Machine Learning in Fusion 4
Fusion 4 is the latest release of our AI-powered search platform and one of the most substantial releases to-date. Fusion 4 continues the evolution of our combination of Solr and Spark while adding the option of deploying App Studio (based on our acquisition of Twigkit). You can learn more about Fusion 4 from the recent webinar.
Fusion 4 is a major step for the industry in terms of understanding how central search is to the practical use of artificial intelligence generally but machine learning more specifically. This is called many things: cognitive search, insight engines and AI-powered search. However, it means that with Machine Learning we have moved beyond the era where mere keyword and keyphrase search are sufficient. Fusion makes machine learning accessible to every business and simplifies its implementation across the IT organization.
Let’s look in more detail at Fusion 4’s machine learning features.
Signals
But before we look at machine learning, let’s review the data that fuels it: signals. You’re sending signals right now. You clicked on a post on machine learning and Fusion 4 either from a link on our site or blog, an email, or from a search result. You’ve made it this far down the page of this post. If I turn that into data and send it to Fusion, it can use that behavioral data to tune search results. For developers this means capturing clicks and sending them to a REST endpoint as JSON. It looks like this:
[
{
"id":"288fe4f7-6680-403e-8d18-27647cdd9989",
"timestamp":1518717749409,
"type":"request",
"params":{
"user_id":"admin",
"session":"ef4e00cd-91bb-45b4-be80-e81f9f9c5b27",
"query":"USER QUERY HERE",
"app_id":"SEARCH APP ID",
"ip_address":"0:0:0:0:0:0:0:1",
"host":"Lucids-MacBook-Pro-5.local",
"filter":[
"field1/value",
...
],
"filter_field":[
"field1"
]
}
}
]
Using this data Fusion is able to imply user interests. Based on those interests, Fusion is able to tailor search results and make recommendations. While there are other forms of signal data (location, shopping cart adds, returns, etc) this kind of “clickstream” data is by far the most common.
Signal Boosting
Fusion 4 is self-tuning; as more users query and click, the quality of the search results just gets better and better. This is based on “signal boosting.”
Let’s think of this in the simplest terms possible:
Most users tend to click on the first item in a set of results and each subsequent result on the page gets fewer clicks. If users click on a second or third result then that result probably should be higher on the page. Fusion 4 includes “Boost with Signals” in its query pipeline by default. All your search application needs to do is send it the signals. Purists may ask if this is machine learning at all since it is basically just “counting” but the effect is that the system “learns” that the latter results are better.
Recommenders
Recommenders are the easiest and most obvious AI tool for search. At its simplest, you know things about a user, their likes and desires through their explicit feedback and implicit actions. For ecommerce this is easy. We’ve talked about using recommenders in the AI and Machine Learning for Omnichannel Retail webinar and the Create and Amazon-like Experience with Fusion ebook.
However, recommenders are not just useful for retail, they are very useful for enterprise search applications (and any other place you might use search). If you’re looking for “employee benefits 2018” on your corporate intranet, you might also be interested in a PDF with the filename “Updates_to_Your_401k_Plan_for_2018.” If you’re working on the same project as other users, chances are you’ll look at similar documents. Whatever the case, Fusion 4 can learn what users need automatically!
Recommenders use events (signals) collected from user activity such as if they like something, click something or query something. Based on these signals and what other similar users did, we can recommend things to those users. Recommendations take different forms depending on your context:
- Items for User – Based on the user’s history, what other items might be of interest?
- Items for Item – Other users who were interested in this particular item were interested in other items.
- Users for Item – Which users might be interested in this item?
Classification
When trying to determine user interests, the “type” of thing they are interested in is often a good indicator. For retail this means things like department or category the product is in. What if that data isn’t determined up front?
Using Fusion, you can classify data automatically. You can even use that data to help users facet or filter data to the specific department or departments that they need. While this is obvious in digital commerce and retail, it is just as valid for enterprise search or financial search applications (or anywhere else that you use search).
Classification is a supervised learning method. This means you first give Fusion a set of data that has already been classified. Based on this it learns how to classify future items.
Query Intent
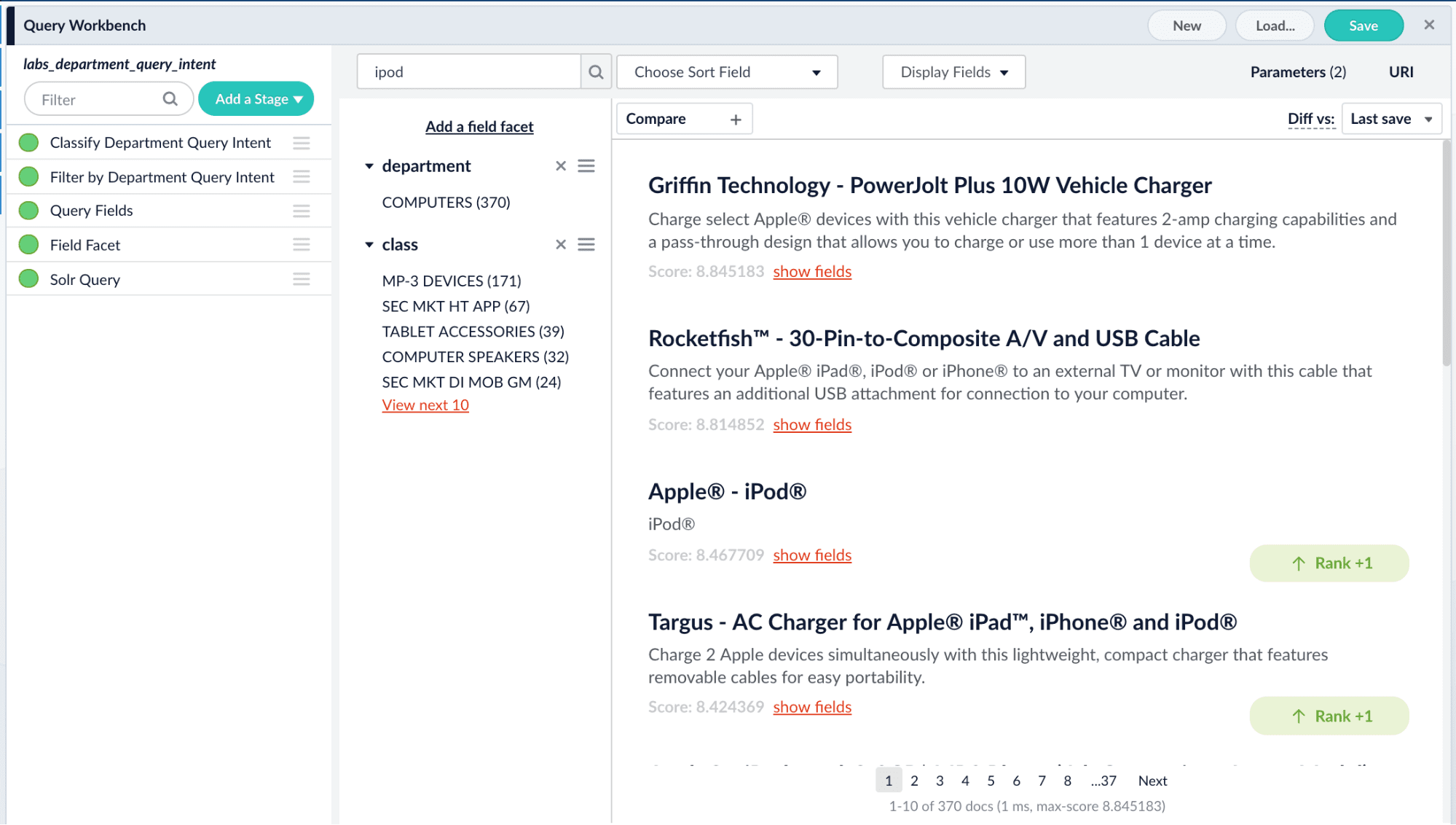
By classifying data we can use this understanding to classify user queries. Meaning when a user types “elvis blue suede” the system might classify this query as music where if the user types “blue suede shoes waterproof” the system might figure out that this is footwear. Based on this the system can choose to boost or filter by our earlier classified department.
The power of this is clear in retail but it is also an important tool for Enterprise Search or Finance. Imagine if I’m searching for “internal employee benefits” or “IBM 10-k filings,” having the system automatically realize that my search should be limited to “HR Document” or “financial statements” or “10-k filings” is likely to improve my results substantially. Sure a user who selects a facet can do this for themselves but documents tend to fall into multiple categories, just because the team in charge of categorizing a document happened to categorize it as “HR Document” doesn’t mean the user will make the association. It is better to have a system that can intuit and learn what a user means so that users can easily find what they need without learning a whole filing system, especially one that may change.
Clustering
Along with the difficulty of categorizing a collection of documents, there’s the challenge of putting them into categories. One option is to use Fusion’s unsupervised learning option, clustering, in order to automatically categorize documents and find the outliers.
What qualifies as an outlier? Maybe one manufacturer puts “colour” instead of “color” or maybe there are common misspellings from a particular vendor. Outliers are just documents that do not fit well into any category that our system can detect. Outliers can be useful to detect anomalous behaviour or documents in your system. Using this information you can tweak the results to better include the outliers.
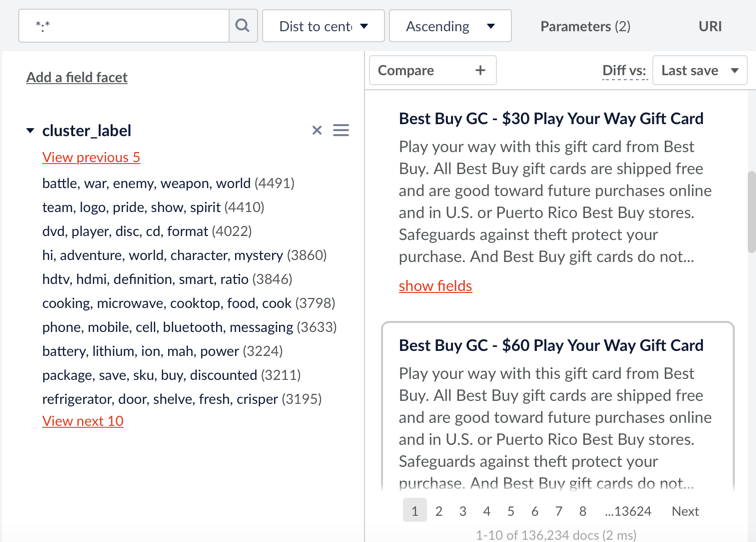
Aside from helping categorize data, you can also learn a lot about the collection you’re indexing. For instance, in ecommerce, which kinds of products each manufacturer tends to make.
Experiments
There is usually more than one way to do things. Maybe when you originally deployed your application, it was configured with basic signal boosting to improve relevancy. But now, your team wants to see if making a more personalized search with recommendations is actually better. Or perhaps you started adding query intent and filtering to categories. Someone asks, “but do we actually get better results.” How do you answer the question?
You experiment. You send some percentage of requests through one path and another set of requests through the other. If it is a web or mobile-based search then obviously whichever got the most clicks (clickthrough rate, or CTR) is the better configuration.
Fusion lets you configure this to happen automatically and even gives you handy charts to prove that it worked. Maybe you have something other than CTR that you want to measure. Fusion will help you there still.
Learning to Rank
Fusion 4 includes Solr 7. Solr recently added an algorithm called “Learning to Rank.” Learning to Rank (LTR) is another classification tool. Basically, sometimes the algorithm that search uses (BM25 by default in Fusion) isn’t sufficient. Instead a combination of “characteristics” about the data and how users actually use the data to teach the system how to order a set of results. We have a webinar on Learning to Rank coming up on April 4th which will go into more detail about some of the results you can expect when combining LTR with Fusion’s signal capabilities.
Head-n-Tail
Although it sounds like a popular shampoo, it is actually a way to learn more about your most popular queries (head) as well as the outliers (tail) and how to improve them.
We have a webinar on “Fusion 4 Head-n-Tail analysis” as well as a technical paper which will explain how you can use Head-n-Tail analysis to tune your results.
Apache Spark FTW!
Fusion 4 adds a significant amount of AI capability, it is built upon the shoulder of a giant, Apache Spark. Because of this, you have the power to add your own Spark-based machine learning jobs and even use Spark to manipulate data stored in Fusion.
…And Much Much More!
These are just the highlights of the AI-powered search features added to Fusion 4. We didn’t even touch upon things like Ground Truth, Co-ocurrence and Levenshtein Spell Checking. Fusion 4 is a great leap forward in intelligent, self-tuning AI-powered search.
Learn more
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.