7 Search-Related Halloween Horrors

I’m not saying that your search platform is bad if it doesn’t fully address these issues… I’m saying it is horrifying! I’m saying you should dress it up on Halloween and put it in your yard to scare children away (so you can eat all the candy yourself)!
Here are 7 ghoulish limitations that no search app should tolerate:
Security Not Enabled

Years ago, I worked for a company with poorly tuned, insecure intranet search. At that company, I found files showing a plan which involved laying off the entire department I was in – months before it was intended to go into effect. I was the last guy who really knew Oracle and the company really needed me there until it could phase out our department. However, there was nothing in the plan about a long and generous severance and I had rent to pay, so I found a new job months in advance.
Security integration and security trimming allow you to ensure that users do not see documents in search results they don’t have permission to access. This also applies to content repositories like SharePoint, Box, or Google Drive. You configure this at index time to capture permissions from the repository and supply a username parameter at query time in order to filter the search results.
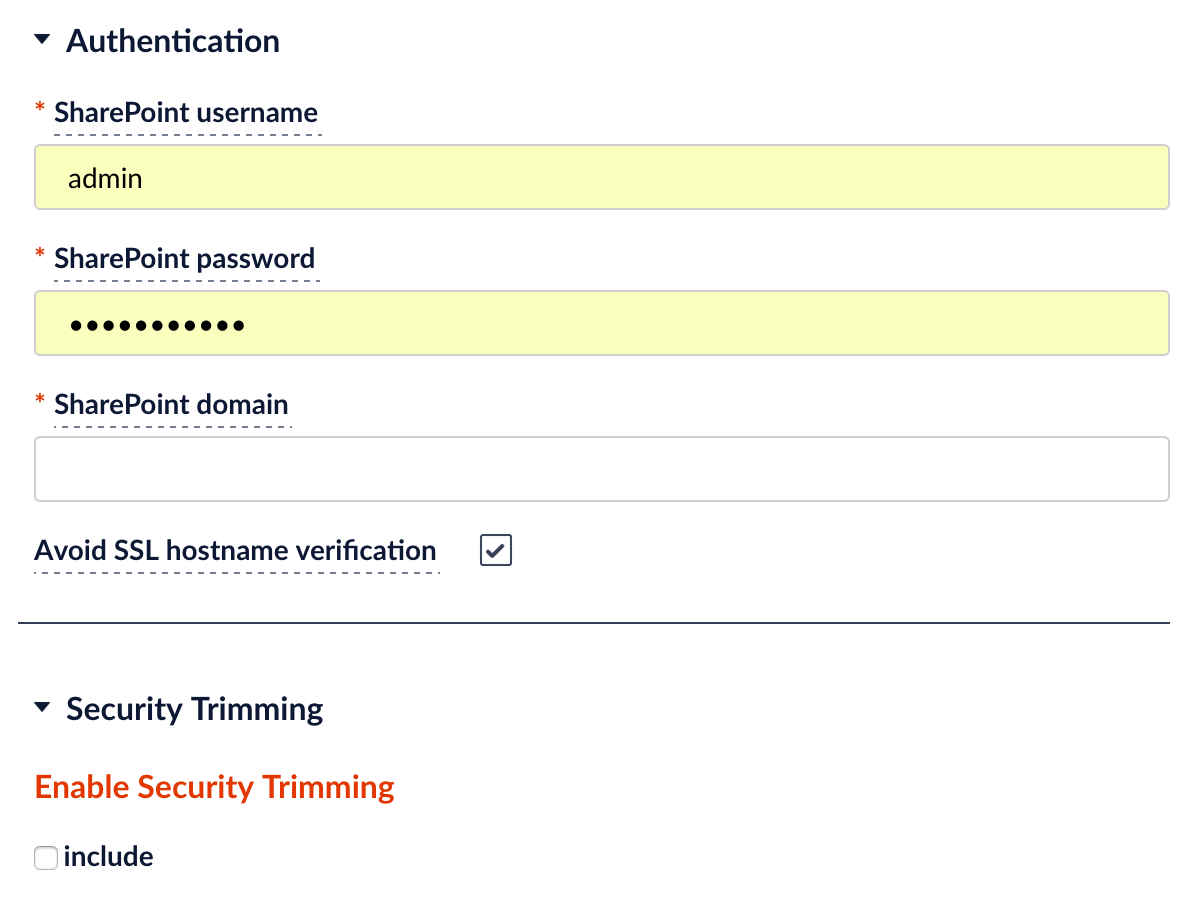
No Idea What Terms to Start With

When I see a blank search box and type the letter “A” and nothing comes up, it is rather jarring. In the early days of search, this was expected behavior. Even Google worked that way. However with auto-complete on a smartphone or auto-suggest on Google and Amazon, everyone expects some kind of direction as they start typing in the search box.
Suggestions and typeahead supply keywords to users as they type their query. This feature is frequently combined with category suggestions (facets) to help tune search to exactly what the user is looking for. There is no reason to fly blind.
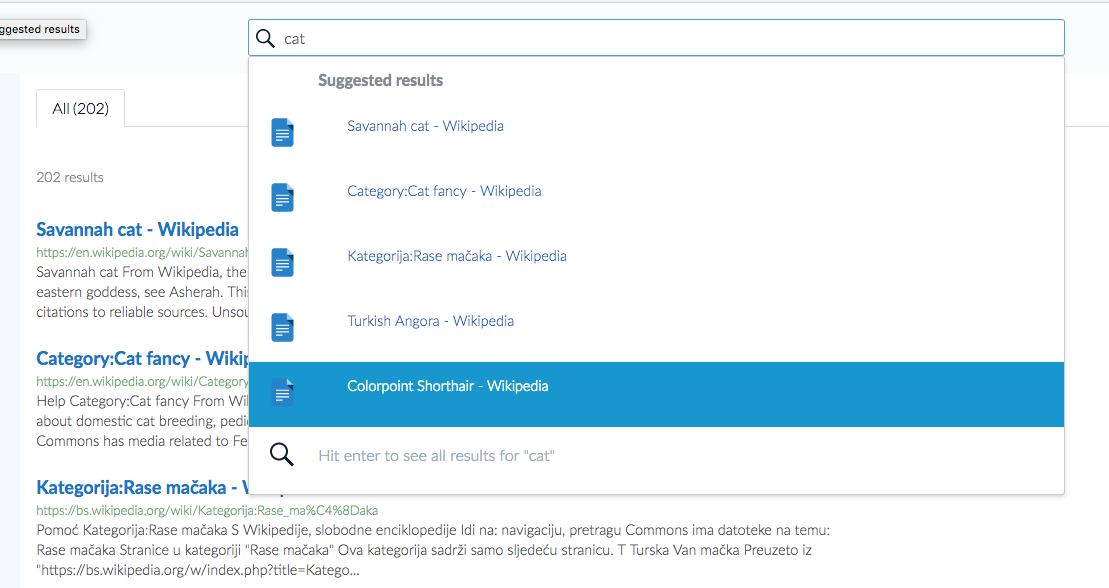
No Categorization

In a modern Fortune 1000 company there is no shortage of data. It is insights that matter. Data consolidation and being able to search across data sources is absolutely essential to answering the kinds of hard business questions teams must answer every day. However, a keyword search that isn’t tuned to any particular area or domain will tend to return noise.
Faceting allows users to limit their search to some subdivision of data that is related to them. If you have a field in your data that lends itself to that naturally then this is easy to do. However, if you don’t then tools like classifiers and clustering are essential. These can either assist a human at categorizing data (supervised learning) or just find which data is related to which without a human getting involved (unsupervised learning).
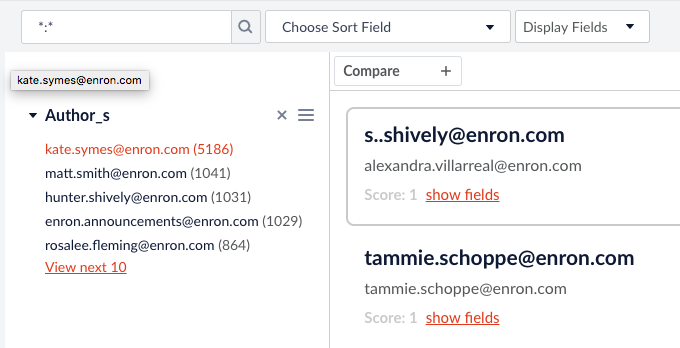
No Measure of Success

There are plenty of companies that deploy search and don’t actually measure or have no way to measure if users are successfully finding… well… anything. Unless users complain, IT just assumes everything is fine. Meanwhile the users that aren’t complaining abandoned the company’s search long ago and either use a series of emailed bookmarks or Google for public sites.
A good search solution includes dashboards with statistics like the top 10 searches with no results. A good search solution shows you statistically significant phrases and helps find spelling errors. A good solution talks to IT and helps IT tune it.
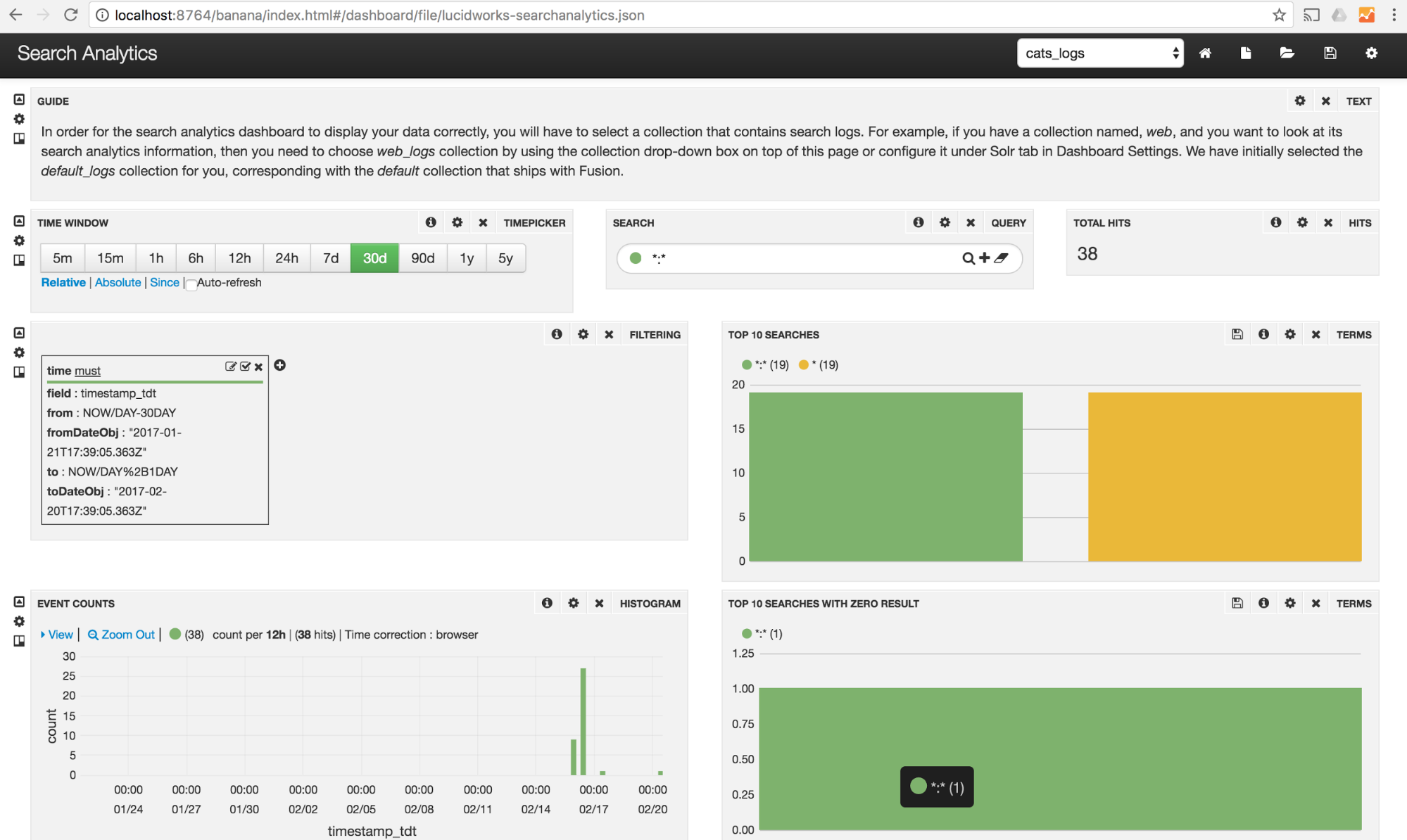
No Data Introspection

Any idiot can put out a search app that shows some of the data. Years ago I put a simple (now defunct) free software tool called htDig in front of a bunch of Word documents. I read them by running the unix “strings” commands against them. It was a simple enough keyword search for a very small corpus so long as you weren’t looking for something too specific and it did nothing for some of the more complicated documents because it couldn’t REALLY see inside them. Oddly this was part of a motivation for creating a project that eventually became Apache POI. POI (via Apache Tika) eventually became the way Fusion read Office documents. htDig sorta worked but it couldn’t “really” look into my Word documents let alone any other file types.
If your search tool can’t “really” see all the way inside your documents it can’t really index them properly. It took years to develop the tools that could really do this. A good search solution is extensible – there is always a new file format or data source – and ideally uses well thought out, proven open source technologies.
Nothing Personal(alized)
 Back in the day you had to learn to construct a search for Google. Now Google kinda knows enough about your past behavior, social networks, and geography to predict what you’re actually looking for. This personalization of search is no longer a luxury but essential to satisfy modern users.
Back in the day you had to learn to construct a search for Google. Now Google kinda knows enough about your past behavior, social networks, and geography to predict what you’re actually looking for. This personalization of search is no longer a luxury but essential to satisfy modern users.
Your search solution needs to track signals like clickstreams and which queries the user entered in the past. Your search solution should allow you to inform future queries with actual purchases or how long a user stayed on a page.
Like No Other

The “more like this” feature on Google isn’t all that useful. It usually obscures results Google hid from you because they were mostly repetitive. That’s an area Google got wrong. It is frequently helpful to find something and explore its kin in order to find just the thing you want. In retail this looks like similar items (another shoe in a different style). In enterprise search these are similar documents (maybe a form from a different year or tax type or similar blueprint).
A good search solution lets you find “more like this” based on keywords but also allows you to automatically cluster or classify like items. Users should be able to navigate their way to their perfect result. They shouldn’t have to get there the first time.

The Tricks That Make Fusion a Treat

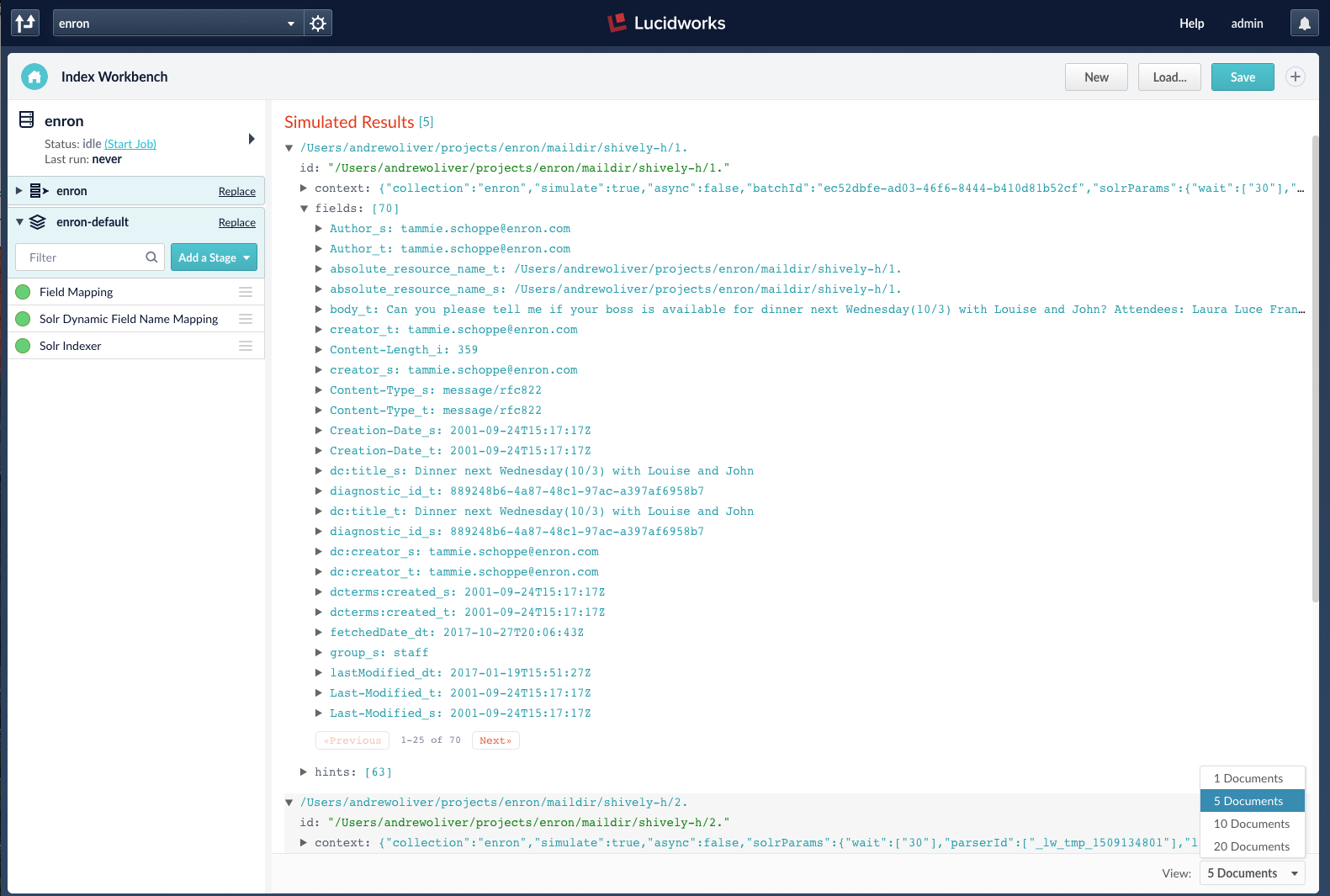
Fusion is built on Apache Solr, Apache Tika, Apache Spark and a whole lot of other open source tools that have been in the works for decades. A lot of R&D and thought went into them and made them into a complete information management solution for finding your stuff! Lucidworks wove these separate pieces into a total solution and added more functionality like machine learning that mere mortals can implement and an Index Workbench that allows you to tune your data ingestion and see the results in real-time.
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.