Webinar Recap: Accelerate Data Science with Fusion 5.1
Late in 2019, Fusion 5.0 re-architected Lucidworks Fusion for cloud-native microservices orchestrated by Kubernetes. We released Fusion 5.1 prioritizing features for data scientists who want to build machine learning models to be trained with Fusion usage signals.
Last week, I co-hosted a webinar with one of Lucidworks product managers for artificial intelligence, Sanket Shahane. This brief post is a recap for those of you who weren’t able to join the webinar. Sanket walked through Fusion 5.1’s Data Science Toolkit Integration. He demonstrated Fusion’s integration with Jupyter Notebook and showed how to deploy ML models in Fusion, using Seldon Core.

Here is a link to the recording of the entire webinar, which I’ll summarize in the rest of this post:
Overview of Fusion 5.1
Fusion 5.1 makes the job of a Data Scientist far easier and more productive. Many organizations have centralized data science teams that work apart from the teams who build search applications. This makes it difficult for search teams to leverage custom machine learning models and for data science teams to understand how their models work within Fusion. As a way to bridge that gap, Fusion 5.1 makes custom models more easily consumed by search applications and the developers who create them. It provides a direct feedback loop for data scientists: they deploy models to Fusion, which train on signals data, making Fusion more relevant for users, who then generate more signals.
I spoke about key feature categories in this version: cloud-native architecture; dynamic autoscaling; native support for Python ML models; easy integration with data science tools like TensorFlow, scikit-learn, spaCY, and Jupyter Notebook. And I also covered how these features flow through to Digital Commerce and Digital Workplace solutions.
Jupyter Notebook Integration: Reading Data, Writing Data & SQL Aggregation
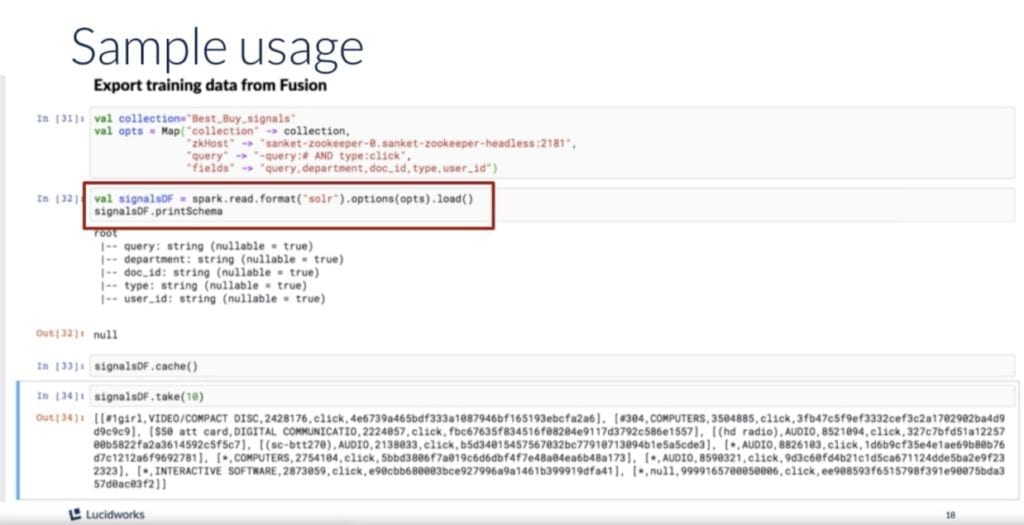
I have a sneaking suspicion that most of the webinar attendees showed up for the main act: Sanket showing, as a data scientist, why Fusion 5.1 is so exciting for data scientists. Sanket walked through an example loading the Best Buy E-Commerce Dataset into a Spark DataFrame in Fusion. Watch the webinar recording for a step-by-step demo of how to import, pre-process and explore ecommerce usage data in Fusion using a Jupyter Notebook.
Deploying ML Models with Seldon Core: Working with Custom Models
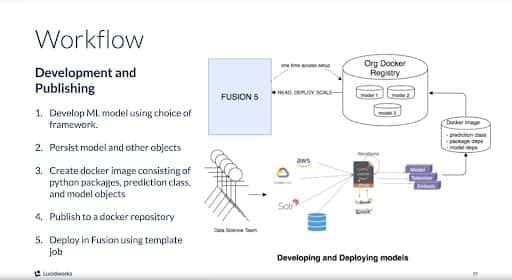
Sanket’s second demonstration was a pre-recorded demonstration of model deployment, in five acts:
- Developing an ML model using a preferred framework,
- Persisting the model,
- Creating a Docker image consisting of Python packages, prediction classes, and model objects,
- Publishing to a Docker repository, and
- Deploying it into Fusion using a template job.
Questions from Webinar Attendees (and Our Answers)
Sanket and I took a lot of great questions from webinar attendees, but time ran out before we could get to all of them. Here are those questions with corresponding answers, including those that went unanswered during the webinar.
Please describe auto-scaling functionality in more detail.
Auto-scaling policies are completely configurable and adaptive to each Fusion customer’s use case. We rely on a variety of criteria – cpu use, memory pressure, the p95 (95th percentile) latency, search rate, or a time-based schedule – to determine scaling. If you anticipate an increased load in a particular time window, your cluster can scale ahead of that event, and in time for the moment.
Please describe Spark Streaming functionality in more detail.
A number of our customers leverage Spark Streaming to index hundreds of millions of documents in just a few hours – even on relatively small clusters (in terms of their Fusion node counts). We often use our Spark operator to stream around 15,000 documents per second to three-node clusters. Obviously, those nodes have quite a bit of RAM. We’ve tuned Spark to work really well for the use cases we focus on.
Does the Lucidworks team use the data science toolkit integration internally?
Yes. Lucidworks heavily uses this integration, and we have various models that are deployed on it. We have deep-learning based sentiment analysis models. Smart Answers (currently incubating) is a question-answering system that uses deep learning, is deployed on this framework. We are also developing a new semantic search solution to reduce zero results for search queries. All Python-based models run on this.
Does Jupyter spin up Spark in Kubernetes?
No. Jupyter does not spin up Spark in Kubernetes. It runs Spark in an embedded local mode. The scope for Jupyter is to be used as a testing, development and exploratory tool. To run Spark jobs in Kubernetes, you should use Fusion’s Jobs framework and not Jupyter. In the demo, we ran Spark in a local mode, for the purposes of exploration.
For the user interaction data, is Fusion GDPR compliant?
Fusion is not yet certified as GDPR compliant, but we provide our customers the ability to run their own hosts. Our customers can isolate data in those hosts and conform to whatever GDPR constraints they may face.
Can I use the Dockerhub repository instead of a private organization repository?
Absolutely. There is no restriction on which Docker repository you can use. As long as Fusion has access to it, you can use it.
Does Fusion manage different versions of the same model?
The Fusion ML Service is a model-deployment framework, not a model creation or model management framework. Fusion can definitely deploy multiple versions of the same model, but it is up to the user to develop these models outside of Fusion and tag them appropriately. For example, a query classifier 1.0 Docker image can be deployed along with query classifier 1.1, and these can be tested in parallel. Maintaining these images is up to the user.
How is TensorFlow used in Fusion? Can you share any example Jupyter code for using TensorFlow to train models in Fusion?
We will be publishing end-to-end how-to’s and do it yourself very soon. In the meantime below is a sample example
Assuming you have a tensorflow-keras model trained and saved to disk, your prediction image directory should look something like the following. With the model weights and the model architecture saved to disk.
ls -l ../prediction-image/
total 32
-rw-rw-r-- 1 sanket_shahane sanket_shahane 1636 Feb 11 22:17 diabetes-model-architecture.json
-rw-rw-r-- 1 sanket_shahane sanket_shahane 15928 Feb 11 22:17 diabetes-model-weights.h5
-rw-rw-r-- 1 sanket_shahane sanket_shahane 706 Feb 11 22:17 DiabetesPrediction.py
-rw-rw-r-- 1 sanket_shahane sanket_shahane 331 Feb 11 22:17 Dockerfile
-rw-rw-r-- 1 sanket_shahane sanket_shahane 35 Feb 11 22:17 requirements.txt
|
The prediction class:
import numpy as np
from keras.models import model_from_json
class diabetesprediction():
#load model
def __init__(self,model_path="./"):
with open(model_path+'diabetes-model-architecture.json') as f:
self.model = model_from_json(f.read())
self.model.load_weights(model_path+'diabetes-model-weights.h5')
self.model._make_predict_function()
#dummy prediction
print('dummy prediction:',self.model.predict(np.array([[6. , 148. , 72. , 35. , 0. , 33.6 , 0.627,
50.]]))[0][0])
#prediction logic
def predict(self,X,feature_names=None):
prediction = self.model.predict(X)
return prediction
|
The requirements.txt file would contain:
seldon-core
numpy
keras
tensorflow
|
Dockerfile:
FROM python:3.7-slim
COPY . /app
WORKDIR /app
RUN pip install -r requirements.txt
EXPOSE 5000
# Define environment variable
ENV MODEL_NAME diabetesprediction
ENV API_TYPE GRPC
ENV SERVICE_TYPE MODEL
ENV PERSISTENCE 0
CMD exec seldon-core-microservice $MODEL_NAME $API_TYPE --service-type $SERVICE_TYPE --persistence $PERSISTENCE
|
Build tag push:
sudo docker build ../prediction-image/ -t {your-repo}/diabetes-model-your-name:1.0
Sudo docker push {your-repo}/diabetes-model-your-name:1.0
|
How fast can a real time classification be done?
Typically you should expect ~15-30 ms of overhead from Fusion’s side, plus the time required by the model for inference. Model inference time is not something the Fusion can control, as this largely depends on the type of the model and its complexity.
Additional Fusion 5.1 Resources
- Read the Fusion 5.1 Launch blog post
- Read the Deploying Custom Data Science Models with Lucidworks Fusion blog post
- Test drive Fusion (in the cloud or in our sandbox)
- Contact us with any questions