Apache Superset and Lucidworks Fusion (Part 1)

By now, most data practitioners have heard of Apache Superset. If you haven’t, it’s not too late to check it out. It was developed by AirBnB’s data team, and has been adopted by thousands of companies around the world looking for an open source data visualization alternative.
I grew interested in it because of the enthusiasm initially, but I stayed with it because of the immense visualization capabilities. I know some developers and data scientists dealing with a high query volume and high cardinality will benefit greatly from the power of Fusion behind Superset in that way.
After joining Lucidworks, I started to play with Fusion and realized that it could power Superset with some enhanced data processing and query possibilities. Under the hood of the Fusion SQL Engine, Apache Spark optimizes large searches so they do not fall over or require too much time. All the code snippets for this blog post are included in a repo at the bottom of the blog post.
Superset does not purport to be a search engine for parsing millions of documents. Besides, if the search engine (Fusion in this case) supports a connection to Superset and obviously can handle the volume of data it holds, connecting the two seems like an obvious choice. In a later blog post, I will detail connecting Superset to one of our managed Solr instances.
In a nutshell, here are the steps to installing Superset to work with Fusion:
- Download and install Apache Superset
- Download and install Lucidworks Fusion
- Configure Lucidworks Fusion to work in `binary` mode.
- Spin up Apache Superset and Lucidworks Fusion.
- Create an app in Lucidworks Fusion and index data so that you have at least one collection.
- Connect Lucidworks Fusion to Superset in the Superset UI and add tables from your Fusion collection into Superset.
- Create your first chart
Download and Install Apache Superset
Apache Superset is super easy to download, install, and get up and running. These steps are taken from the official documentation:
Note: Before you get started, please ensure you have installed Python >= 3.6 and Pandas 23.4 (24 won’t work). I recommend using a Python Virtual Environment.
# Install the latest versions of pip and setuptools pip install --upgrade setuptools pip #Install superset pip install superset # Create an admin user (you will be prompted to set a username, first and last name before setting a password) fabmanager create-admin --app superset # Initialize the database superset db upgrade # Load some data to play with superset load_examples # Create default roles and permissions superset init # To start a development web server on port 8088, use -p to bind to another port superset runserver -d
Alternatively, you can install Superset with Docker
Download Lucidworks Fusion (Skip if Using Already)
Head to the Lucidworks site to download Fusion to your computer: https://lucidworks.com/download/.
# Unpack the fusion tarball in the directory where you want Fusion to live tar -xf fusion-version.x.tar.gz
If you recently upgraded your system Java version to 11, Fusion only supports Java 8 so you may need to run a command. Run java -version to check. If you need to temporarily roll back to 8, to spin it up, run this command to:
Export JAVA_HOME=`/usr/libexec/java_home -v 1.8`
Configure Lucidworks Fusion to Support Apache Thrift in Binary Mode
This blog post introduces a way to configure Fusion such that it will support a connection to Superset. Configuring Superset to run with Fusion is possible but requires a bit more effort. Here are the steps to configure Fusion to work support binary mode in Thrift so that you can issue SQL queries directly from Superset’s powerful visualization engine.
From your fusion dir, the result of extracting the tar ball from step 2 and referred to in the ${FUSION_HOME}, move into the configuration directory where you will make your changes:
cd conf/
Open ${FUSION_HOME}/conf/sql-log4j.xml add this line near the bottom of the file, after all the other logger configurations:
<logger name="org.apache.thrift.server.TThreadPoolServer" level="FATAL"/>
It will tone down some of the non harmful “No data or no sasl data in the stream” errors.
Then, open the Hive configuration file, ${FUSION_HOME}/conf/hive-site.xml, and make a few changes.
First, change hive.server2.transport.mode from http to binary and the following configs for the port and the permissions on the Hive scratchdir:
<property> <name>hive.server2.thrift.port</name> <value>8768</value> </property> <property> <name>hive.scratch.dir.permission</name> <value>733</value> </property>
Finally, open ${FUSION_HOME}/conf/fusion.properties and add spark-master, and spark-worker as group defaults. If you have already been using Fusion, ensure that sql is included there as well.
Start Lucidworks Fusion
To start Fusion:
${FUSION_HOME}/4.1.2/bin/fusion start
Create a Collection in Lucidworks Fusion (skip if one exists)
The easiest way to get a collection in Fusion is to use the sample data we have packaged with the Fusion demo. To simplify this process even further, I have included a quick set of steps below to demonstrate how you can create a Fusion collection leveraging Iowa liquor sales for use in Superset:
From the launcher screen, click the button to create a new app:

Create an app called supersettest:
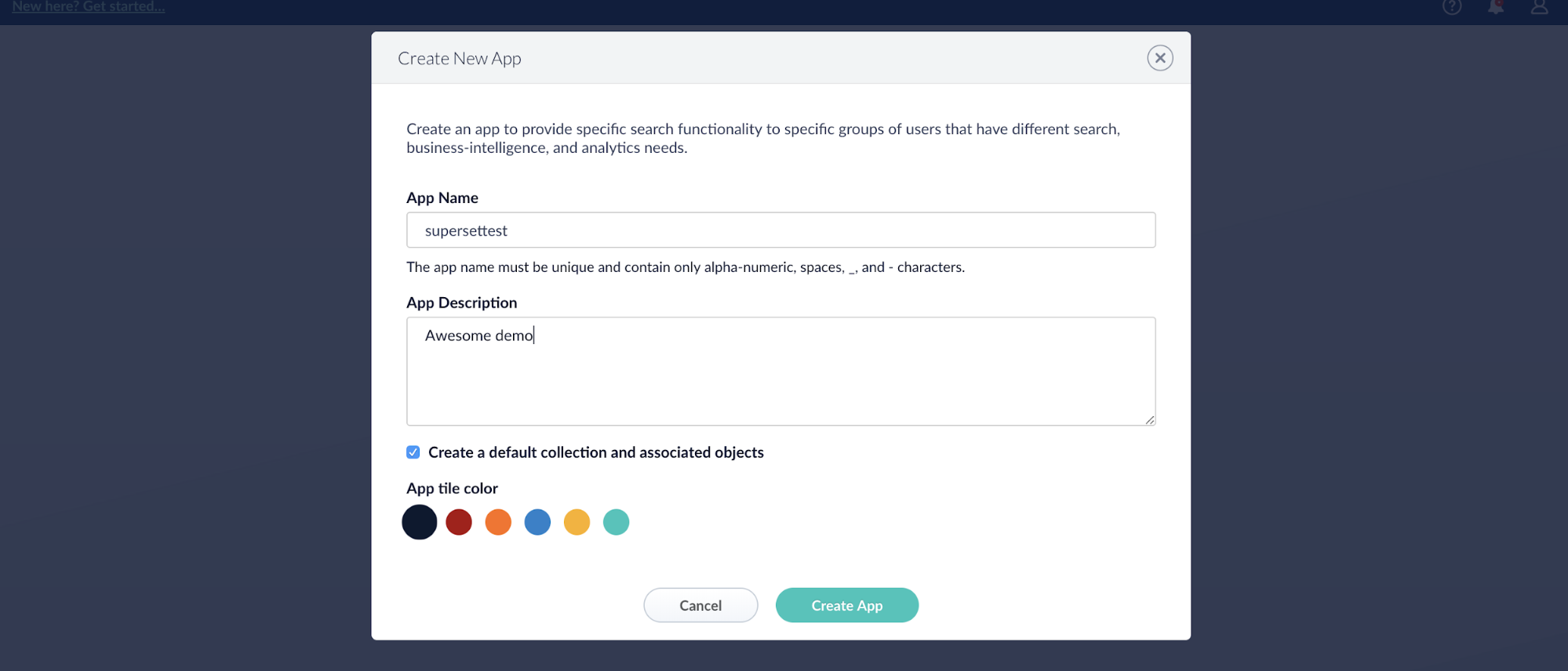
In the upper left of the application, if you see “New here? Get started…” click that link. If you do not see the link, click in the upper left corner of the application to “Return to Launcher,” where the “New here? Get started…” link will be in the upper left corner. In there, you can follow a fairly straightforward quickstart wizard to index data that will be your first collection.
Import things to note for this tutorial:
- When you reach “Index Data,” select Iowa “Liquor Sales Data”
- When you reach “Query Data,” click the X in the upper right corner to close the Quickstart wizard
Connect to Lucidworks Fusion in the Apache Superset UI
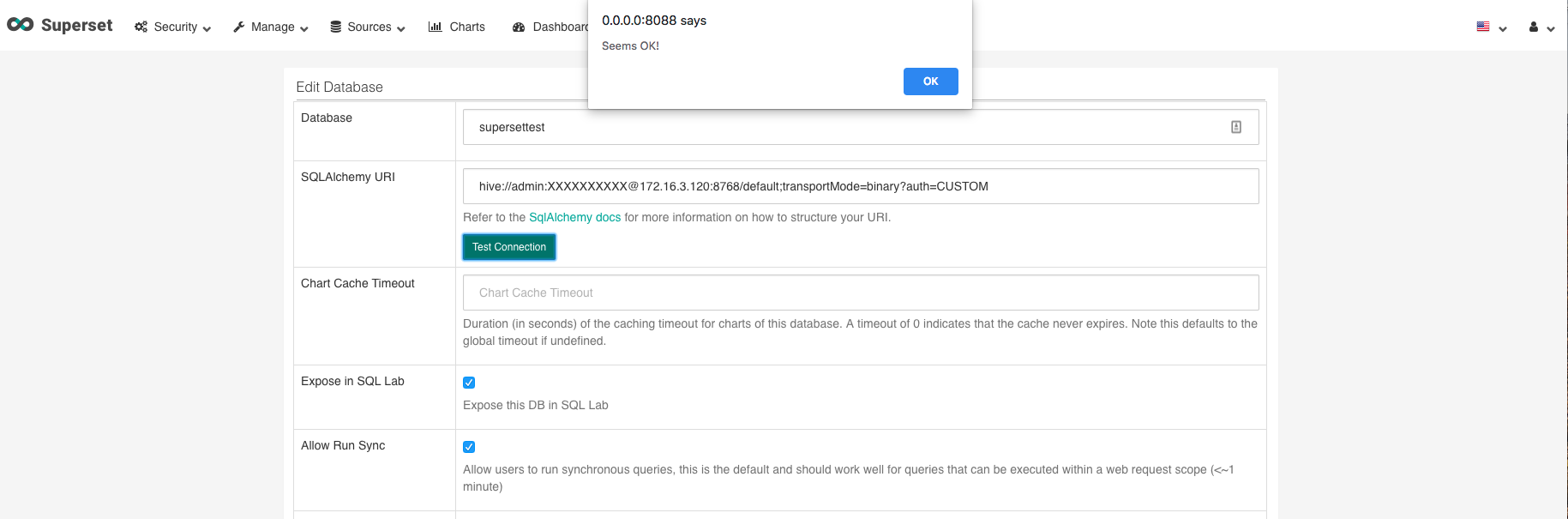
Log into the Superset UI and hover over sources and click databases in the navigation bar at the top of the page. On the edit databases page, you need to include a name and SQLAlchemy UI for your database.
For the name, include supersettest or one of your choosing.
For the SQLAlchemy URI, you need to include the following value, where username and password are your Fusion username and password, and the IP is your Fusion IP:
hive://<username>:<password>@<ip>:8768/default;transportMode=binary?auth=CUSTOM
Once the information is entered, click the button to test the connection. If you see a dialog that says, “Seems OK!,” you’re connected and almost ready begin building visualizations.
Then, click the “Save” button.
After saving, return to the top navigation and click Sources > Tables. In the Database field, add supersettest. You also need to add a schema and table name. The schema should be default, while the table name should be the name of your Fusion collection. In Fusion, you can see the collection name in the Collection Manager emboldened in the upper left. No other configurations are needed at this time.
Create Your First Chart
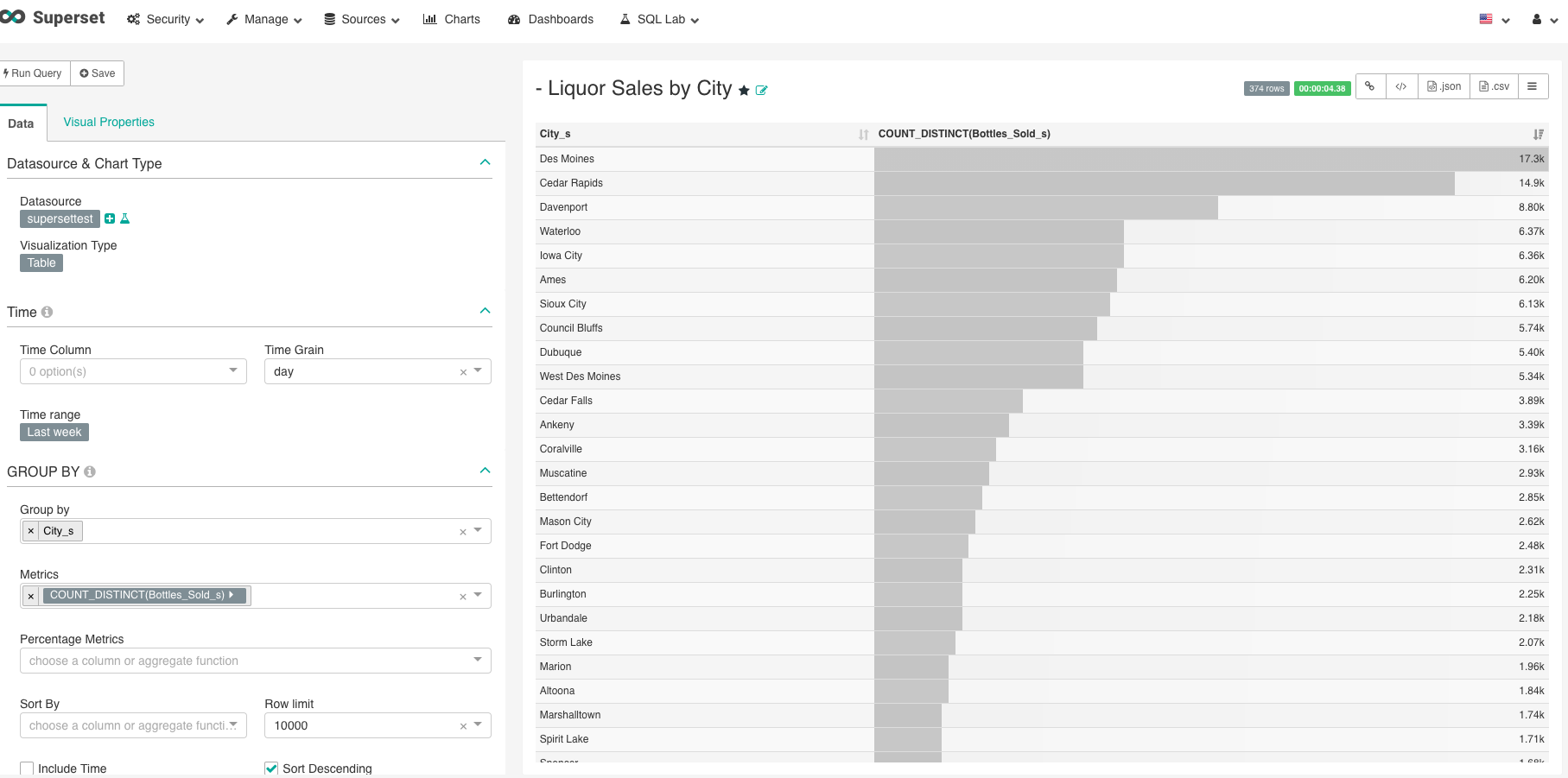
- Click Charts in the top navigation
- Click the plus sign in the upper right of the list view, to the right of Add Filter
- For Datasource select supersettest
- For Visualization Type choose Table
- For Group_by select “City_s”
- For Metrics select “Bottles_Sold_s”
- Then, click “Run Query”
- Enjoy a very fine data visualization suite on top of a battle-tested and robust data processing engine.
For help debugging this integration or any problems with this tutorial, open an issue on GitHub in the repo for this tutorial, or comment on this post.
In the next part of this tutorial, I will demonstrate how to quickly transform a large amount of data in a document corpus for visualization in Apache Superset.
Learn More
- Read Using Tableau, SQL, and Search for Fast Data Visualizations
- Contact us, we’d love to help
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.