LUCIDWORKSJenseits der Suche: KI-gesteuerte Erlebnisse, die Ihre Benutzer verstehen.Verwandeln Sie Berge von Daten in aussagekräftige Erfahrungen in Echtzeit.
Get a DemoMachen Sie es sich einfach, der Beste in Ihrer Branche zu sein.
Wachsen Sie schneller, indem Sie eine KI-gestützte Suche bereitstellen, die die Absichten der Nutzer versteht und digitale Erlebnisse in Echtzeit verbessert. Datengestützte Entscheidungsfindung: der Wettbewerbsvorteil, den Sie verpasst haben.
Schließen Sie sich Hunderten von weltweit führenden Unternehmen an, die ihre Suche und ihre digitalen Erfahrungen mit Lucidworks revolutionieren. Unsere Core Packages erleichtern Ihnen den Einstieg in die KI-gesteuerte Suche, damit Sie sich auf das Wesentliche konzentrieren können: das Vorankommen. Implementieren Sie schnell KI für die Geschäftsumgestaltung, verbessern Sie die Suche, die Einblicke und die digitalen Erlebnisse und sehen Sie vom ersten Tag an den Beweis für den Nutzen. Holen Sie sich bei Bedarf fachkundige Hilfe und setzen Sie die Software ein, wie Sie möchten.

KI-Lösungen für Unternehmen für Such- und Digital Experience-Teams.
Unser Ziel ist es, Ihnen zu helfen, schneller voranzukommen. Mit Schnellstartpaketen, No-Code-Lösungen und brillantem Design hat Lucidworks unsere Technologie so entwickelt, dass sie Risiken reduziert und Erkenntnisse zum Leben erweckt.
Jetzt können Sie Daten in Werte umwandeln.
Lucidworks Pakete
Schneller Start, schneller Nutzen für B2C oder B2B. Vorgefertigte Vorlagen, Zugang zu Studios und Expertenhilfe für Ihren Erfolg.
✔ 25% weniger Entwicklungszeit
✔ 30% weniger Risiko bei der Einführung
✔ 15% höhere Konversionsrate
Lucidworks Studios
Codefreie Kontrolle über Analyse-, Handels-, Wissensmanagement- und KI-Apps durch Geschäftsanwender.
✔ Steigerung des Kundenwerts um 10%
✔ Einsparung von 15 Stunden pro Woche durch Analysten
✔ Steigerung der Konversionen um 13
Lucidworks AI
Orchestrieren Sie Schlüsselbereiche der KI effizient. Verwalten Sie KI-Kosten und Sicherheit, LLM-Optionen und Schulungen und erhalten Sie Hilfe von Experten.
✔ 25% weniger Entwicklungszeit
✔ 20% schneller auf dem Markt
✔ 75% weniger Anfälligkeitsrisiko
Für Unternehmen getestet, für jeden Tag einfach.
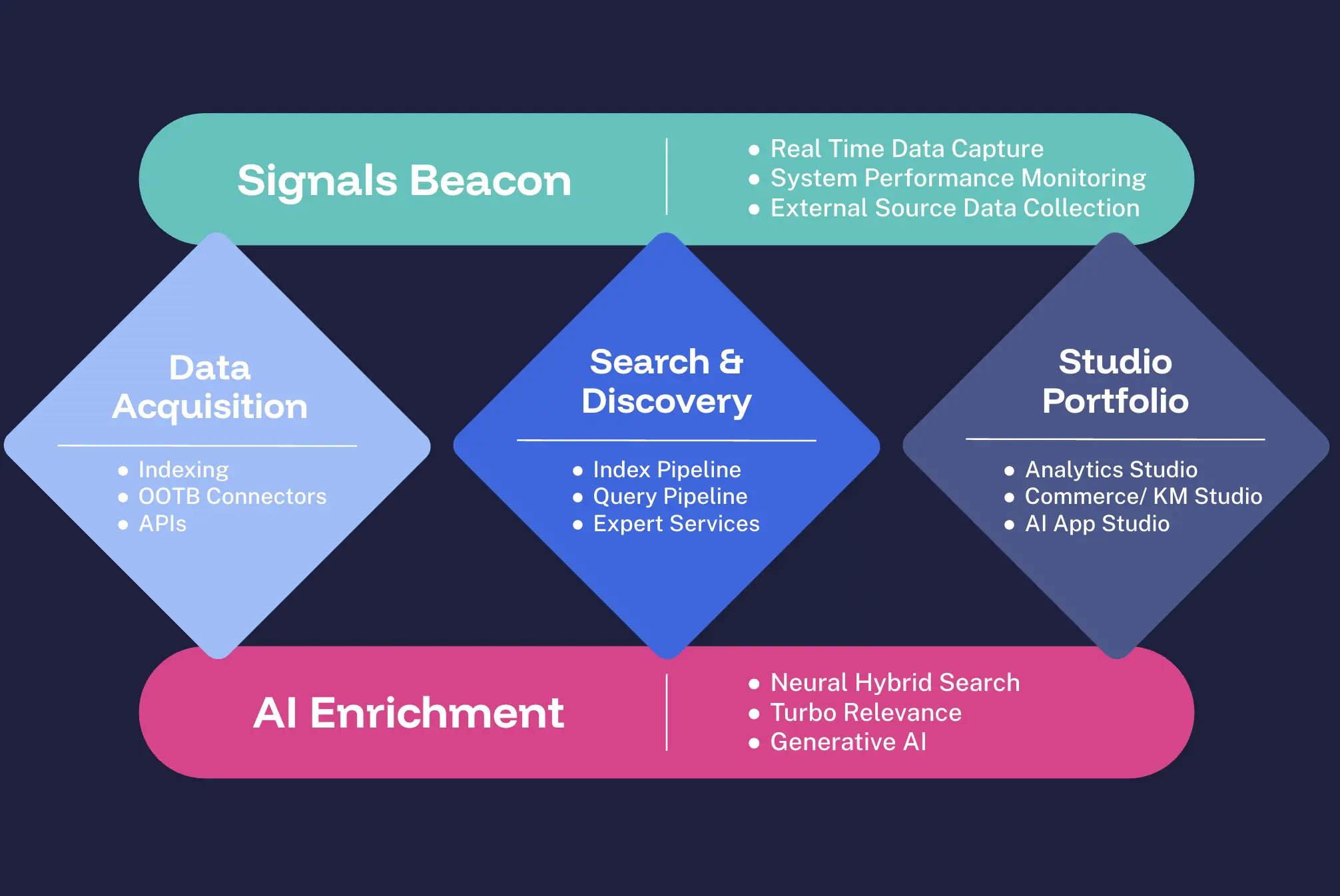
Die Lucidworks-Plattform ist Ihre All-in-One-Lösung für intelligente Unternehmenssuche, Discovery und Personalisierung. Mit Signals, Data Acquisition, Lucidworks Search™, Lucidworks AI und unseren innovativen Lucidworks Studios™ stellen wir Ihnen die Werkzeuge zur Verfügung, die Sie benötigen, um schnell wirkungsvolle Erlebnisse zu schaffen.
Unsere Plattform bietet sofort einsatzbereite Konnektoren für nahtlose Integrationen sowie intuitive visuelle Editoren für einfache Anpassungen. Wir liefern moderne Abfrage- und Index-Pipelines für optimale Leistung, ergänzt durch integrierte A/B-Tests und KPI-Management für kontinuierliche Verbesserungen. Mit der KI-Bereitstellung ohne Code können Sie mühelos das Erlebnis für Ihre digitalen Angebote verbessern.
"Wir haben ein dramatisches Wachstum erlebt. Die Ergebnisse, die wir mit Lucidworks erzielt haben, sind schlichtweg verblüffend."
Marc Desormeau, Leiter der globalen Suche, Lenovo
Die Forrester-Studie "Total Economic Impact" ergab, dass Unternehmen, die Lucidworks einsetzen, innerhalb von drei Jahren einen ROI von 391% erzielen, wobei sich die Investition in weniger als sechs Monaten amortisiert.
ROI-Studie herunterladenREI nutzte Lucidworks, um ein personalisiertes Sucherlebnis zu schaffen, das die Produktentdeckung verbesserte und den Umsatz in der Hochsaison erheblich steigerte.
Entdecken Sie den Erfolg von REILenovo steigerte den jährlichen Umsatzbeitrag um 95 % und verbesserte die Suchrelevanz um 55 % durch den Einsatz der KI-gestützten Suchlösungen von Lucidworks.
Lenovos Geschichte ansehen
Ihr Einsatz, Ihre Art.
Nur Lucidworks bietet Ihnen so viele Möglichkeiten, Ihre Lösung einzurichten. Sie wählen aus, was für Ihr Unternehmen jetzt funktioniert und was in Zukunft mit Ihnen wachsen wird – Sie werden nicht in einen Einheitsansatz gezwungen.
SaaS
Eine moderne No-Code-Plattform mit allem, was Geschäfts-, Such- und Digitalteams benötigen, um die Suche und Produktfindung für Agenturen oder B2B- und B2C-Unternehmen in jeder Branche zu erstellen, zu verwalten und zu optimieren. Schnelle Bereitstellung, kontinuierliche Aktualisierung, Sicherheit und Skalierbarkeit mit automatischen Funktionsupdates.
Selbstgehostet
Eine selbst gehostete Plattform mit allem, was Geschäfts-, Such- und Digitalteams zum Erstellen, Verwalten und Optimieren von Such- und Produktentdeckungen für Agenturen oder B2B- und B2C-Unternehmen in jeder Branche benötigen. Ultimative Kontrolle, sicher, skalierbar und anpassbar an Ihre Umgebung.
Hybrid-SaaS
Eine kombinierte Lösung, die unsere selbst gehostete Plattform mit sicherem Zugang zu zusätzlichen SaaS-Funktionen bietet. Alles, was Teams zum Erstellen, Verwalten und Optimieren der Suche und Produktfindung für Agenturen oder B2B- und B2C-Unternehmen in jeder Branche benötigen. Flexible, sichere und skalierbare Einsatzmöglichkeiten.
Lernen Sie AI App Studio kennen: Erstellen Sie intelligente Suchagenten – ohne eine Zeile Code.
Bringen Sie KI-gestützte Erlebnisse schneller auf den Markt. Mit AI App Studio können Teams maßgeschneiderte Such- und Entdeckungstools wie interaktive Fragen und Antworten und Produktfindungsagenten erstellen, ohne auf Entwicklungsressourcen angewiesen zu sein.
Ganz gleich, ob Sie Käufern bei der Navigation durch einen komplexen Katalog helfen oder den internen Wissenszugang verbessern möchten, alles ist ganz einfach: Klicken, hochladen, veröffentlichen.

Experten-Dienstleistungen
Wir stehen Ihnen bei jedem Schritt zur Seite.
Wir unterstützen Sie in jeder Phase Ihrer Reise – ein entscheidender Vorteil der Zusammenarbeit mit Lucidworks.
Unsere globalen Expertenteams beraten Sie bei der Gestaltung von Such- und Digitalprogrammen, der Verbesserung und Optimierung der Relevanz, dem ROI im B2B- und B2C-Bereich sowie bei der Implementierung und dem Support über den gesamten Lebenszyklus.
Technologie ist wichtig, aber das gilt auch für die Menschen, die mit Ihnen für Ihren Erfolg zusammenarbeiten.
