Trainingssatz ist die Zielvariable bekannt. Die Maschine lernt, indem sie Beziehungen zwischen den Merkmalen und der Zielvariablen findet. Beim Klassifizierungsproblem werden die Zielvariablen auch als Klassen bezeichnet, und es wird angenommen, dass es eine endliche Anzahl von Klassen gibt.
Um Algorithmen für maschinelles Lernen zu testen, benötigen wir einen vom Trainingssatz getrennten Datensatz, den so genannten Testsatz. Zu Beginn wird das Programm mit den Trainingsbeispielen gefüttert; dabei findet das Lernen statt. Als nächstes wird das Programm mit dem Testsatz gefüttert.
Die Klasse für jedes Beispiel aus dem Testsatz wird dem Programm nicht mitgeteilt, und das Programm entscheidet, zu welcher Klassifizierung jedes Beispiel gehören soll. Die Klasse, zu der das Trainingsbeispiel gehört, wird dann mit dem vorhergesagten Wert verglichen und wir bekommen einen Eindruck davon, wie genau der Algorithmus ist.
Die Bedeutung von Clustering im E-Commerce
Die Clustering-Aufgabe ist ein Beispiel für unüberwachtes Lernen, bei dem automatisch Cluster von ähnlichen Dingen gebildet werden. Der entscheidende Unterschied zur Klassifizierung ist, dass wir bei der Klassifizierung wissen, wonach wir suchen. Das ist beim Clustering nicht der Fall. Clustering wird manchmal auch als unbeaufsichtigte Klassifizierung bezeichnet, weil es das gleiche Ergebnis wie die Klassifizierung liefert, ohne dass es vordefinierte Klassen gibt.
Wir können fast alles in Clustern zusammenfassen, und je ähnlicher die Elemente in einem Cluster sind, desto besser sind unsere Cluster. Dieser Begriff der Ähnlichkeit hängt von einer Ähnlichkeitsmessung ab. Wir nennen dies unüberwachtes Lernen, weil wir keine Zielvariable wie bei der Klassifizierung haben. Anstatt der Maschine zu sagen: „Sagen Sie Y für unsere Daten X voraus“, fragen wir: „Was können Sie mir über X sagen?“.
Wir können beispielsweise einen Algorithmus für unüberwachtes Lernen bitten, uns etwas über einen Datensatz von Kundenkäufen zu sagen, z.B.: „Welche 20 geografischen Gruppen können wir auf der Grundlage ihrer Postleitzahl am besten aus dieser Gruppe von Kunden bilden?“ oder „Welche 10 Produktartikel kommen in dieser Gruppe von Kunden am häufigsten zusammen vor?“
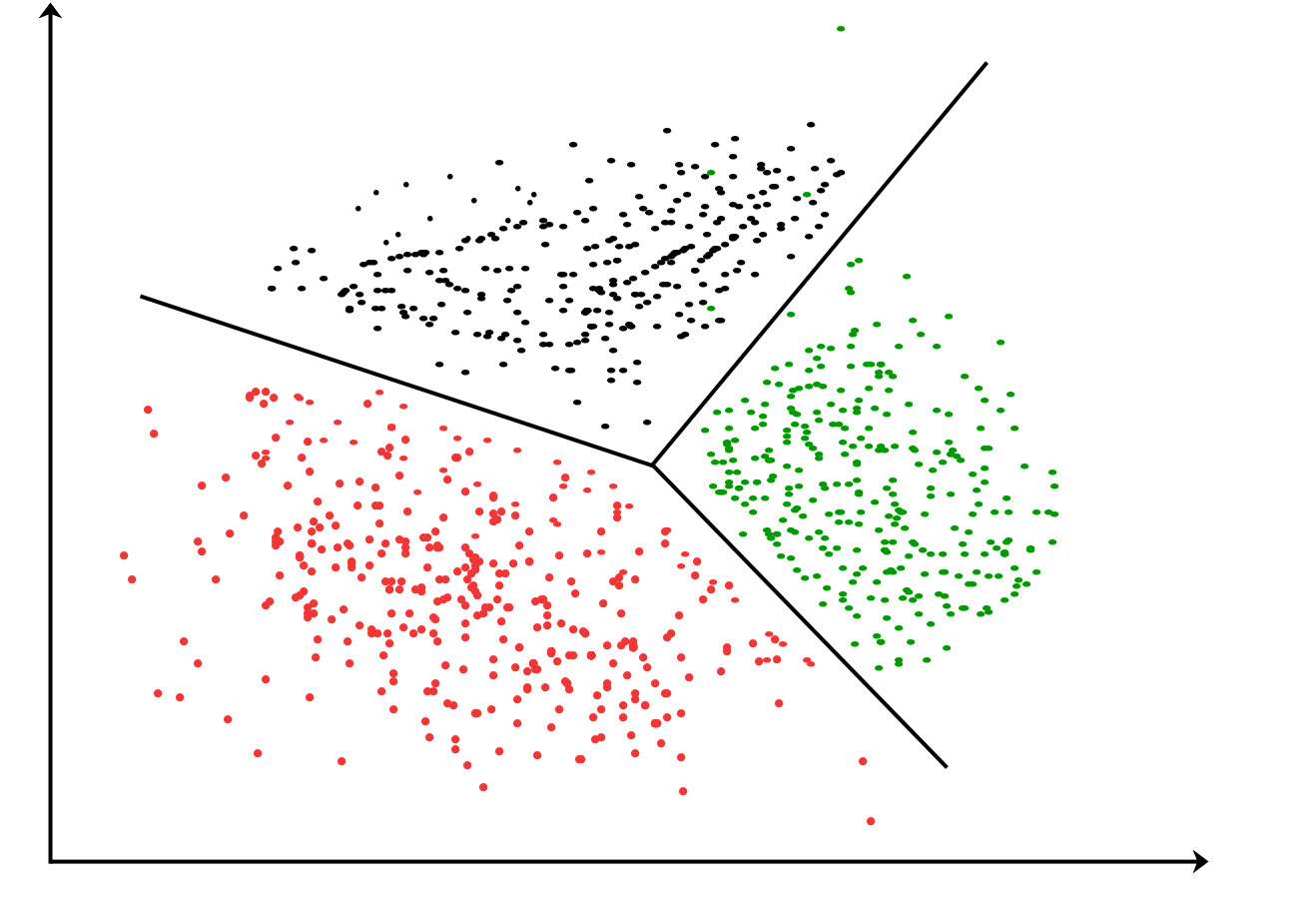
Ein weit verbreiteter Clustering-Algorithmus ist k-means, wobei k eine vom Benutzer festgelegte Anzahl von Clustern ist, die erstellt werden sollen. Der k-means Clustering-Algorithmus beginnt mit k zufälligen Clusterzentren, den so genannten Zentroiden.
Als nächstes berechnet der Algorithmus den Abstand zwischen jedem Punkt und den Clusterzentren. Jeder Punkt wird dem nächstgelegenen Clusterzentrum zugewiesen. Die Clusterzentren werden dann auf der Grundlage der neuen Punkte im Cluster neu berechnet. Dieser Vorgang wird so lange wiederholt, bis sich die Clusterzentren nicht mehr bewegen. Dieser einfache Algorithmus ist recht effektiv, aber er reagiert empfindlich auf die anfängliche Clusterplatzierung.
Ein zweiter Algorithmus namens Bisecting k-means kann für eine bessere Clusterbildung verwendet werden. Bisecting k-means beginnt mit allen Punkten in einem Cluster und teilt dann die Cluster mit k-means mit einem k von 2 auf. Dieser Vorgang wird so lange wiederholt, bis k Cluster erstellt worden sind. Im Allgemeinen werden mit der Halbierung von k-means bessere Cluster erstellt als mit dem ursprünglichen k-means.
Ecommerce Anwendungsfall
In einem unserer früheren Beiträge haben wir vorgeschlagen, wie Amazon seine Empfehlungen verbessern könnte, indem es Clustering einsetzt, um Kunden zu segmentieren und festzustellen, ob sie wahrscheinlich wieder etwas Ähnliches kaufen werden. Lassen Sie uns anhand eines hypothetischen Szenarios sehen, wie das geschehen kann:
- Clustering: Nehmen wir an, Amazon hat einen Datensatz mit allen Bestellungen von 500.000 Kunden in der letzten Woche. Der Datensatz enthält viele Merkmale, die sich grob in Kundenprofile (Geschlecht, Alter, Postleitzahl, Beruf) und Artikelprofile (Typen, Marken, Beschreibung, Farbe) unterteilen lassen. Wenn wir den k-means Clustering-Algorithmus auf diesen Datensatz anwenden, erhalten wir 10 verschiedene Cluster. Da wir nicht wissen, was die einzelnen Cluster repräsentieren, bezeichnen wir sie willkürlich als Cluster 1, 2, 3 und so weiter.
- Klassifizierung: Okay, es ist Zeit für das überwachte Lernen. Wir schauen uns nun Cluster 1 an und verwenden einen Naive Bayes-Algorithmus, um die Wahrscheinlichkeiten der Merkmale Postleitzahl und Artikelart für alle Datenpunkte vorherzusagen. Es stellt sich heraus, dass 95% der Daten in Cluster 1 aus Kunden bestehen, die in New York leben und häufig Schuhe mit hohen Absätzen kaufen. Schauen wir uns nun Cluster 2 an und verwenden Sie die logistische Regression, um eine binäre Klassifizierung für die Merkmale Geschlecht und Farbe für alle Datenpunkte durchzuführen. Das Ergebnis ist, dass die Daten in Cluster 2 aus männlichen Kunden bestehen, die von schwarzen Artikeln besessen sind. Wenn wir dies für alle übrigen Cluster wiederholen, erhalten wir eine detaillierte Beschreibung für jedes Cluster.
- Empfehlung: Schließlich können wir dem Kunden Artikel empfehlen, von denen wir wissen, dass sie gemäß unserer vorherigen Segmentierungsanalyse äußerst relevant sind. Wir können einfach den k-Nächste-Nachbarn-Algorithmus verwenden, um die empfohlenen Artikel zu finden. Zum Beispiel wird den Kunden in Cluster 1 ein Paar Marc New York High Heels empfohlen, den Kunden in Cluster 2 ein schwarzer Rasierer von Dollar Shave Club, und so weiter.
Überwachtes und unüberwachtes Lernen sind zwei der wichtigsten Ansätze für maschinelles Lernen, die den meisten KI-Anwendungen zugrunde liegen, die derzeit in der E-Commerce-Suchtechnologie eingesetzt werden. Die zugrunde liegenden Algorithmen sind die Klassifizierung beim überwachten Lernen und das Clustering beim unüberwachten Lernen.
Sie sehen, dass Sie eine ganze Menge tun können, um ein optimales Gleichgewicht zwischen Erinnerungsvermögen und Präzision zu erreichen. Und trotz all der Mathematik ist die Optimierung eher eine Kunstform. Der Zugang zu den Algorithmen, so dass sie kontinuierlich verfeinert werden können, ist der Schlüssel.
Mein nächster Artikel befasst sich mit dem Learning to Rank, einem wichtigen Werkzeug zur Informationsbeschaffung, das maschinelles Lernen nutzt und für viele Webdienste zur Verbesserung der Suchmaschinenergebnisse von E-Commerce-Websites entscheidend ist.
Mehr erfahren
- Lesen Sie weitere Empfehlungen für den Einzelhandel über den Omnichannel
- Watch Clustering vs. Klassifizierung in der KI – Wie unterscheiden sie sich?
- Kontaktieren Sie uns für Hilfe bei der E-Commerce-Suche