
Solr on YARN
One of the most important evolutions in the big data landscape is the emergence of best-of-breed distributed computing frameworks. Gone are the days where every big data problem looks like a nail for the MapReduce hammer. Have an iterative machine learning job? Use Spark. Need to perform deep analytics on billions of rows? MapReduce. Need ad-hoc query capabilities? Solr is best. Need to process a stream of tweets in real-time? Spark streaming or Storm. To support this multi-purpose data processing platform, Hadoop 2 introduced YARN (Yet Another Resource Negotiator), which separates resource management and job scheduling from data processing in a Hadoop cluster. In contrast, in Hadoop v1, MapReduce computation was tightly coupled with the cluster resource manager. Put simply, YARN allows different jobs to run in a Hadoop cluster, including MapReduce, Spark, and Storm.
In this post, I introduce an open source project developed at Lucidworks for running SolrCloud clusters on YARN (https://github.com/Lucidworks/yarn-proto).
Economies of Scale
Before we get into the details of how it works, let’s understand why you might want to run SolrCloud on YARN. The main benefit to running distributed applications like Solr on YARN is improved operational efficiency. Designing, deploying, and managing a large-scale Hadoop cluster is no small feat. Deploying a new cluster requires investing in dedicated hardware, specialists to install and configure it, and performance / stability testing. In addition, you need to secure the cluster and actively monitor its health. There’s also training employees on how to use and develop solutions for Hadoop. In a nutshell, deploying a Hadoop cluster is a major investment that can take months or even years.
The good news is adding additional computing capacity to an existing cluster is much easier than deploying a new cluster. Consequently, it makes good business sense to leverage economies of scale by running as many distributed applications on YARN as possible. If a new application requires more resources, it’s easy to add more HDFS and data nodes. Once a new application is deployed on YARN, administrators can monitor it from one centralized tool.
As we’ll see below, running Solr on YARN is very simple in that a system administrator can deploy a SolrCloud cluster of any size using a few simple commands. Another benefit of running Solr on YARN is that businesses can deploy temporary SolrCloud clusters to perform background tasks like re-indexing a large collection. Once the re-index job is completed and index files are safely stored in HDFS, YARN administrators can shutdown the temporary SolrCloud cluster.
Nuts and Bolts
The following diagram illustrates how Solr on YARN works.
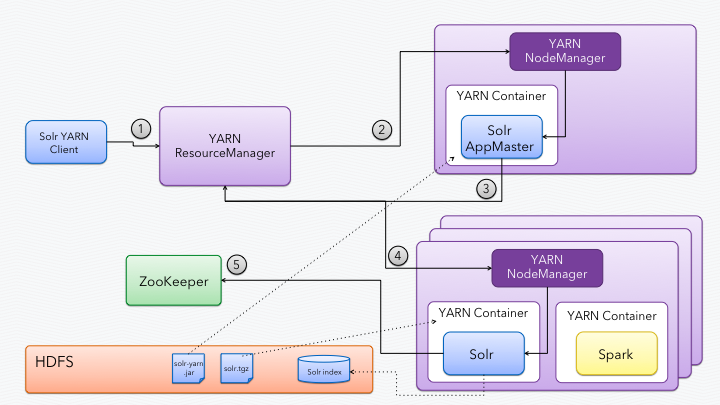
Step 1: Run the SolrClient application
Prior to running the SolrClient application, you need to upload the Solr distribution bundle (solr.tgz) to HDFS. In addition, the Solr YARN client JAR (solr-yarn.jar) also needs to be uploaded to HDFS, as this is needed to launch the SolrMaster application on one of the nodes in the cluster (step 2 below).
hdfs dfs -put solr-yarn/jar solr/
hdfs dfs -put solr.tgz solr/
SolrClient is a Java application that uses the YARN Java API to launch the SolrMaster application in the cluster. Here is an example of how to run the SolrClient:
hadoop jar solr-yarn.jar org.apache.solr.cloud.yarn.SolrClient
-nodes=2
-zkHost=localhost:2181
-solr=hdfs://localhost:9000/solr/solr.tgz
-jar=hdfs://localhost:9000/solr/solr-yarn.jar
-memory 512
-hdfs_home=hdfs://localhost:9000/solr/index_data
This example requests Solr to be deployed into two YARN containers in the cluster, each having 512M of memory allocated to the container. Notice that you also need to give the ZooKeeper connection string (-zkHost) and location where Solr should create indexes in HDFS (-hdfs_home). Consequently, you need to setup a ZooKeeper ensemble before deploying Solr on YARN; running Solr with the embedded ZooKeeper is not supported for YARN clusters.
The SolrClient application blocks until it sees SolrCloud running in the YARN cluster.
Step 2: Allocate container to run SolrMaster
The SolrClient application tells the ResourceManager it needs to launch the SolrMaster application in a container in the cluster. In turn, the ResourceManager selects a node and directs the NodeManager on the selected node to launch the SolrMaster application. A NodeManager runs on each node in the cluster.
Step 3: SolrMaster requests containers to run SolrCloud nodes
The SolrMaster performs three fundamental tasks: 1) requests N containers (-nodes) for running SolrCloud nodes from the ResourceManager, 2) configures each container to run the start Solr command, and 3) waits for a shutdown callback to gracefully shutdown each SolrCloud node.
Step 4: Solr containers allocated across cluster
When setting up container requests, the SolrMaster adds the path to the Solr distribution bundle (solr.tgz) as a local resource to each container. When the container is allocated, the NodeManager extracts the solr.tgz on the local filesystem and makes it available as ./solr. This allows us to simply execute the Solr start script using ./solr/bin/solr.
Notice that other applications, such as Spark, may live alongside Solr in a different container on the same node.
Step 5: SolrCloud node connects to ZooKeeper
Finally, as each Solr starts up, it connects to ZooKeeper to join the SolrCloud cluster. In most cases, it makes sense to configure Solr to use the HdfsDirectoryFactory using the -hdfs_home parameter on the SolrClient (see step 1) as any files created locally in the container will be lost when the container is shutdown.
Once the SolrCloud cluster is running, you interact with it using the Solr APIs.
Shutting down a SolrCloud cluster
One subtle aspect of running SolrCloud in YARN is that the application master (SolrMaster) needs a way to tell each node in the cluster to shutdown gracefully. This is accomplished using a custom Jetty shutdown hook. When each Solr node is launched, the IP address of the SolrMaster is stored in a Java system property: yarn.acceptShutdownFrom. The custom shutdown handler will accept a Jetty stop request from this remote address only. In addition, the SolrMaster computes a secret Jetty stop key that only it knows to ensure it is the only application that can trigger a shutdown request.
What’s Next?
Lucidworks is working to get the project migrated over to the Apache Solr project, see: https://issues.apache.org/jira/browse/SOLR-6743. In addition, we’re adding YARN awareness to the Solr Scale Toolkit (https://github.com/Lucidworks/solr-scale-tk) and plan to add YARN support for Lucidworks Fusion (https://lucidworks.com/product/fusion/) in the near future.