How Big Data Is Failing the Pharma Industry
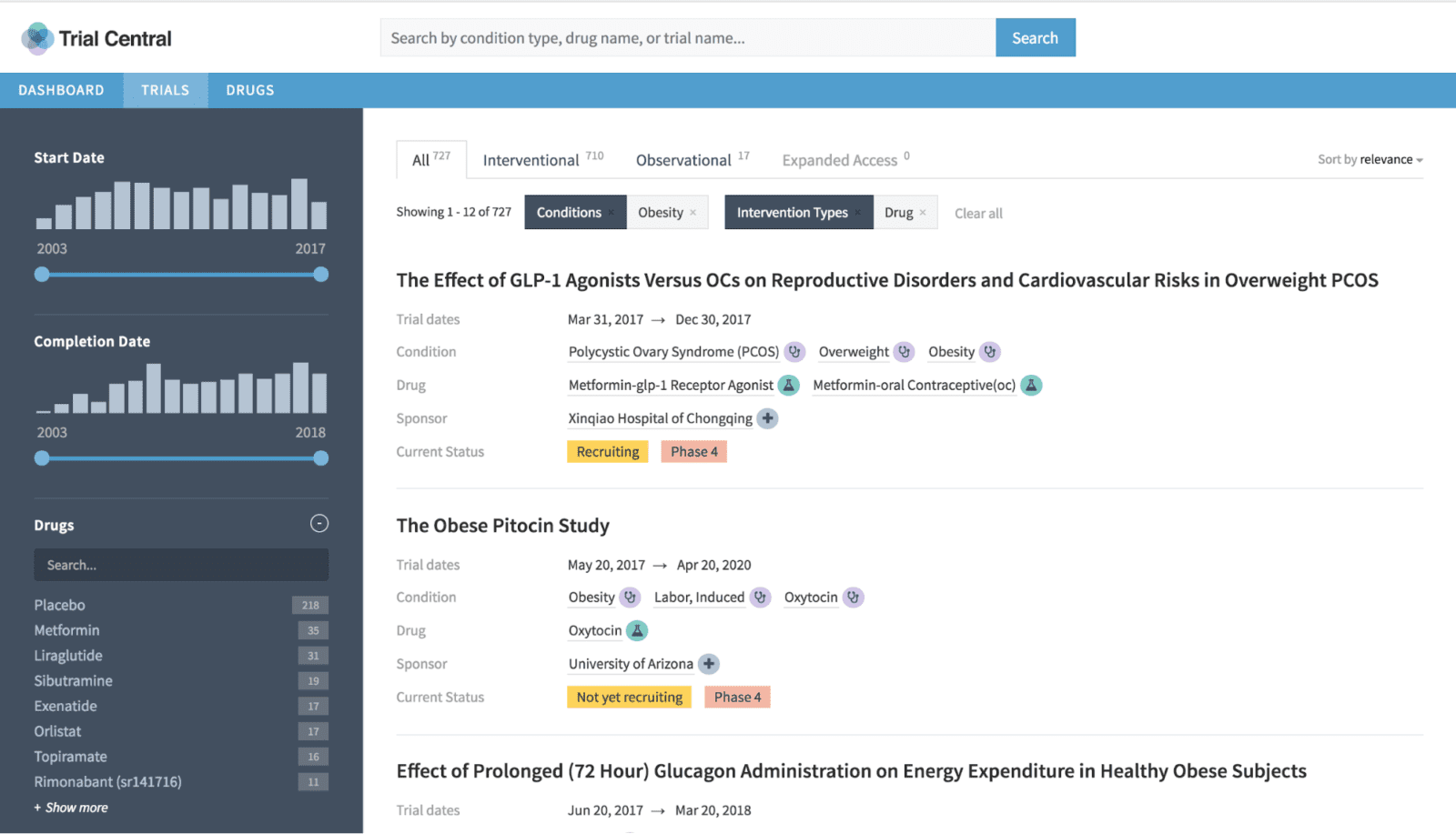
The pharmaceutical industry generates ever increasing volumes of data, so it isn’t surprising that pharmaceutical companies have spent a lot of money on big data solutions. Yet most of these systems haven’t yielded the kind of value that was initially promised. In short, “Eroom’s Law” – the slowdown in bringing drugs to market despite improvements in technology – has yet to be broken and these big data “solutions” have yet to bare fruit.
Part of the problem is one of extremes. Previous systems for the pharma industry were based on antiquated, heavily-structured paradigms. These data warehousing systems assumed that you captured and composed data with specific questions in mind.
In recent years, the pharma industry has invested heavily in “data lake” style technologies. Essentially, capture the data first and hope to find a use for it later. While the amount of data captured has increased, we’re still waiting for the outcomes.
As Philip Bourne of the Skagg School of Pharmacy put it, “We have this explosion of data which in principle allows us to do a lot. […] we’re starting to get to an understanding of complex systems in ways that we never have before. That should be impacting the drug discovery process. At this point in time, I don’t think it is, but I think we’re on the cusp of a turnover. And of course the information technology that’s needed to do all this […] is obviously improving. So, let optimism rule.”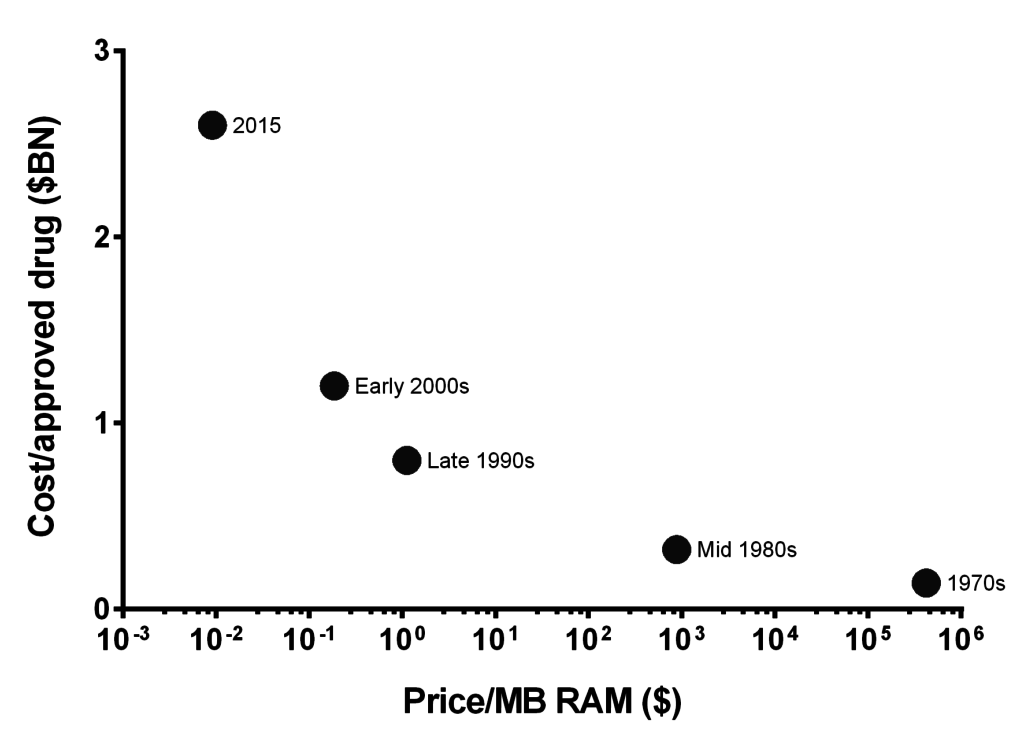
But the Data Lake Isn’t Quite Right
Data warehouses aren’t enough. Organizing data into clear table structures or cubes for answering one research question is a bit “too far down the line” to work in a HOLNet or modern pharmaceutical research approach. This is still useful at some point in the drug development lifecycle, but it is too rigid for more general use.
At the same time dumping everything into a data lake – a big unstructured store – and digging it out with analytics tools hasn’t really worked that well either. Actually, that hasn’t worked anywhere. It is a little like deciding that building warehouses didn’t keep up with production, so we built a big fat ditch and shoveled the data in there. The warehouse was at least well organized. Does anyone feel that way about their data lake?
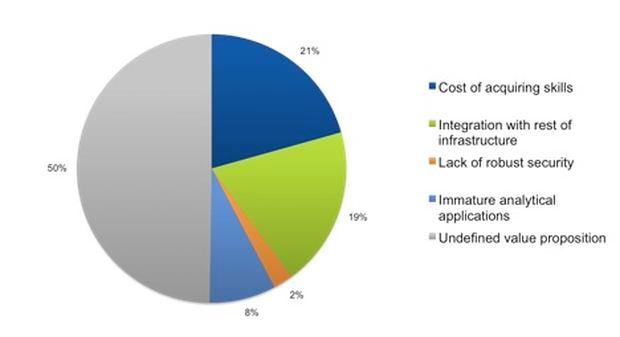
Source: 451 Research
A big problem with the data lake approach is that it throws the baby out with the bathwater. A data lake is like having the internet, with everything you’d ever want to know at your fingertips, but with no Google. Some companies have tried methodical approaches similar to using a card catalog and librarian to manage the data (i.e. data management and curation solutions). Clearly, with pharma data doubling every five months these approaches aren’t very likely to work now or in the long run.
Off-the-shelf Analytics Tools Are Inadequate
The analytics market is huge, there are hundreds of vendors with thousands of offerings. Meanwhile, it never ceases to amaze me what people can do with simple tools like Microsoft Excel and a VLOOKUP. However, using generic domain-agnostic analytics tool like Tableau to analyze complex, pharmaceutical research and clinical trials data is like draining a lake with a teaspoon.
Generic tools don’t understand the domain, and the metadata is too abstract for a researcher or analyst to navigate a dataset easily. Moreover, if only a few experts in an organization can understand the data, it fails to serve the modern networked approach of developing drugs and biologics.
A Different Approach To Data Storage
What is needed is a storage mechanism that is both flexible and organized. However, the most important thing is also the simplest: data should be indexed at the storage level as was the case in the decades before data lakes. Otherwise, loading the data (even into a memory-based solution) takes an eternity. Indexes are what is needed to find anything efficiently. They are the “Google” of your internal storage.
Data storage must:
- Allow data to be organized in flexible document structures with a schema that is easily added to.
- Scale as the volume of data grows (doubling every 5 months)
- Perform full-text, ranged, and other kinds of searches quickly with sub-second response times.
- Most of all be flexible. There are future uses for the data we don’t yet know about. Change is a constant. Rigid structures and tools break down under the pressure of modern pharmaceutical research, development, and marketing.
Better Analytics and Information Sharing
Analytics tools shouldn’t be so heavily customized as to incur the money or time cost of a massive IT project, but should be domain-aware and purpose-specific enough to allow sharing across research, development, marketing, and beyond without the need for data specialists to answer every question.
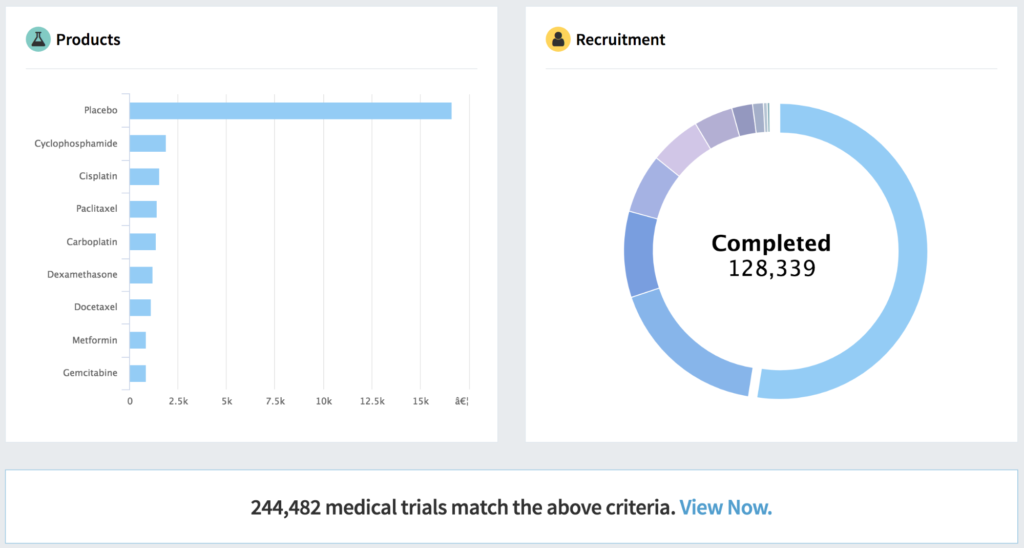
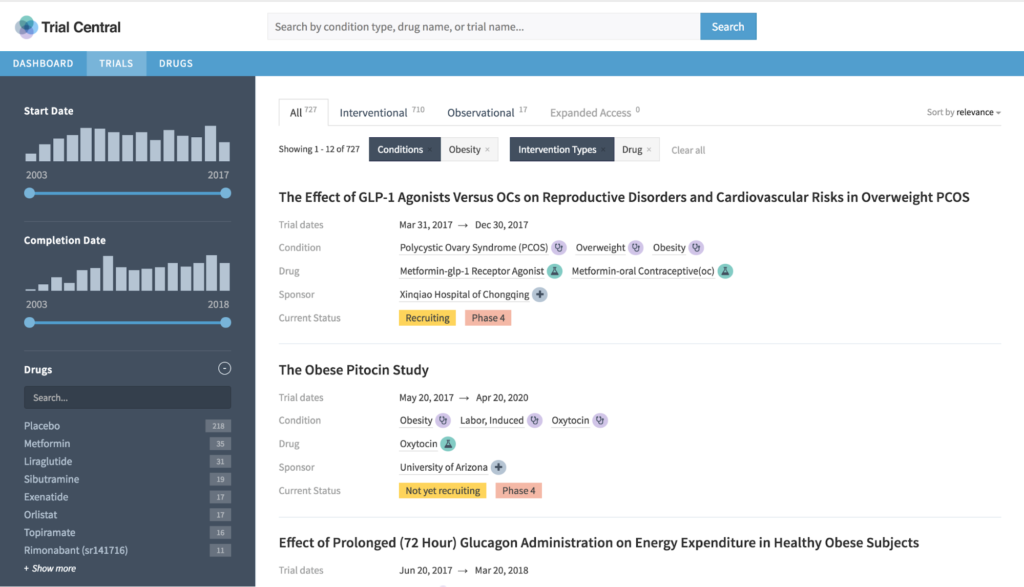
Out-of-the-box tools are great, but insufficient for the task. Just like pharmaceutical plants are built out of a combination of prefabricated, off-the-shelf and custom parts and materials, so must pharmaceutical analytics and information systems. They can’t be completely custom, nor completely generic. They should essentially be “fit for purpose.”
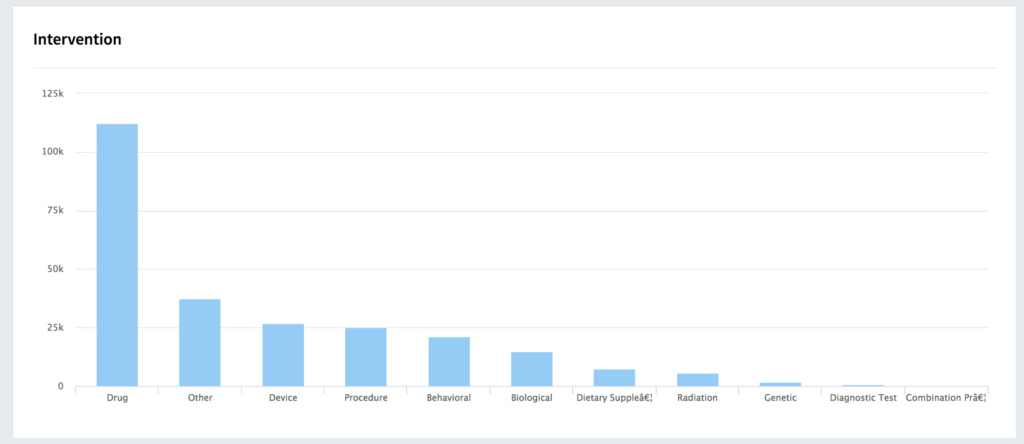
Better Data Management
There is too much data coming in too quickly to be manually curated. Incremental data enrichment and enhancement systems are needed. Data must be identified, tagged, enhanced, culled, and combined in increasing volume, and sometimes in real-time.
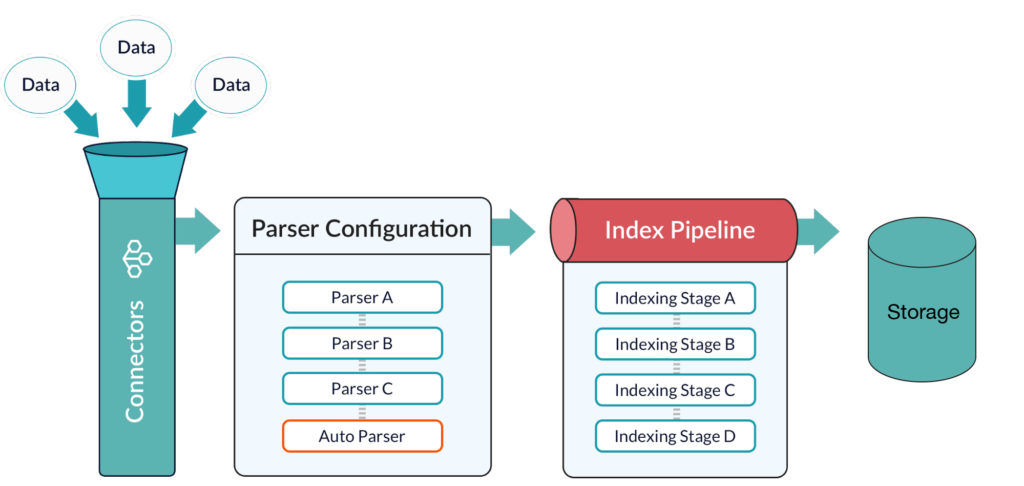
Additionally, new techniques using artificial intelligence technologies, like machine learning and deep learning, are required for modern data management. AI finds patterns and allowing the system to cluster and classify data on the fly. AI does not abrogate the need for industry knowledge and expertise, but augments it to allow researchers and marketers alike to deal with ever increasing amounts of data.
…In other words, these tools help turn data into actual information.
With ever increasing amounts of data, including clinical trials data, molecular data, Electronic Health Records (EHR/EMRs) and soon even data from smart pills, the pharmaceutical industry needs solutions that flexibly store, augment, transform, match, share, and analyze data. The systems need to scale with the data and facilitate it throughout the organization. Generic analytical tools and data lakes have failed to facilitate increased productivity and profitability. New and better approaches are needed.
Learn more:
- Download “Connecting the Dots: Building Data Applications for Life-saving Research”
- Sign up for our webinar “Understanding Clinical Trials Data”
- Contact us, we’d love to help!
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.