Using JavaScript to Debug Fusion
Sometimes ready-made isn’t good enough. For those situations, Fusion provides the Javascript stage. This post shows you how to develop and debug them.
Fusion pipelines are composed of stages. Fusion has more than two dozen pipeline stages which provide ready-made components for parsing, transforming, modifying, and otherwise enriching documents and queries, as well as logging stages, and helper stages for composing pipelines. And yet, sometimes ready-made isn’t good enough. Sometimes you need a bespoke processing stage, tailored to your data and your needs. For those situations, Fusion provides the Javascript stage. This post shows you how to develop and debug them.
JavaScript is a lightweight scripting language. The JavaScript in a Javascript stage is standard ECMAScript. What a JavaScript program can do depends on the container in which it runs. In Fusion, that container is a pipeline, thus the JavaScript program has access to the pipeline objects and the methods on those objects. The JavaScript program is compiled by the JDK into Java the first time that a document or query is submitted to the pipeline. In addition to the available pipeline object, core Java classes, including Java collections classes, can be imported and used as needed.
Pipelines come in two flavors: Index and Query. Likewise, Javascript stages come in two flavors: Javascript Index stage and Javascript Query stage. An index pipeline transforms some input data into a document suitable for indexing by Solr. The objects sent from stage to stage in an index pipeline are PipelineDocument objects. A Query Pipeline transforms a set of inputs into a Solr query request and can manipulate the Solr response as well. The objects sent from stage to stage in a query pipeline are Request objects and Response objects.
A Javascript stage can be defined either via the Fusion REST-API or via the Fusion UI. The following screenshot shows side-by-side the initial panel used to define a Javascript index and query stage, respectively.
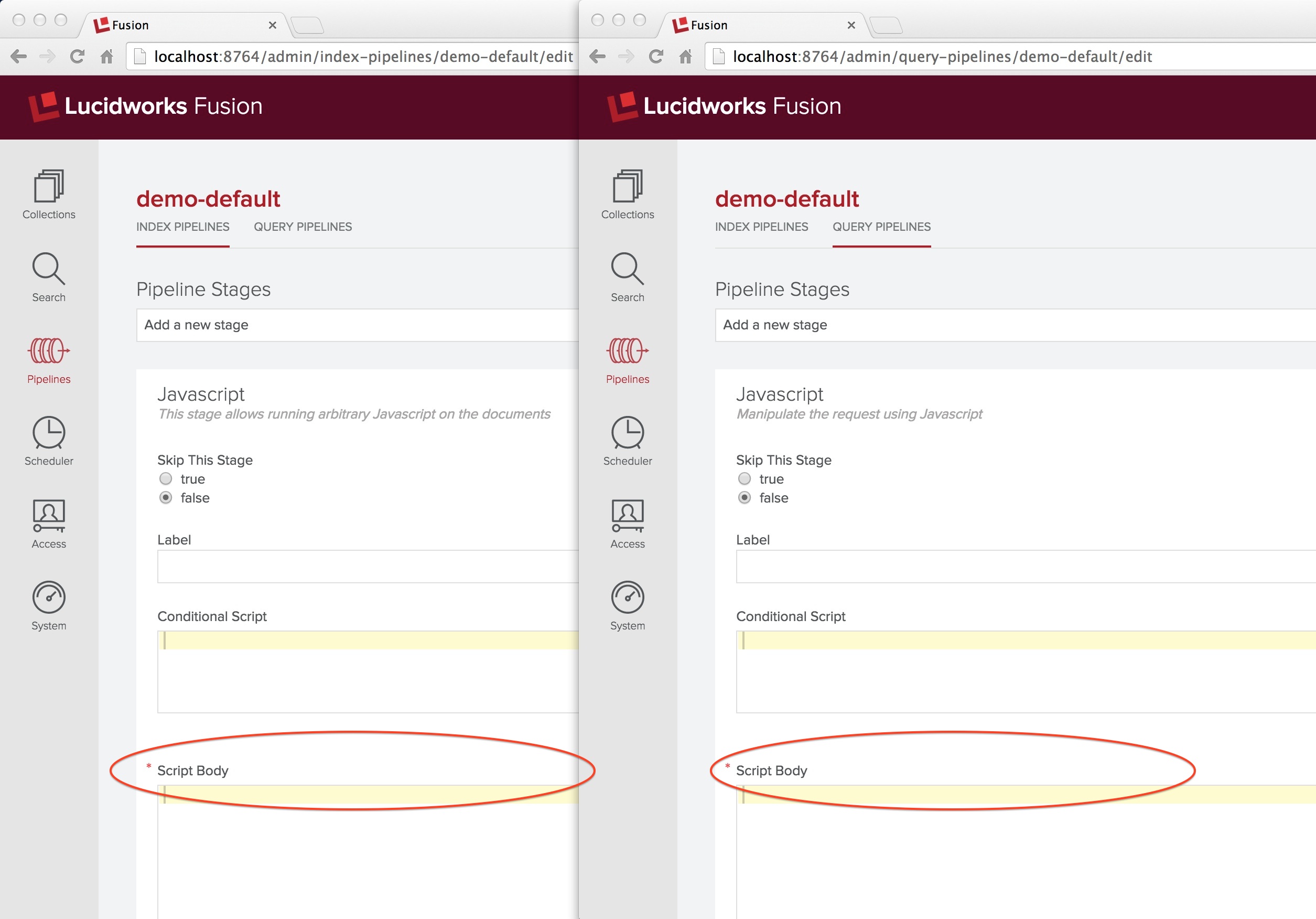
As with all Fusion pipeline stages, a Javascript pipeline stage definition panel has an input box for the stage label, radio buttons for skipping this stage, and a condition box. The condition box takes an optional JavaScript statement which evaluates to true or false. Leaving this box empty means that the condition is always true and all documents will be processed by this stage. I’ve circled the “Script Body” title, which is required (as indicated by the asterisk in red). Both the condition and the script body input text boxes are JavaScript aware and so they provide rudimentary formatting and syntax checking.
Here is an example of a simple JavaScript function for an Javascript Index stage which adds a field to a document:
function (doc) {
doc.addField('some-new-field', 'some-value');
return doc;
}
“What is this doc variable?” you should be asking about now. This is a PipelineDocument object, which is used to hold each data item submitted to a pipeline, along with information about the data submission. A PipelineDocument inherits directly from Object. It is not a SolrDocument object. A PipelineDocument organizes the contents of each document submitted to the pipeline, document-level metadata, and processing commands into a list of fields where each field has a string name, a value, an associated metadata object and a list of annotations. A Javascript index stage operates on the fields of the PipelineDocument. This list of fields depends both on the input and the processing pipeline.
Kudos those who want to know: “What other variables do I have access to?” Javascript stages also have access to a logger object named logger. The logger object is supplied by SLF4J. Log messages are written to the Fusion services log ($FUSION/logs/api/api.log). There are 5 methods available, which each take either a single argument (the string message to log) or two arguments (the string message and an exception to log). The five methods are, “debug”, “info”, “warn”, and “error”. Calls to logger.debug provide feedback during development and calls to logger.error provide feedback once the pipeline is in production.
A Javascript query stage has access to variables request and response, which are query Request and Response objects, respectively. A Request object contains the Solr query information, and the Response object contains the Solr response. While the Javascript index stage expects the script body to be a function which returns a PipelineDocument object, a Javascript query stage expects the script body for be a Javascript code snipped which manipulates query Request and Response objects directly. Here is a (minimal) example of a Javascript Query stage expethat adds a new query parameter “foo” with value “bar” to the request object:
request.addParam("foo", "bar");
You can use any Java class available to the pipeline JDK classloader to manipulate the objects in a Javascript stage. As in Java, to access Java classes by their simple names instead of their fully specified class names, e.g. to be able to write “String” instead of “java.lang.String”, these classes must be imported. The safe and portable way to do this is by using JavaImporter object and the with statement to limit the scope of the imported Java packages and classes. The java.lang package is not imported by default, because its classes would conflict with Object, Boolean, Math, and other built-in JavaScript objects. Furthermore, importing any Java package or class can lead to conflicts with the global variable scope in JavaScript. Therefore, the following example is the recommended way to import Java classes:
var imports = new JavaImporter(java.lang.String);
...
with (imports) {
var name = new String("foo");
...
}
This construct has the advantage of allowing you to write JavaScript that can be compiled both in Java 7 and Java 8. Up through Java 7, most JDKs, including Oracle and OpenJDK used the Mozilla Rhino engine. In Java 8, Oracle introduced their own JavaScript compiler called Nashorn. Running JavaScript written for the Mozilla Rhino engine under Nashorn will require loading a compatibility script if the Rhino functions importClass or ImportPackage are used intead of using a JavaImporter:
// Load compatibility script
load("nashorn:mozilla_compat.js");
// Import the java.lang.String class
importClass(java.lang.String);
var name = new java.lang.String("foo");
...
Fusion doesn’t check the JavaScript syntax when a pipeline stage is defined. Compilation and execution happen the first time a message is sent to the pipeline. If the Javascript stage fails, it will log an error to the server log and otherwise die silently. This makes debugging a Javascript stage problematic.
For Javascript Index stages, the Pipeline Preview tool can be used to validate and test the JavaScript. The preview tool expects to take in a list of PipelineDocument objects in JSON format. The list is pre-populated with two skeleton document objects, each of which contains two key-value pairs. The first key-value pair has key “id” and a string value for the document id. The second key-value pair has key “fields” whose value is the list of fields in the document, coded as pairs of field name, field values, that is, each field is an object consisting of two key-value pairs, key “name”, string value is the field name, key “value”, string value is the value of that field. String values cannot be be broken across lines in the preview tool input box.
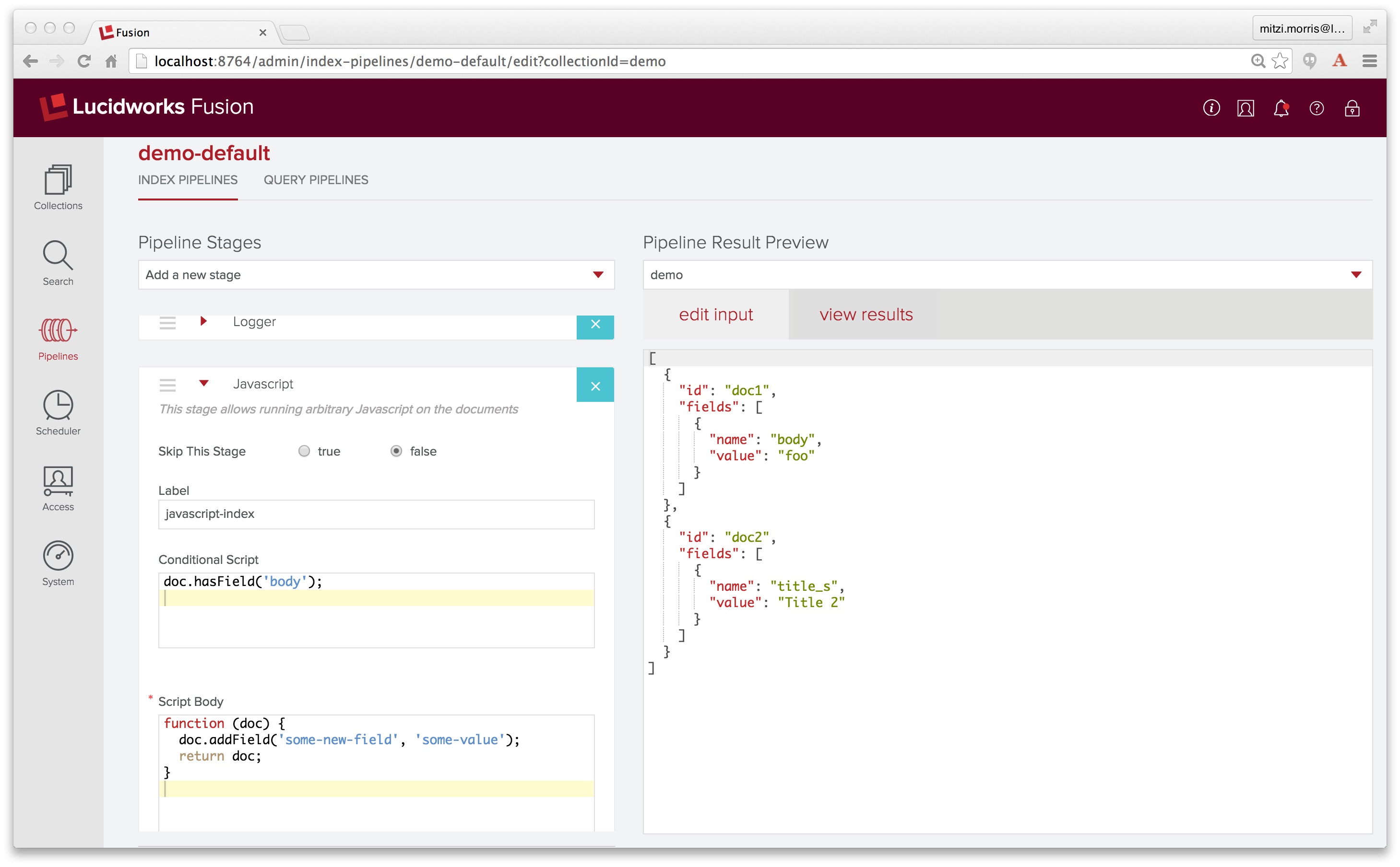
To see how this works, I define a simple pipeline with two stages: an Index Logging stage, followed by a Javascript Index stage. Fusion logging stages provide the pipeline equivalent of debug by printf, one of my favorite debugging techniques. (Stepping back and thinking about the problem is also effective, but hard to demonstrate in a blog post.)
The Javascript index stage specifies a condition as well as a script body. The condition is doc.hasField("body");. The script body is the first example given above. I edit the input documents so that the first document has a field named “body”. Here is a screenshot of the pipeline, showing both the Javascript stage and the Pipeline Preview tool inputs:
Next I click on the “view results” tab to see the result of sending these inputs through the pipeline:
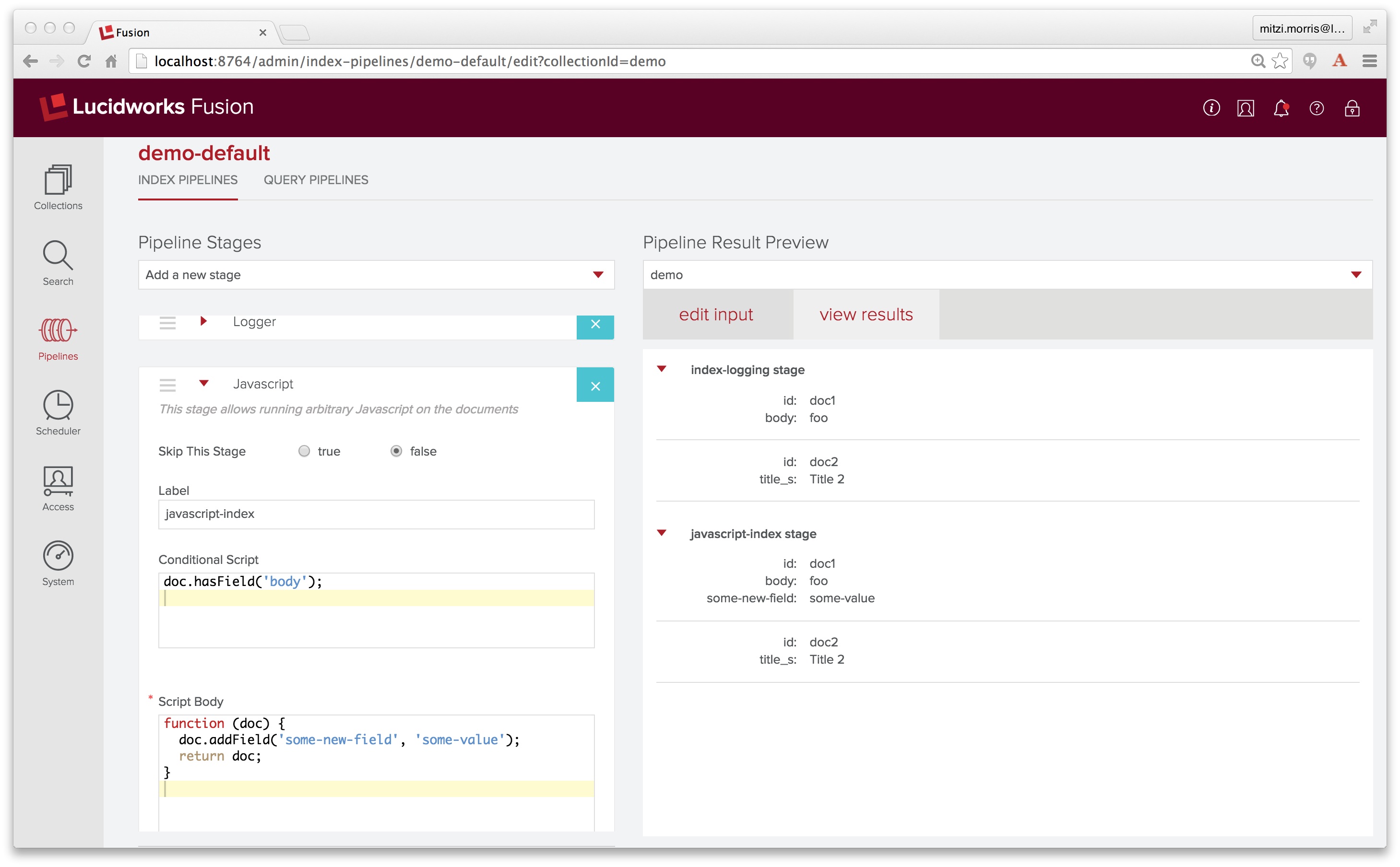
The “view results” tab shows the pipeline documents after going through each stage. By putting a logging stage as the first stage of the pipeline, we see the two input documents. The output of the Javascript stage shows that for the first document, the conditional statement doc.hasField("body") evaluates to true, while the second document fails this test. Therefore only the first document contains an additional field named “some-new-field” with value “some-value”.
If the JavaScript in the Javascript stage doesn’t compile, the Javascript stage will fail silently and the results panel will look something like this:
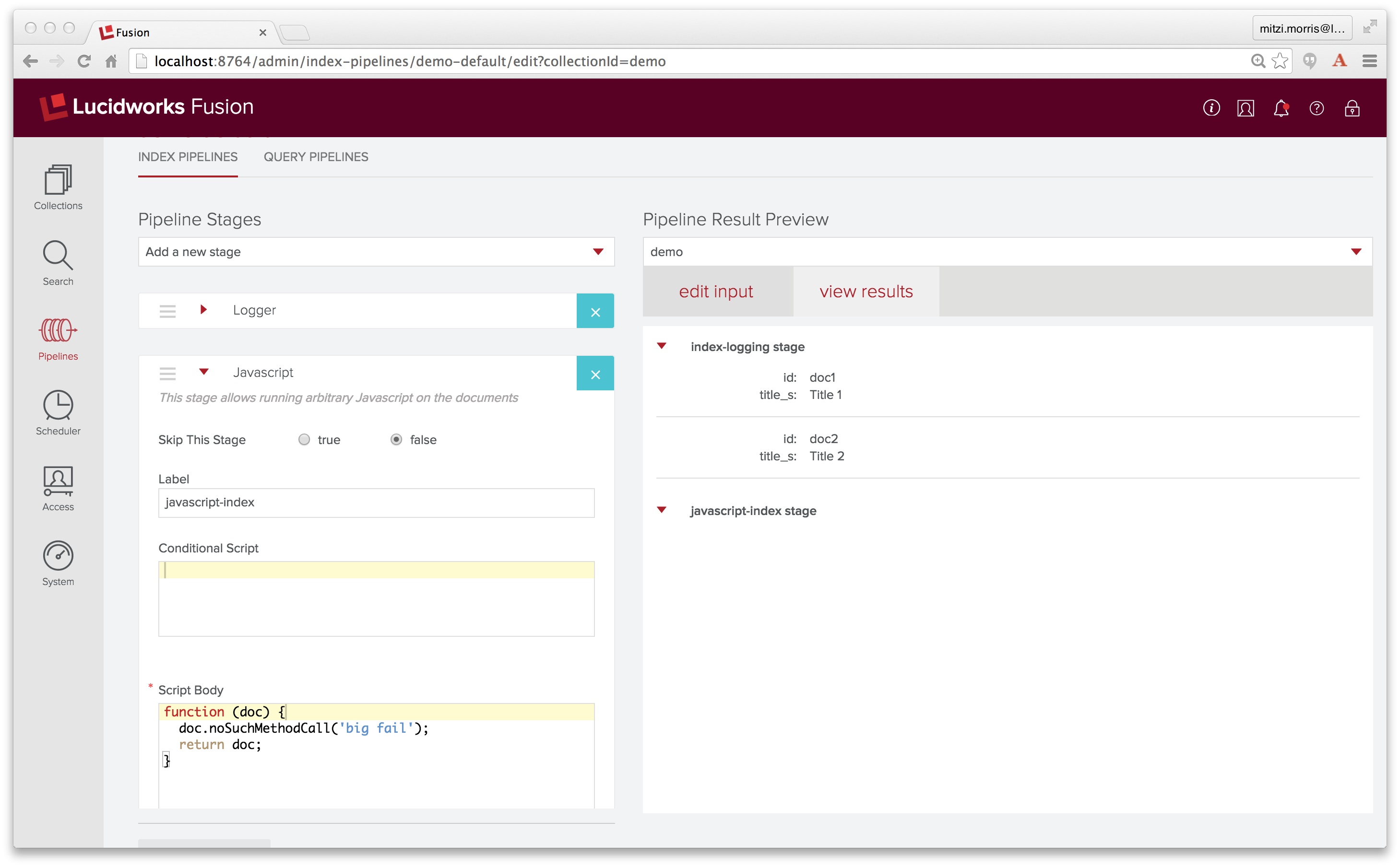
The point of failure in the JavaScript can be tracked down by looking in the Fusion log files. For the above example, the Fusion API services log file $FUSION/logs/api/api.log contains the JavaScript compiler error message:
2015-03-25T19:31:58,251 - WARN [qtp2032647428-15:JavascriptStage@205] - Failed to run JavascriptStage javax.script.ScriptException: sun.org.mozilla.javascript.internal.EcmaError: TypeError: Cannot find function noSuchMethodCall in object PipelineDocument [id=doc2, fields={title_s=[PipelineField [name=title_s, value=Title 2, metadata=null, annotations=null]]}, metadata=null, commands=null]. (#2) in at line number 2
at com.sun.script.javascript.RhinoScriptEngine.invoke(RhinoScriptEngine.java:300) ~[?:1.7.0_71]
Debugging a Javascript stage isn’t as easy as it could be, but the payoff is your data, your way. You’ll need to use a Javascript stage when you have some structured input, e.g., JSON or XML, which has internal structure where the mapping from the structured information to a simple fielded document starts at some intermediate level of structure. Given a hierarchical data structure, the root and leaf nodes can easily be mapped to a document field, but extracting information from intermediate nodes and/or interleaving information from different nodes requires extra work.
In the following example, I show how a Javascript stage can be used to parse string-encoded JSON back into a structured JSON object and extract subparts of that object. In this example, the data comes from a set of JSON files stored on my local drive. Each file contains information about a song track, coded up as a set of key:value pairs, of which the following are of interest:
- key: artist, string value: the name of the artist who recorded this track.
- key: title, string value: the name of the track title.
- key: track_id, string value: a unique identifier.
- key: tags, a list of pair-list values consisting of a string and a positive integer.
Here is an example input file:
{ "artist": "Bass Monkey", "tags": [["electro", "100"]], "track_id": "TRAAKBC12903CADFD4", "title": "Electrafluid" }
It would be nice to be able to create a document with fields for track_id, artist, title strings, as well as a multi-valued field for the tags, where only tags which score above some threshold are added to the document. This means that once the object has been parsed into a set of key-value pairs, the value of the key name “tags” must be parsed into an array of 2-element arrays which contain a tag string and a positive integer between 1 and 100. Representing this as an array of n 2-element arrays, for every element at index i, get the first element of the nested array: tag-array[i][0]. A simple task, right?
Unfortunately, there isn’t an out-of-the-box solution to this problem, because the JSON data has more structure than the current set of Fusion pipeline stages can handle. As a first try, I processed this dataset using the lucid.anda filesystem crawler and the conn_solr pipeline which consists of an Apache Tika Parser stage, a Field Mapper stage, and a Solr Indexer stage, in that order. This pipeline produced documents where all the names and values in the file had been flattened into a single field called “contents”. By inserting logging stages into the conn_solr pipeline and looking through the logfile $FUSION/logs/connectors/connectors.log, I see that the Tika parser stage operates on a PipelineDocument with field named “_raw_content_” which contains the MIME-encoded binary file contents:
"name" : "_raw_content_",
"value" : [ "[B", "eyAiYXJ0aXN0IjogIkJhc3MgTW9ua2V5IiwgInRhZ3MiOiBbWyJlbGVjdHJvIiwgIjEwMCJdXSwgInRyYWNrX2lkIjogIlRSQUFLQkMxMjkwM0NBREZENCIsICJ0aXRsZSI6ICJFbGVjdHJhZmx1aWQiIH0K" ],
"metadata" : { },
"annotations" : [ ]
}
The Tika parser transforms the raw content into plain text. This is added to the PipelineDocument as a field named “body”, which contains the contents of the file, verbatim. Because the logging information is in JSON format, the file contents are printed as JSON-escaped strings.
"name" : "body",
"value" : "{ "artist": "Bass Monkey", "tags": [["electro", "100"]], "track_id": "TRAAKBC12903CADFD4", "title": "Electrafluid" }nn",
"metadata" : { },
"annotations" : [ ]
}
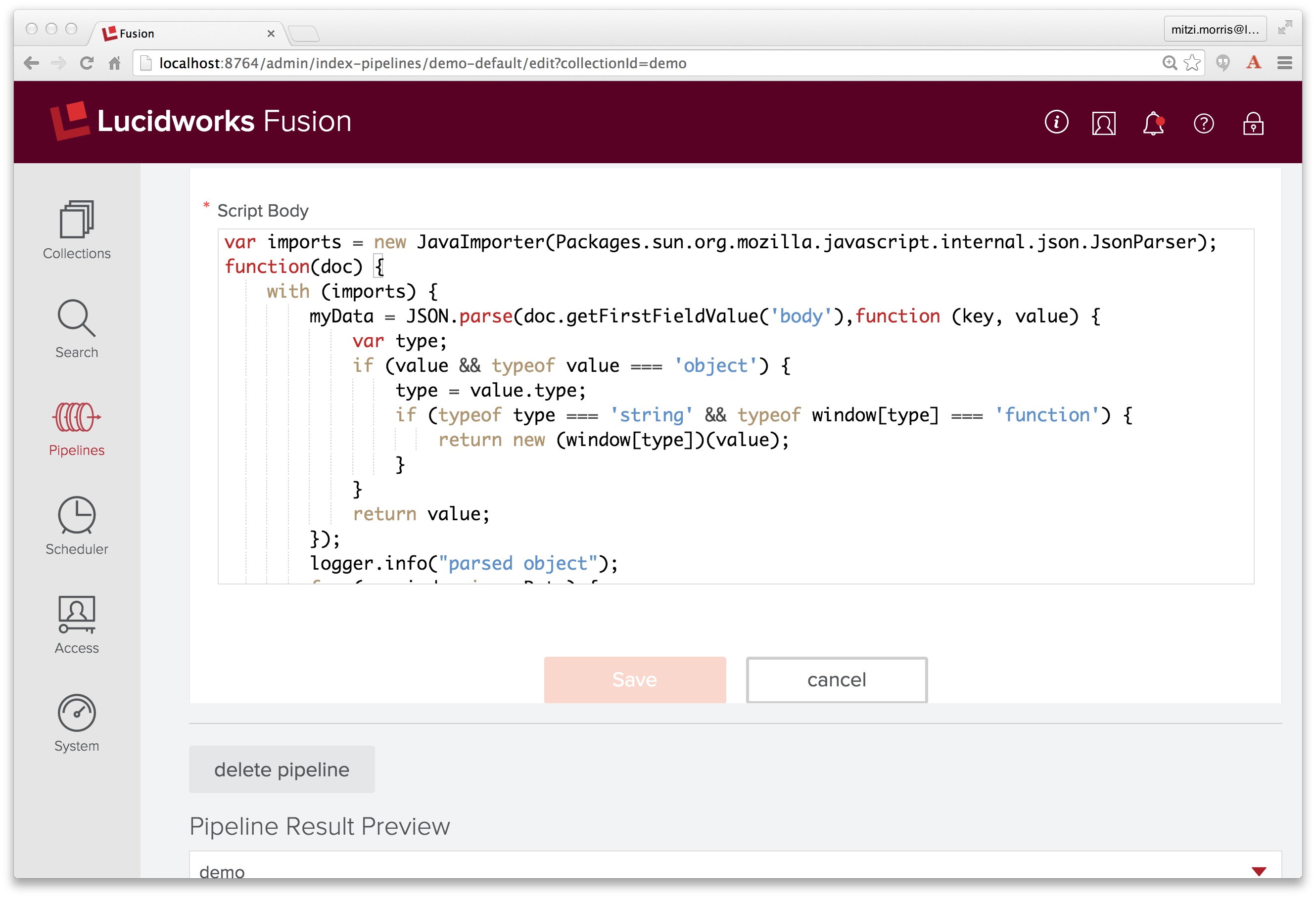
The best solution is to write a custom Javascript stage. Here is the JavaScript code that does this:
var imports = new JavaImporter(Packages.sun.org.mozilla.javascript.internal.json.JsonParser);
function(doc) {
with (imports) {
myData = JSON.parse(doc.getFirstFieldValue('body'));
logger.info("parsed object");
for (var index in myData) {
var entity = myData[index];
if (index == "track_id") {
doc.addField("trackId_s",entity);
} else if (index == "title") {
doc.addField("title_txt",entity);
} else if (index == "artist") {
doc.addField("artist_s",entity)
} else if (index == "tags") {
for (var i=0; i<entity.length;i++) {
var tag = entity[i][0];
doc.addField("tag_ss",tag);
}
}
}
}
doc.removeFields("body");
return doc;
}
This is some serious JavaScript-fu! The ECMAScript standard provides a function JSON.parse that parses text into a JSON object.
The first line of the script body imports the class that has the JSON.parse function. The rest of the script iterates over the top-level object entities, and extracts the artist, title, and track_id information and adds them to the document as separate fields. For the array of tags, it uses array indices to extract each tag. In this example, the final operation is to remove the field “body” from the PipelineDocument using the removeFields method. This could also be accomplished in a field-mapper stage.
I’ve created a pipeline similar to the “conn_solr” pipeline which consists of an Apache Tika Parser stage, followed by Logger stage, followed by a Javascript stage and I’ve cut and pasted the above script into the Javascript stage “script body”:
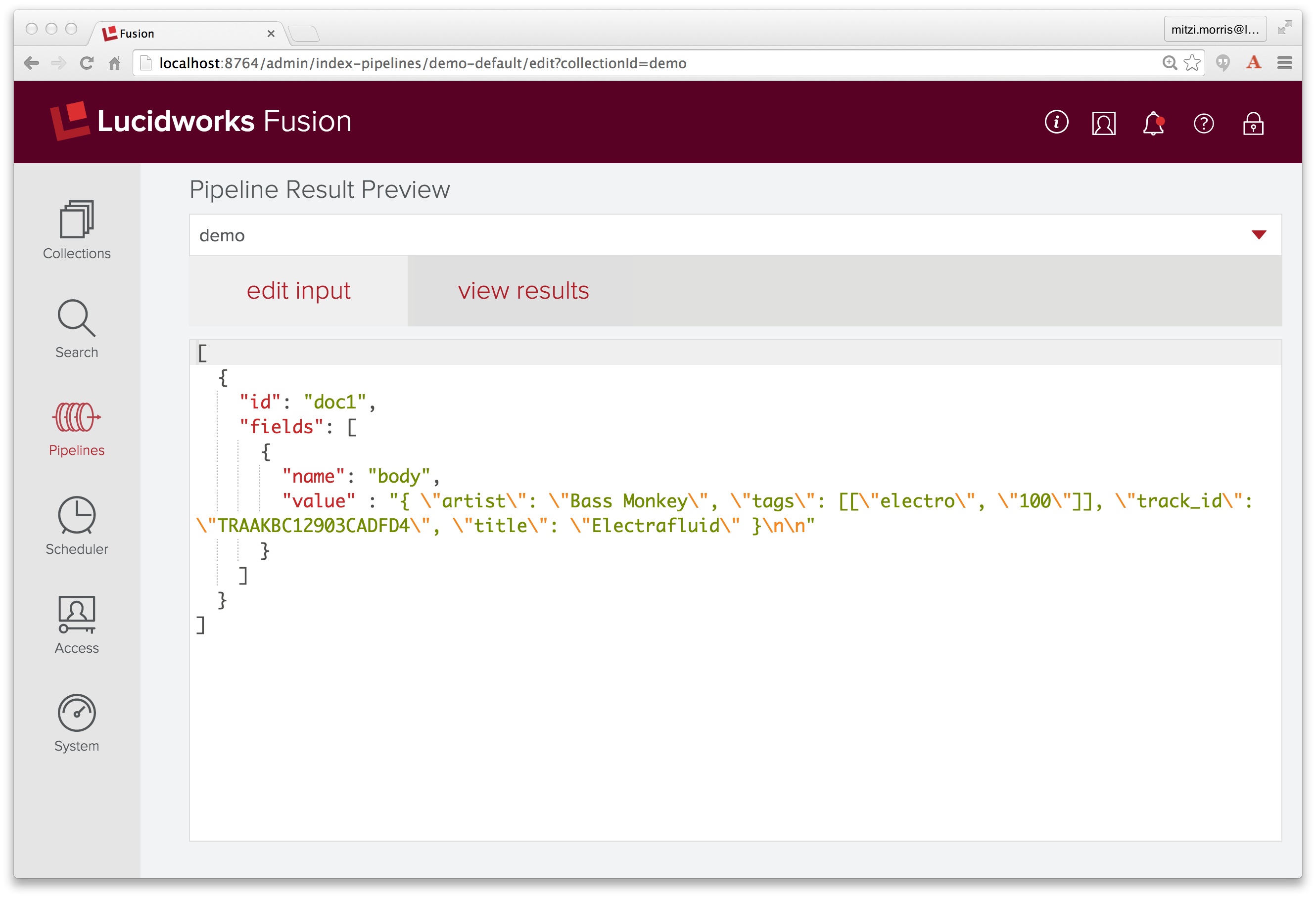
To see how this works, I use the pipeline preview tool. I create a document with one field named “body” where the value is the string-escaped JSON song track info from the logfile:
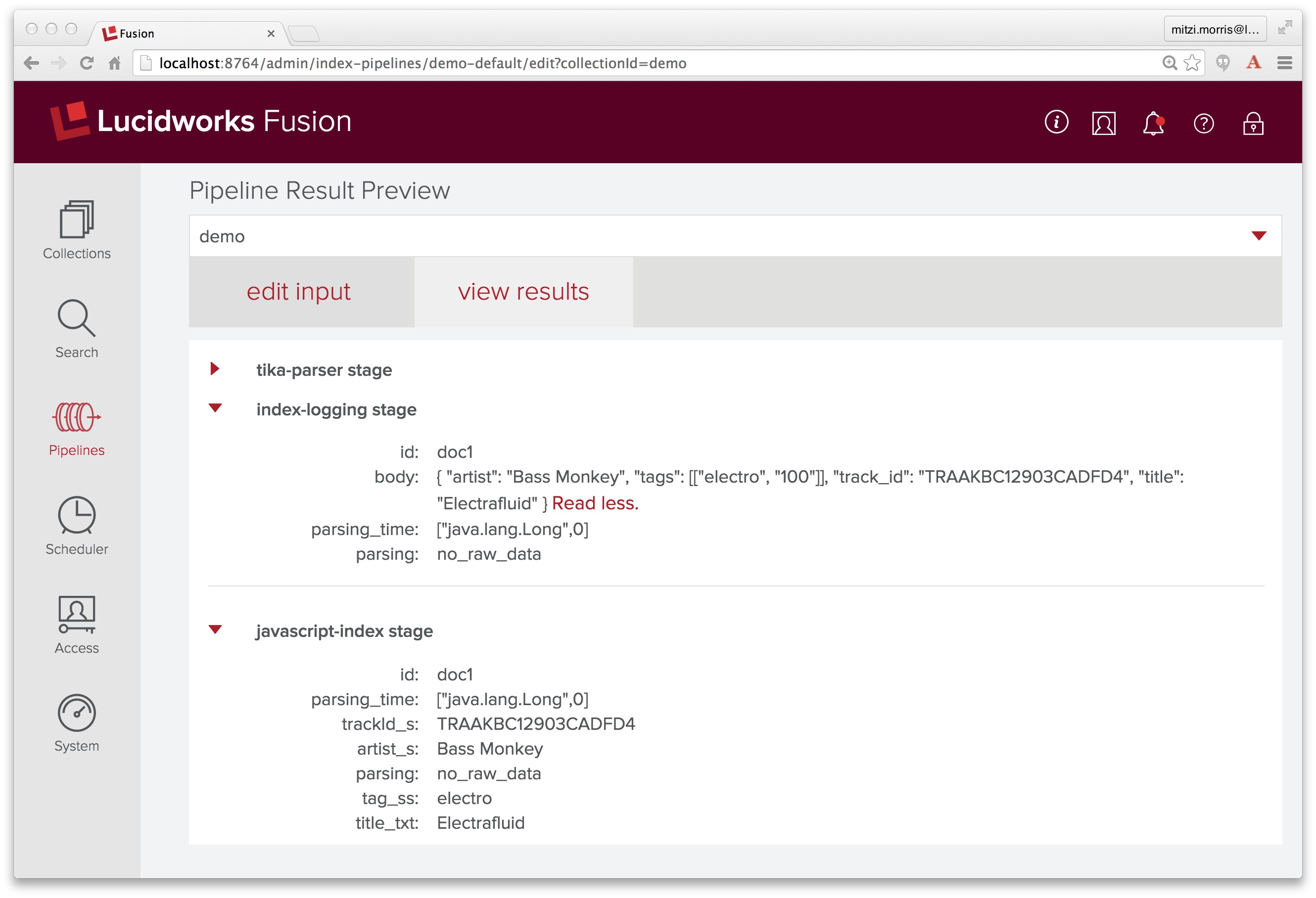
I click over to the “view results” tab, et voilà! it all just works!
A Javascript stage combines the versatility of a Swiss Army Knife with the power of a Blentec Blender, and therefore carries a few warning labels. Once you’ve mastered the form, you might be tempted to use Javascript stages everywhere. However, it is generally more efficient to use a specialized pipeline stage. Use cases for which a specialized pipeline stage already exists are the following stages which filter, add, or delete fields from a document:
- Short Field Filter index stage. This removes field values from a pipeline document according to a set of filters where each filter specifies a field name and a minimum length. All field values less than the specified length will be removed from the document.
- Find Replace index stage. This does a global find and replace over a set of documents using a pre-specified set of rules, where each rule specifies a pair of strings: match string and replace string. The use case for this stage is when processing a collection of documents where the document text may contain a certain amount of boilerplate text, e.g., disclaimers in email messages.
- Regular Expression Extractor index stage. This performs a regex on one field and copies matches into a new field.
- Regular Expression Filter index stage. This removes a field or fields from a PipelineDocument according to a set of filters where each filter specifies a field name and a regular expression. If a field value matches the regular expression, the field is deleted from the document.
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.