Accelerate Time to Value for Information Retrieval with AI
“0 to 60” is one of the buzziest specs in the auto-industry. Tesla coupled this spec with a car that is a great-looking EV and that package has become the apex of value in the car world. Now, let’s think about the search experience and what we think about the apex of value in this particular space. The Google (general search) and Amazon (ecommerce) experiences come to mind right away. They are the early entrants, the incumbents and they’ve stayed ahead of the curve due to the size of data they collect. That data is what leads to the increased sophistication of the intelligence in the experience.
All organizations want to offer that same experience to their search users, however, they all are dealing with a unique, multi-dimensional cold-start problem.
Overcoming the Cold-Start Problem
Cold-start problems represent most of the challenges companies face in achieving the best business outcomes for information retrieval (IR), in an accelerated fashion with least amount of effort. The sources of the cold-start problems can vary by company and can include:
- Lack of – or very little – historical user behavior for search
- Manual processes for domain data enrichment
- Not enough internal data science expertise
- Disjointed handoffs between the personas needed to build powerful search applications (search engineers, data scientists, operations, IT, etc.)
Based on our experience with hundreds of customers, Lucidworks understands that accelerating time-to-value by dealing with the dimensions of the cold-start problem is the key to better business outcomes. Our focus is primarily on the purposeful use of AI to accelerate time-to-value in the following functional areas: Data Curation and Enrichment, Query Understanding and Relevancy Tuning.
Intelligent IR is meant to be an evolving concept. It is a cycle of continuous improvement that can self-learn and adjust, but can be guided by domain experts towards the changing business targets. At Lucidworks we obsess over closing this loop for the personas involved in search curation and helping them accelerate the improvement in relevancy through collaboration and the use of all the resources at their disposal (data, workflows and AI methodologies) – both internally and in the industry.
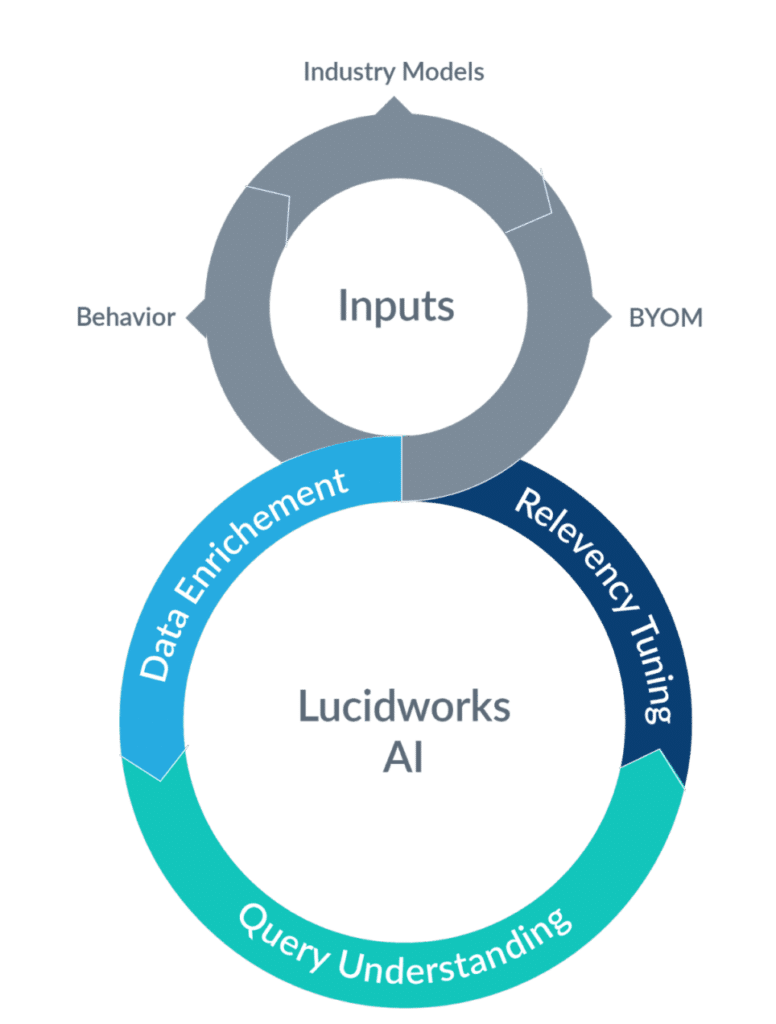
We’re going to be addressing each component, in detail, and talk about how we accelerate our customers when they are faced with the omnipresent cold-start problem.
1. All the Knowledge Available
In order to compete in the personalization space, organizations need to use all the knowledge available to them. This includes population/segment/user behavior, AI methods and models already available in the industry for wide use, and the ability to integrate their own developed models into the search platform. As an IR partner, the Lucidworks platform is designed to facilitate the integration of these resources in the processes needed for data ingestion and querying via powerful workflow-based pipelines.
Signals and Behavior
Signals are composed of all the user behavior that is initiated through a search activity. They can include events like clicks, annotations, requests, responses, actions (like add-to-cart or purchase), sharing, etc. AI uses signals to improve how we process queries and re-interpret them (rewrite them) to the search engine, personalize results based on past activity (boosting results) and help us improve recommendations. Lack of signal data is one of the main sources of cold-start problems in search. Our AI methods are designed to produce immediate value in the absence of signals, and incrementally improve and refine as signals become available.
Industry Models
The one really positive thing about the large data and social platforms (Google, Amazon, Facebook, etc.) is that they are on the bleeding edge of research and they also contribute heavily into the open-source communities. They use their massive amounts of data to produce and publish pre-trained models in the areas of deep learning applied to natural language processing (NLP), understanding (NLU) and generation (NLG). At Lucidworks, we have seen the value of integrating these models directly into the platform and this helps us help our customers address the cold-start problem.
Bring-Your-Own-Models
Lucidworks recognized early on that it is hugely beneficial when companies have very distinct domain data and investment in the data science skills to produce models of their own. We enable these models and encourage pluggability into our data science expertise for increased success. The innovative service-based architecture in Fusion allows data science teams to augment or enhance their capabilities without disruption, dev-ops processes or infrastructure changes. The lack of integration between data science and search operations can be a cold-start issue, which Lucidworks aims to alleviate with this bring-your-own-models capability.
2. Data Enrichment
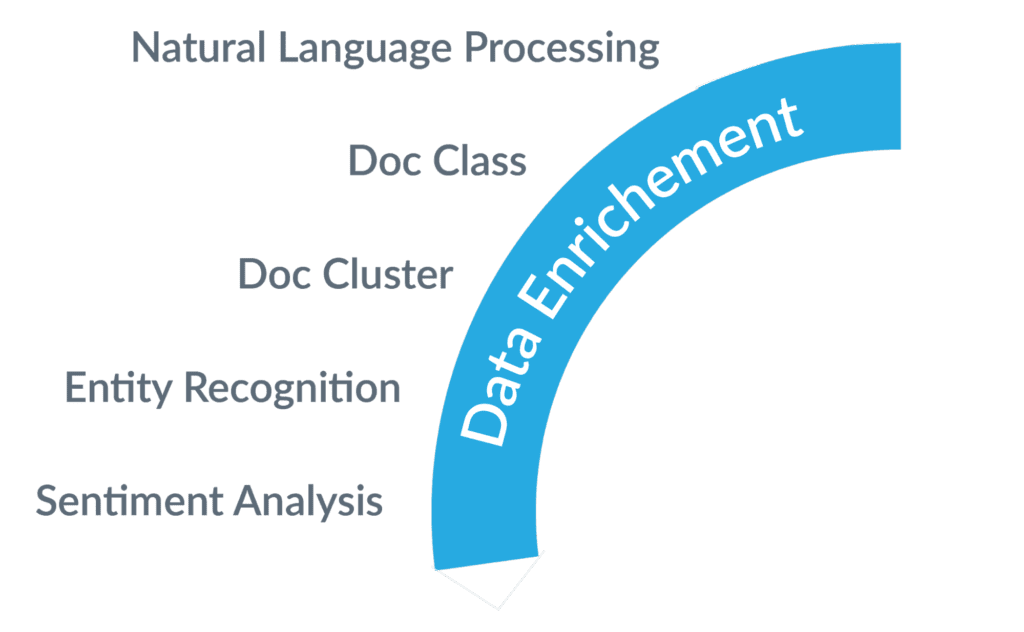
Data curation and enrichment can be a barrier to quick implementation due to the manual nature of the domain-curation of data. We’ve had experiences in the past, especially in the enterprise knowledge management space, where the ownership of data domains did not reside with the search engine operators and the lack of domain enrichment of the data had a negative impact on search relevancy. We believe that automating data enrichment through the use of advanced natural language processing (NLP) and AI accelerates search by addressing the efforts needed for data curation. Without enriched data, the way search engineers address query understanding and relevancy tuning becomes limited.
Natural Language Processing
NLP is the cornerstone of IR. It’s omnipresent in the data workflow and more so in the data ingestion and preprocessing side. Language detection, advanced parsing, tokenization, lemmatization, decompounding and part-of-speech (POS) detection are all addressed using best-in class linguistics methods and workflows (index pipelines). For more information check out our Advanced Linguistic Packages.
Document Classification
Document Classification is machine learning (ML) technique that analyzes how existing documents are categorized and then produces a classification model that can be used to predict the categories of new documents at index time. Integrating this domain expertise in automated classification processes is a way to address the cold-start problem and minimizes the manual process of domain tagging.
Document Clustering
Document clustering is a method that clusters a set of documents and allows for users to understand how documents naturally group together. Clustering in general allows the user a moment of exploration and helps them uncover documents that are outliers in the body of knowledge.
Entity Extraction
Using ML, we automatically extract entities of interest from documents. People, locations, organizations, dates are all examples of some of the important elements that users need when they explore documents. They can downstream with optimizing search results. Our Advanced Language Package supports 21 languages as it extracts 29 entity types and over 450 subtypes, out of the box.
Sentiment Analysis
Sentiment analysis is the interpretation of queries or documents that helps determine if they are positive or negative all by implementing machine learning. Sentiment analysis produces a sentiment model that Fusion can use to perform sentiment prediction at data ingestion time or at query time. Sentiment analysis can be implemented using pre-trained industry models that offer high-quality predictions of sentiment across a variety of domains.
3. Query Understanding
Understanding the intent of the users by intelligently interpreting the query is the key to providing relevant results. The providers of the IR service have “control” over the data indexed (product catalogs, web pages, documents). Those providers can apply treatments of augmentation to the data before the search event is even triggered.
The incoming queries from users, on the other hand, are much less easy to control. We need to use intelligence and automation as much as possible to apply treatments to the incoming query in order to interpret it, understand it, augment it and/or modify it to render the best results. All of this needs to occur in sub-second response times for an optimal search user experience. The models need to be powerful, enhanced by domain rules and overrides, and also designed to render in milliseconds.
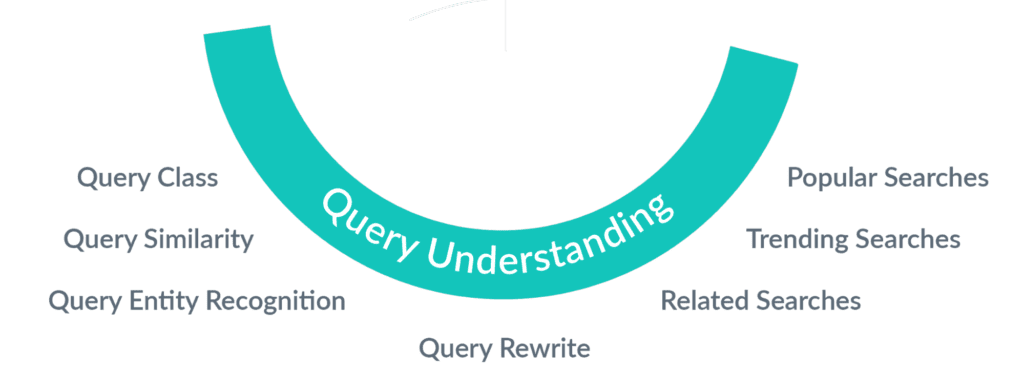
Query Rewrites
Query rewriting is a strategy for improving relevancy by using AI-generated rules for query interpretation based on signals. Fusion AI’s features are used to rewrite incoming queries prior to submitting them to the search engine. These rewrites produce more relevant search results with higher conversion rates by addressing misspelling, synonym detection, phrase detection and head-tail query treatments. Domain overrides are provided through a robust rules framework in order to improve overall conversion rates.
Query Classification
This machine learning technique analyzes how the incoming queries are categorized and produces a classification model that can be used to predict the categories of new incoming queries.
Query Similarity
This is a recommendation model based on co-occurrence of queries in the context of clicked documents and sessions. It is useful when your signal data shows that users have a tendency to search for similar items in a single search session.
Query Term Classification
As part of query understanding, we can extract entities from the queries based on a pre-built vocabulary of terms (for example, a product catalog in ecommerce). Using this, we can further personalize in-session filters based on the entities extracted at query time.
Related/Trending/Popular Searches
These are very useful analytics aggregations that offer search users options and alternatives to further browse on topics and areas that may interest them or are of interest in their communities.
4. Relevancy Tuning
Relevancy tuning is where everything comes together to produce the most impactful search results and enhance the experience with recommendations. The intelligence added in data enrichment and query understanding allows us to refine the results to queries. The use of lexical search (keyword based), augmented with signals boosting is evolving. We have now introduced advanced methods based on deep-learning to enable vector search which allows us to deliver results based on semantic similarity (not just word matches).
This space has opened up opportunities to better tackle the cold-start problem on multiple levels. We can address lack of signals, and even lack of training data with pre-trained industry models. We are now building scalable conversational backends, as well as more powerful recommendations using semantic similarity that can be improved with signals iteratively.
Signals Boosting
Behavior data like clicks and actions (add-to-cart, purchase, etc.) can be used to boost results based on the popularity of the request. This enhances relevance when overlaid on the regular results, resulting from lexical (keyword) search.
Related/Trending/Popular Products or Documents
Using historical signals data, we can run basic aggregation analytics and present recommendations to users that enhance their navigation experience all based on the initial search results.
Collaborative Filtering Recommendations
Using signals from the entire user population we compute user-item recommendations or item-item recommendations. We use advanced collaborative filtering methods like alternating least squares (ALS) and Bayesian Personalized Ranking (BPR) for offering item-to-item or user-to-items recommendations. However, these methodologies are still dependent on signals and with that, it can present a cold-start issue to organizations.
Content Based Recommenders
In order to combat the cold-start problem (lack of signals), the use of deep learning methods like vector search come into play. We use vector search in order to recommend products/documents based on the similarity between the query and the product description or the document content.
Smart Answers:
Conversational AI has two key components. First, there’s the user input component that is related to the application that the user inputs queries into. That application consumes the query and then pushes results back – usually into search bars, chatbots or virtual assistants. Second, there’s the back-end component which converts the inputs and interacts with the knowledge bases to retrieve the best answer and then push it back. Smart Answers from Lucidworks provides powerful conversational AI back-ends that use vector-based deep learning models to populate the answers.
Smart Answers operates in multiple modes to address the cold-start problem. Industry models are deployed for queries if the organization has no starting knowledge base (documents or FAQs). If documents are available, Smart Answers uses cold-start training models to understand the documents and then presents the correct answer extracted to precisely address the incoming queries. If organizations have curated FAQs for users, Smart Answers has an FAQ training and deployment workflow to make that intelligence available to users and improve the experience of self-service and call deflection.
Join Us on the Journey
Now that we have a baseline of our philosophy and focus for Lucidworks in the AI-powered search space, we will follow-up with a series of blogs that will touch on technical areas like architecture, deep methodology applications and business applications where we are applying these methodologies against real customer scenarios. In the meantime, you can see real-life examples of how we’re supporting some of the world’s largest brands over on our customer page.