Solr Streaming Expressions ermöglicht erweiterte Suche und Filterung in Fitch Connect
Fitch Solutions unterstützt seine Kunden beim Management von Kreditrisiken, indem es Informationen über das makroökonomische Umfeld und den Markt für Anleiheninvestitionen bereitstellt. Fitch Connect, das Flaggschiffprodukt des Unternehmens, stellt Informationen wie Kreditratings, makroökonomische Daten, Bankenratings und Branchenforschung auf einer Plattform zur Verfügung. Mit Fitch Connect haben Kunden Zugang zu Daten, die eine fundierte Entscheidungsfindung unterstützen.

Prem Prakash, technischer Leiter bei Fitch Solutions, und Weiling Su, Senior-Entwickler und interner Solr- und Fusion-Experte, berichteten auf der Virtual Activate über den Weg, den sie eingeschlagen haben, um eine Textsuche, numerische Bereichsfilter und alphanumerische Bereichsfilter für Daten zu ermöglichen, die in verschiedenen Sammlungen gespeichert sind. Sie beschrieben, wie sie mit Hilfe von Solr-Streaming-Ausdrücken und Fusion-Abfragepipelines in der Lage waren, Daten, die in drei verschiedenen Solr-Sammlungen gespeichert sind, mit einer einzigen Abfrage abzurufen.

Fitch Connect durchsuchen
Die Suchseite von Fitch Connect sieht wie folgt aus:
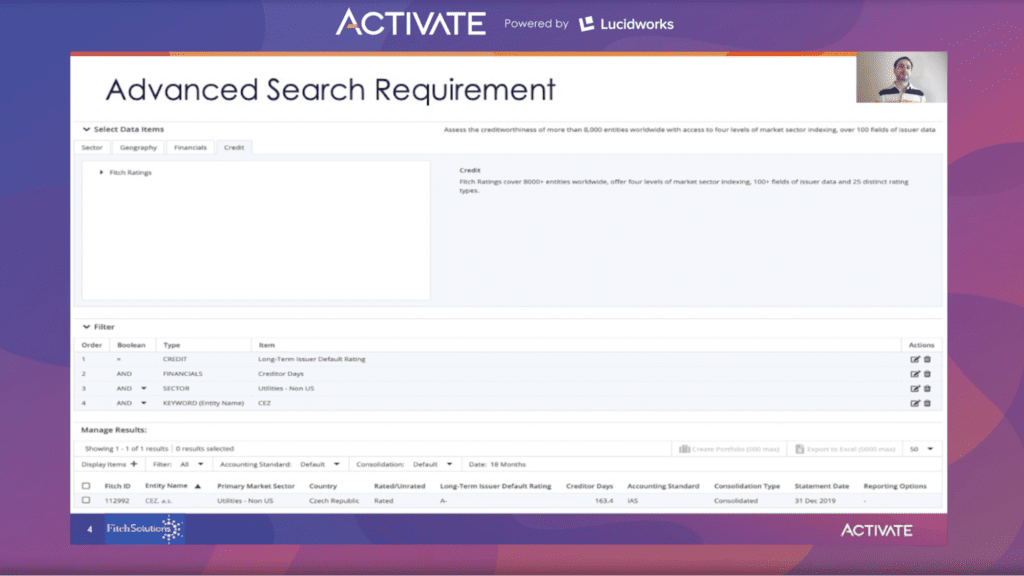
Oben auf der Seite finden Sie die Option „Datenelemente auswählen“. Darunter befinden sich die Kategorien für die Datenfilterung: Sektor, Geografie, Finanzen und Kredit, wobei Geografie und Kredit auswählbare Filter bieten und Finanzen zusätzlich zu auswählbaren Filtern auch numerische Bereichsfilter. Sobald die Filter angewendet wurden, werden die Ergebnisse im Bereich „Ergebnisse verwalten“ unten auf der Seite angezeigt.
Wenn Sie die verfügbaren Filter aufschlüsseln, können Sie nach bestimmten Unternehmen suchen, indem Sie ein Schlüsselwort eingeben. Filter sind für Region, Marktsektor und Rating verfügbar. Zusätzlich zu den Rating-Filtern können auch Rating-Aktionen, Rating-Beobachter und Rating-Ausblicke angewendet werden.
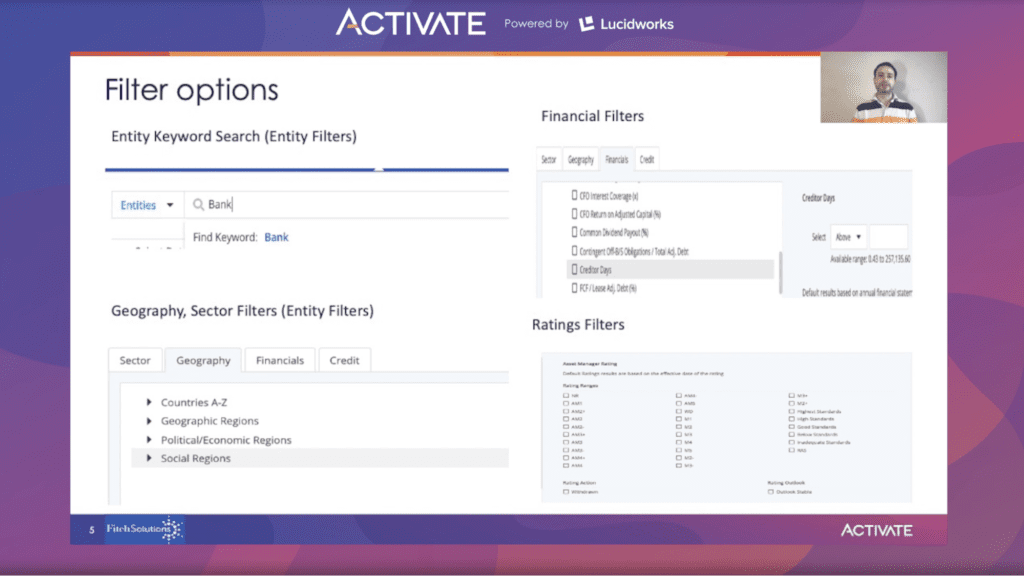
In den Finanzfiltern können Sie, sobald Sie das Finanzfeld ausgewählt haben, einen Bereich über, unter oder zwischen den in das Textfeld eingegebenen Werten auswählen.
Datenstruktur
Aufgrund der unterschiedlichen Art und Komplexität der Daten, auf die Fitch Connect zugreift, werden diese in drei separaten Solr-Sammlungen gespeichert: Entity, Ratings und Financials. Entitäts- und Ratingdaten werden durch die Entitäts-ID verbunden und alle drei Sammlungen werden durch die Agent-ID verbunden.

Zusätzlich zu diesen verbundenen Daten müssen Sie eine Stichwortsuche durchführen und Textfilter anwenden. Für die Finanzdaten sind auch numerische Bereichsfilter verfügbar. Schließlich müssen auch historische Daten abgerufen werden. Auf all dies muss mit einer einzigen Abfrage zugegriffen werden können.
Fitch erwog, alle Daten in einer Sammlung zu speichern, um dies zu ermöglichen, aber angesichts der Komplexität der Datenstruktur und der Art der historischen Daten war dies einfach nicht möglich. Durch die Speicherung der Daten in drei separaten Sammlungen ist die Datenstruktur einfach und leicht zu handhaben. Viele Anforderungen erfordern nur einen bestimmten Datensatz, der auf verschiedenen Bildschirmen angezeigt wird, was mit dieser isolierten Datenstruktur einfacher wird. Auch die Aktualisierung der Daten ist einfacher zu handhaben.
Wege zur Lösung
Solr Join Query und Sub Query, Solr Parallel SQL, Fusion SQL und Streaming Expressions wurden untersucht, um eine Solr-Datenverbindung zu unterstützen:

Die wichtigsten Merkmale des Verbindungsmechanismus wurden wie folgt identifiziert:
- Begrenzung der Anzahl der Sammlungen, die verbunden werden können
- Filter, die auf beiden Seiten der Verbindung ausgeführt werden können
- Stichwortsuche
- Sortieren
- Gruppierung
- Paginierung
- Personalisierung
Die von Fitch Solutions durchgeführte Analyse ergab, dass die Streaming-Ausdrücke die beste Lösung sind.
Vorteile von Streaming Expressions
Streaming Expressions ist eine leistungsstarke Sprache für die Verarbeitung von Datenströmen mit einer Reihe von Funktionen, die in Kombination die Ausführung vieler paralleler Rechenaufgaben ermöglichen. Die umfangreiche Open-Source-Gemeinschaft bietet außerdem eine wachsende Bibliothek und Unterstützung.
Streaming-Ausdrücke ermöglichen drei verschiedene Funktionen:
- Stromquellen, die die Ströme erzeugen.
- Stream-Dekoratoren, wickeln andere Stream-Funktionen ein oder führen Operationen mit den Streams durch.
- Stream-Auswerter, werten Experimente aus und liefern Ergebnisse.

Stream-Quellen und Stream-Dekoratoren geben Ströme von Tupeln (eine Reihe von Daten, die von Solr abgerufen werden) zurück. Stream-Auswerter verhalten sich eher wie eine herkömmliche Funktion, die Experimente auswertet und Ergebnisse zurückgibt.
Fitch Connect verwenden
Ein Kunde von Fitch Connect könnte nach einer Bank mit einer Bilanzsumme von mindestens 2 Millionen und einem langfristigen Emittentenausfallrating von A-, A, A+, AA, AA+ oder AAA suchen. Er möchte die Ergebnisse nach dem Namen der Bank in alphabetischer Reihenfolge sortiert haben und 25 Ergebnisse pro Seite angezeigt bekommen.

Die Suchfunktion wird verwendet, um die übereinstimmenden Tupel aus der Solr-Kernsammlung herauszufiltern. Ein Tupel besteht aus den Rohdaten der Datenwerte und dem Zeitstempel.
Wie es gemacht wird
In der Kernsammlung wird Folgendes durchgeführt:

Jede Sortieroption kann auf jedes zurückgegebene Feld angewandt werden, aber da der nächste Schritt die Durchführung von Verknüpfungen ist, müssen die beiden verknüpften Datenströme denselben Sortierfeldtyp und dieselbe Sortierreihenfolge aufweisen. Sie können sich eine Sortierfunktion sparen, indem Sie das gleiche Sortierfeld und die gleiche Sortierreihenfolge angeben, um die Verknüpfung vorzubereiten.
Eine Auswahlfunktion wird verwendet, um die Felder zu projizieren und/oder die Felder umzubenennen. Im obigen Beispiel wird die Entitäts-ID in die ID des Emittenten oder der Transaktion umbenannt und die ID wird nach ID gruppiert. Qt-Parameter werden standardmäßig im Suchhandler verwendet, aber es wird eine paginierte Ausgabe zurückgegeben und nicht der gesamte Datensatz. Wenn Sie die Verknüpfung auf die gesamte Sammlung anwenden möchten, müssen die Qt-Parameter auf „export“ gesetzt werden. Fitch hat einen innerJoin durchgeführt, um alle Übereinstimmungen auf einmal zu finden.
In der zweiten Kollektion werden die Daten aus der Solr-Finanzkollektion mit der Suchfunktion gefiltert, indem der Bereichsfilter auf total_asset_bnk größer oder gleich 2 angewendet wird. Weitere Kriterien sind periodType, latestStatement, stmntDate, accountingStandards und cross consolidationType.
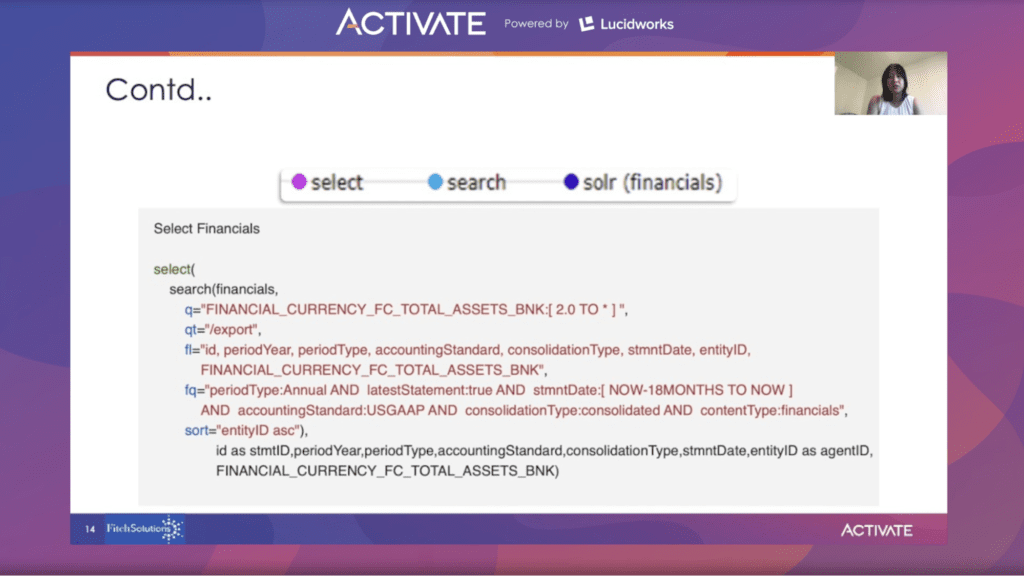
Die Auswahlfunktion benennt das Feld in einen aussagekräftigeren Namen um, dann wird die Sortierfunktion in aufsteigender Reihenfolge auf die Entitäts-ID angewendet.
In den Bewertungssammlungen wird die Suchfunktion zum Filtern von Bewertungswerten verwendet.
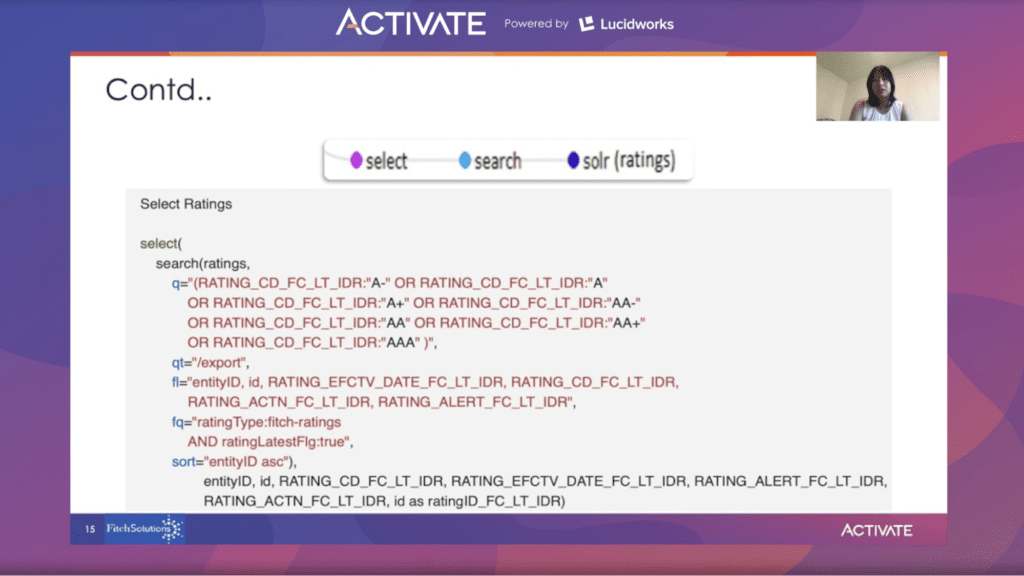
Die Sortierung nach der Entitäts-ID in aufsteigender Reihenfolge, so wie die früheren Sammlungen sortiert waren, ermöglicht eine saubere Verknüpfung.
Sobald die Daten gefiltert wurden, kann die Verknüpfung durchgeführt werden.

Eine Verknüpfung zwischen der Hauptkollektion und der Finanzkollektion wird anhand der Agenten-ID durchgeführt. Es stehen mehrere Verknüpfungstypen zur Verfügung. Eine Hash-Join-Funktion bietet einen Leistungsvorteil gegenüber einem Inner-Join, aber bei den großen Daten, die von Fitch Connect verwendet werden, ist ein Inner-Join die beste Option. Beim Aufruf der inneren Verknüpfungsfunktion wird die Verknüpfungsbedingung mit Parametern angegeben, die einer bestimmten Bedingung entsprechen. Wenn die Join-Felder auf beiden Seiten denselben Namen haben, ist nur ein Feldname erforderlich. Wenn sie sich unterscheiden, muss angegeben werden, dass der linke Feldname dem rechten Feldnamen entspricht. Wenn sich die Verknüpfungsfelder oder die Reihenfolgen unterscheiden, muss vor der nächsten Verknüpfung eine weitere Sortierung durchgeführt werden.
Die aus der vorherigen Verknüpfung von Entität und Finanzen zurückgegebenen Daten werden nun mit den Rating-Daten verknüpft. Auf die innere Verknüpfung zwischen Entität und Finanzen wird eine Sortierfunktion angewendet, damit die Daten korrekt mit den Rating-Daten verknüpft werden können, da die innere Verknüpfung mit den Rating-Daten auf der Entitäts-ID basiert und nicht auf der Agenten-ID, die bei der vorherigen Verknüpfung verwendet wurde.

Hier ist die letzte Abfrage:
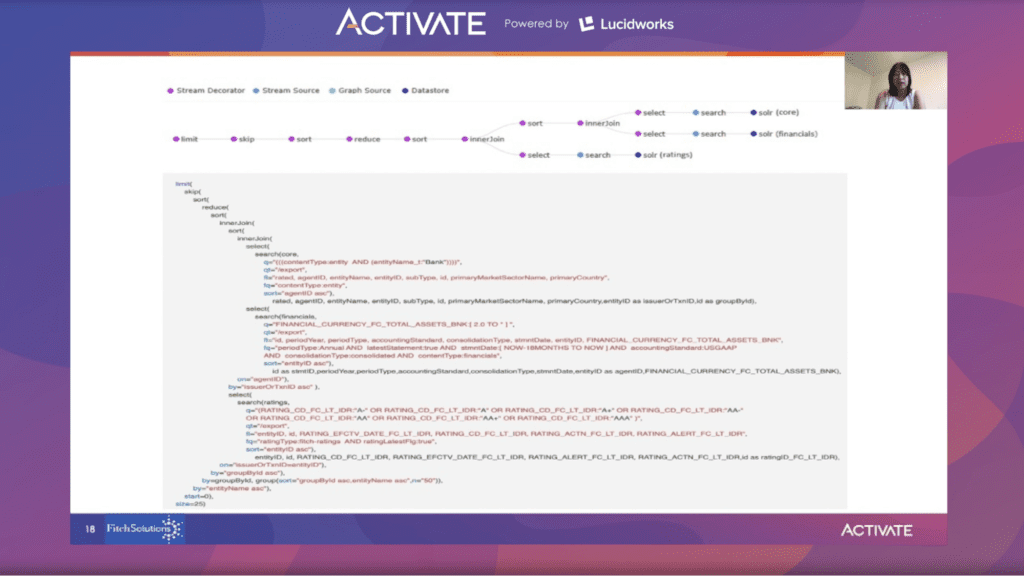
Es wird eine Reduzierungsoperation durchgeführt, um nach dem Feld groupByID zu gruppieren, da die endgültigen Ergebnisse nach groupByID ausgerichtet werden. Ein Unternehmen hat viele übereinstimmende Bewertungen und viele Finanzdaten. Wenn wir groupByID verwenden, wissen wir, wie viele eindeutige Entitäten übereinstimmen. Schließlich ermöglichen die Funktionen limit und skip die Anzeige der Ergebnisse mit Paginierung.
Die von den Streaming Expressions-Funktionen zurückgegebenen JSON-Daten sehen wie folgt aus:

Der linke Bereich enthält eindeutige Unternehmensinformationen und der rechte Bereich zeigt gruppierte Daten in einem Array an. Es werden verschiedene mögliche Verknüpfungen mit dem Rating und den finanziellen Details gefunden, was sich das Fitch-Team erhofft hat.
Paginierte Ergebnisse
Die letzte Anforderung, die erfüllt werden musste, war ein paginiertes Anzeigeformat für die Ergebnisse. Leider war dies in keiner verfügbaren Solr-Bibliothek für die Solr 7-Version, die Fitch verwendete, vorhanden. Unter Ausnutzung des Open-Source-Ethos von Solr implementierte das Fitch-Team einen neuen Solr-Streaming-Ausdruck zur Unterstützung der Paginierung.
Um den neuen Streaming-Ausdruck hinzuzufügen, musste die abstrakte Klasse TupleStream erweitert und eine ausdrucksfähige Schnittstelle implementiert werden. Zwei Stream-Funktionen wurden hinzugefügt.
1. SkipStream wurde verwendet, um die ersten Tupel zu überspringen:

2. LimitStream wurde erstellt, um die Gesamtzahl der zurückgegebenen Datensätze zu begrenzen:

Schließlich musste die Klasse StreamHandler aktualisiert werden, um die neuen Ausdrücke in streamFactory zu laden, so dass das streamFactory-Objekt sie zusammen mit den anderen Funktionen für Streaming-Ausdrücke beim Start laden würde:

Um die Kompatibilität mit der Version von Solr zu testen, die Fitch auf seinem Server verwendet, lud es dieselbe Version herunter, nahm Änderungen und Aktualisierungen daran vor und kompilierte sie neu, um sie auf dem Solr-Server bereitzustellen.

Da Fitch Solr innerhalb der Lucidworks Fusion Software verwendet, mussten die Solr-Bibliotheken von Fusion aktualisiert werden, um die neuen Funktionen für Streaming-Ausdrücke nutzen zu können.

Fusion hat Solr neu gepackt, so dass es an mehreren Stellen zu aktualisieren ist. Nachdem der Test einer Solr-Instanz erfolgreich war, lud das Team bei Fitch die restlichen Solr-Instanzen in seinem Cluster und aktualisierte sie.
Nachdem die Streaming-Ausdrücke erstellt und eingerichtet waren, war die Leistungsoptimierung der nächste Punkt auf der Karte.
Verbesserung der Leistung
Obwohl die Streaming-Ausdrücke alle Anforderungen von Fitch erfüllten, waren Abfragen, die komplexe Verknüpfungen erforderten und mehrere Filter enthielten, sehr träge.
Um dieses Problem zu lösen, wurden die folgenden Änderungen vorgenommen:
- Geeignete Filter wurden angewendet, um die Gesamtmenge der Daten vor der Verknüpfung zu reduzieren.
- Die Auswahl an Feldern in den beiden Join-Sammlungen war begrenzt.
- Die Funktion Parallel wurde verwendet, um parallele Berechnungen durchzuführen, wo immer dies möglich war.
- Bei der Durchführung komplexer Joins wurde eine Hybridlösung zwischen der Standardabfrage von Solr und Streaming-Ausdrücken verwendet.
Die Architektur
Die Sucharchitektur von Fitch sieht folgendermaßen aus:

Die Indexdaten befinden sich in Solr. Fusion Pipelines werden verwendet, um die Daten aus Solr abzurufen. Fusion Query Service, eine Schicht zwischen Fusion und dem Web-Client, hilft bei der Erstellung von Streaming Expressions. Eine vom Client kommende Anfrage wird in der Fusion Query Service-Schicht in eine Streaming Expressions-Abfrage umgewandelt. Die von Solr oder Fusion erhaltene Antwort wird in eine JSON-Ausgabe umgewandelt und an den Client zurückgegeben. Diese Architektur ermöglicht es, alle unnötigen Implementierungsdetails vor dem Client zu verbergen und den Clients eine einfache Abfrage-Nutzlast für die Abfrage der Daten zur Verfügung zu stellen. Der Client muss sich nicht um die darunter liegenden Joins und die verwendete Technologie kümmern.
Um dem Standardverhalten der Benutzer auf der Standardseite besser gerecht zu werden, wird nur die Entität mit den Standardbewertungsinformationen angezeigt. In diesen Standardfällen funktionieren die Abfragen über die Pipeline besser als über die Streaming-Ausdrücke und die Daten werden in der Service-Schicht verarbeitet.

Sobald ein Benutzer erweiterte Filter auf Entitäts-, Rating- und Finanzdaten anwendet, werden die Abfragen durch die Streaming Expressions Pipeline geleitet. Dieser hybride Ansatz sorgt für ein Gleichgewicht zwischen der Abfrage einfacher Daten und der Abfrage erweiterter Daten mithilfe komplexer Joins.
Gelernte Lektionen
Bei der Suche nach einer Textsuche, numerischen Bereichsfiltern und alphanumerischen Bereichsfiltern für komplexe Daten, die in mehreren Sammlungen gespeichert sind, haben wir einige Erkenntnisse gewonnen.
- Wenn Sie eine benutzerdefinierte Implementierung hinzufügen müssen, ist der Ansatz des Streaming Expressions Plugins besser geeignet, um nur interne Funktionen hinzuzufügen. Die Plugin-Architektur von Solr für Streaming Expressions ist eine bessere Option, da sie besser erweiterbar ist.
- Erstellen Sie eine leere Worker-Sammlung, um den Streaming Expressions Handler auszuführen. Auf diese Weise können Sie die Leistung der Streaming-Ausdrücke optimieren, indem Sie mehrere Shards und Replikate erstellen, und es werden mehrere Worker ausgelöst, die die Streaming-Ausdrücke auf einem leeren Datensatz ausführen.
- Verwenden Sie parallel() und parallelList(), um parallele Berechnungen durchzuführen, wann immer dies möglich ist. Bei Abfragen ohne Abhängigkeiten oder Ordnungseinschränkungen maximiert die parallele Streaming-Verarbeitung die Rechenleistung.
- Wenden Sie den Filter an, bevor Sie den Verknüpfungsoperator anwenden. Die von Fitch durchgeführten Leistungstests ergaben, dass die Berechnungszeit für Streaming-Ausdrücke linear mit der Größe der Daten korreliert.
- Schließlich erstellen und validieren Sie die Streaming-Ausdrücke Schritt für Schritt, von innen nach außen. Dies ist der effektivste Weg zur Fehlersuche.
Sehen Sie sich hier die vollständige Präsentation von Fitch Solutions an, um mehr zu erfahren.