ML Model Training and Prediction Using Lucidworks Fusion
In this post, I show you how to train a machine learning model and use it for generating predictions on documents in Fusion 3.1. To keep things simple, I chose to use the “hello world” of machine learning: 20-newsgroups. This allows us to focus on the process of training a model into Fusion without getting lost in the details.
Another blog post published by Jake Mannix goes into more depth about the new machine learning capabilities in Fusion (https://lucidworks.com/2017/06/12/machine-learning-in-lucidworks-fusion/)
Getting Started
If you haven’t done so already, please download and install Fusion 3.1 from: lucidworks.com/download
For this blog, we’ll use $FUSION_HOME to represent the directory where you installed Fusion, such as: /opt/fusion/3.1.2.
Start Fusion if it is not running:
cd $FUSION_HOME bin/fusion start
Login to the Fusion Admin UI at: http://localhost:8764/
Next, you should clone the fusion-spark-bootcamp project from Github. Open a command-line terminal and clone the Github project by doing:
git clone https://github.com/lucidworks/fusion-spark-bootcamp.git
Tip: If you’re not a git user, no problem you can download the project zip file from fusion-spark-bootcamp/master.zip.
cd fusion-spark-bootcamp
Edit the myenv.sh script to set the variables for your environment.
cd labs/ml20news ./setup_ml20news.sh
This lab will
- Download the 20-newsgroup dataset
- Index documents using a Fusion index pipeline
- Define a Spark job for training the model
- Run the Spark job.
- Define an index pipeline with the ML stage for trained model
- Test the index pipeline by indexing test documents
After the setup_ml20news.sh script runs, you will have a Logistic Regression model trained and ready to use in Index pipelines. To see the model in action, send the following request:
curl -u admin:password123 -X POST -H "Content-type:application/json" --data-binary @<(cat <<EOF
[
{
"id":"999",
"ts": "2016-02-24T00:10:01Z",
"body_t": "this is a doc about windscreens and face shields for cycles"
}
]
EOF
) "http://localhost:8764/api/apollo/index-pipelines/ml20news-default/collections/ml20news/index?echo=true"
If you see the following output, then you know the classifier is working as expected.
{
"docs" : [ {
"id" : "2706265e-d2ed-411e-ae06-ad3221d3561d",
"fields" : [
"annotations" : [ ]
}, {
"name" : "the_newsgroup_s",
"value" : "rec.motorcycles",
"metadata" : { },
"annotations" : [ ]
}, {
Now let’s look under the hood to understand how to train and deploy the trained model
Training the Classifier Model
Before we can generate classification predictions during indexing, we need to train a classifier model using our training data. The setup_ml20news.sh script already indexed the 20 newsgroup data from http://qwone.com/~jason/20Newsgroups/
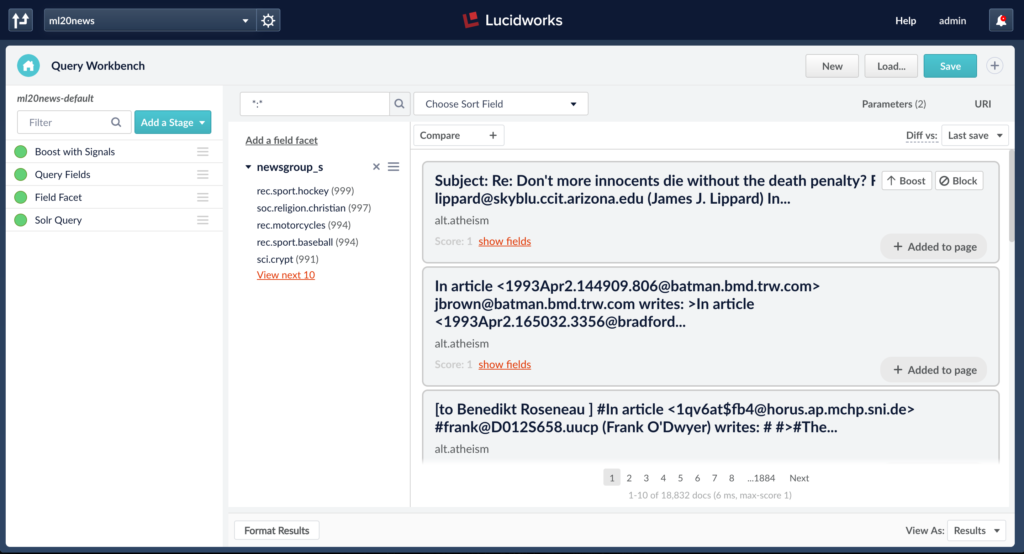
Each indexed document contains fields ‘content_txt’, ‘newsgroup_s’ in which ‘content_txt’ is used for feature extraction and ‘newsgroup_s’ is used as labels for ML training.
Next, we will look at the Spark job that trains on the indexed data and creates a model.
The screenshot below shows the UI for the Spark job that is created by the script. The job defines ‘content_txt’ as the field to vectorize and ‘newsgroup_s’ as the label field to use. The job also defines a model id which will be used to store the trained model in the blob store. The default name of the model is the job id. This can be configured via the job UI.
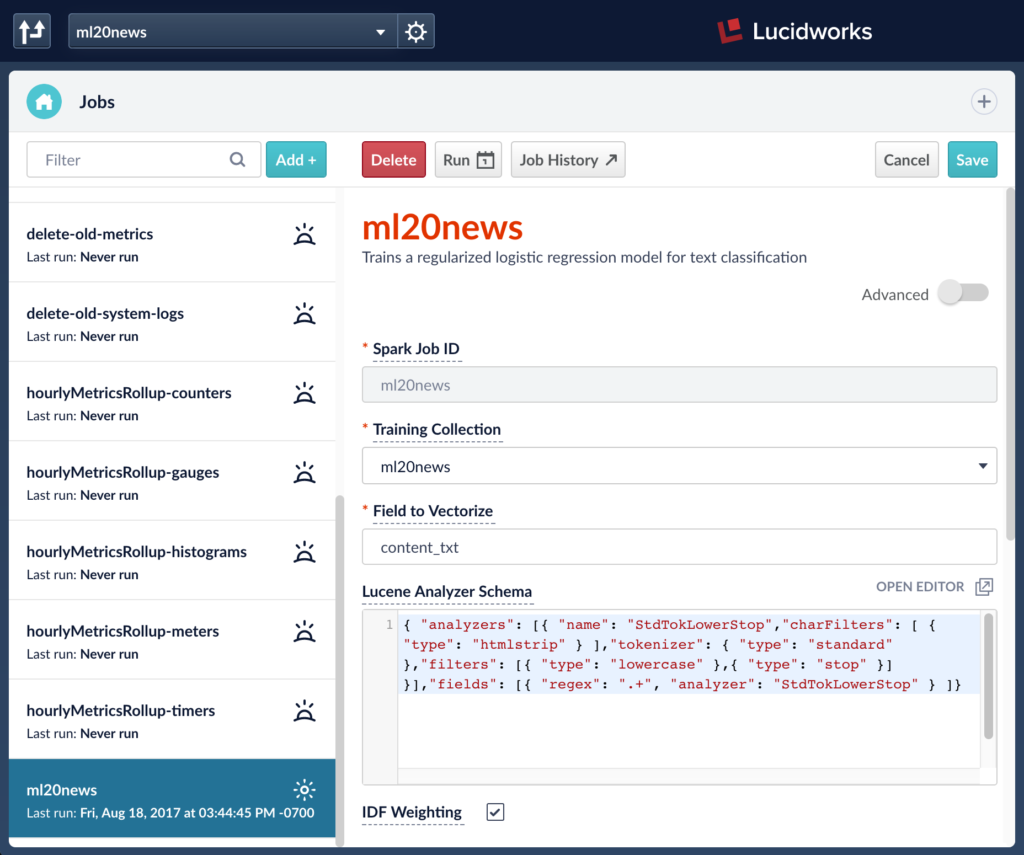
The ML jobs use Lucene’s text analysis classes for extracting features from the text field. For a detailed introduction to the Lucene Text Analyzer for Spark, please read Steve Rowe’s blog: https://lucidworks.com/2016/04/13/spark-solr-lucenetextanalyzer/
Running a Fusion ML job runs a Spark job behind the scenes and saves the output model into Fusion blob store. The saved output model can be used later at query or index time. Fusion ML job output shows counters for the number of labels it trained on.
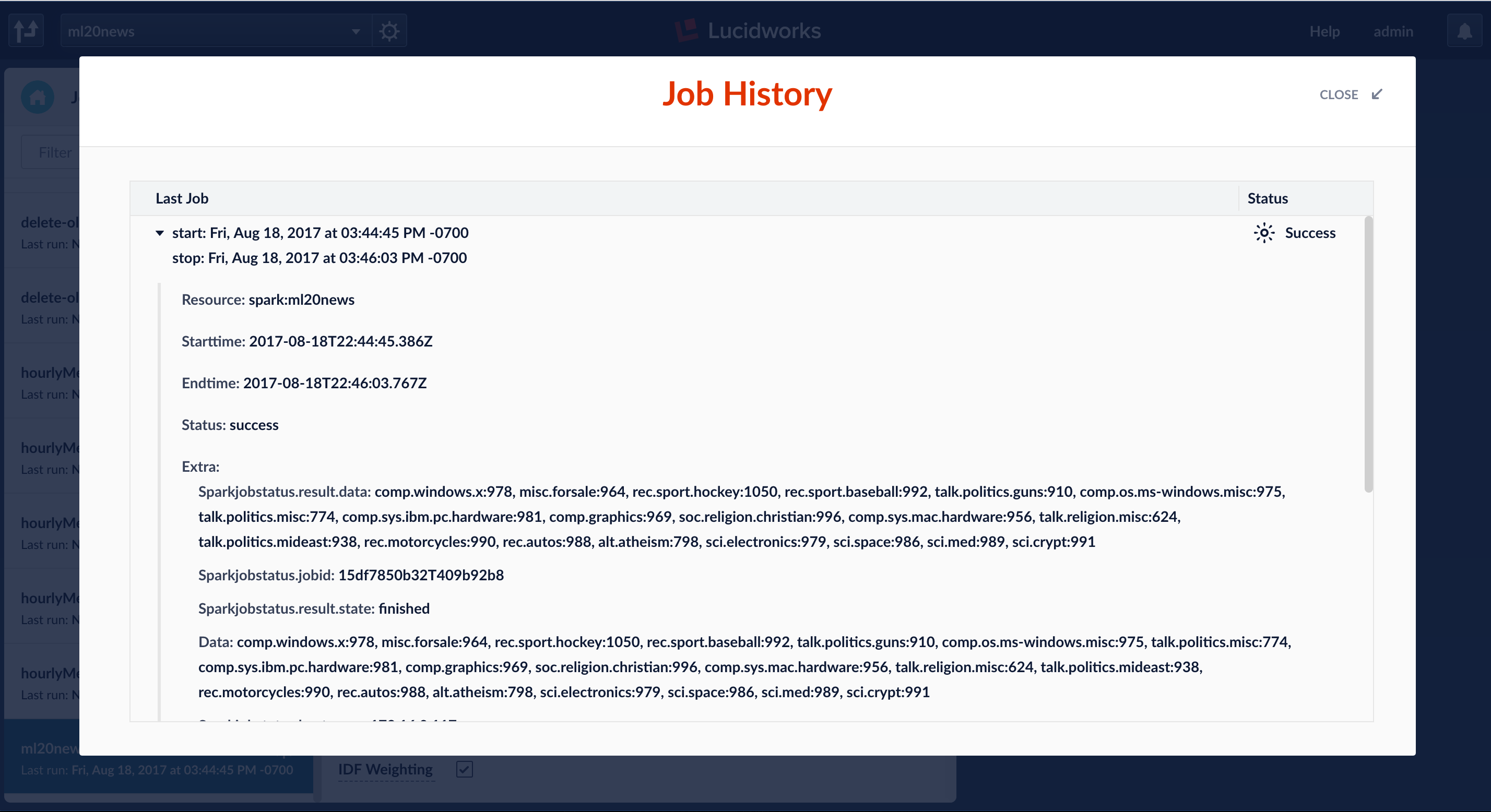
When the job is finished, the ML model is accessible from the Fusion blob store.
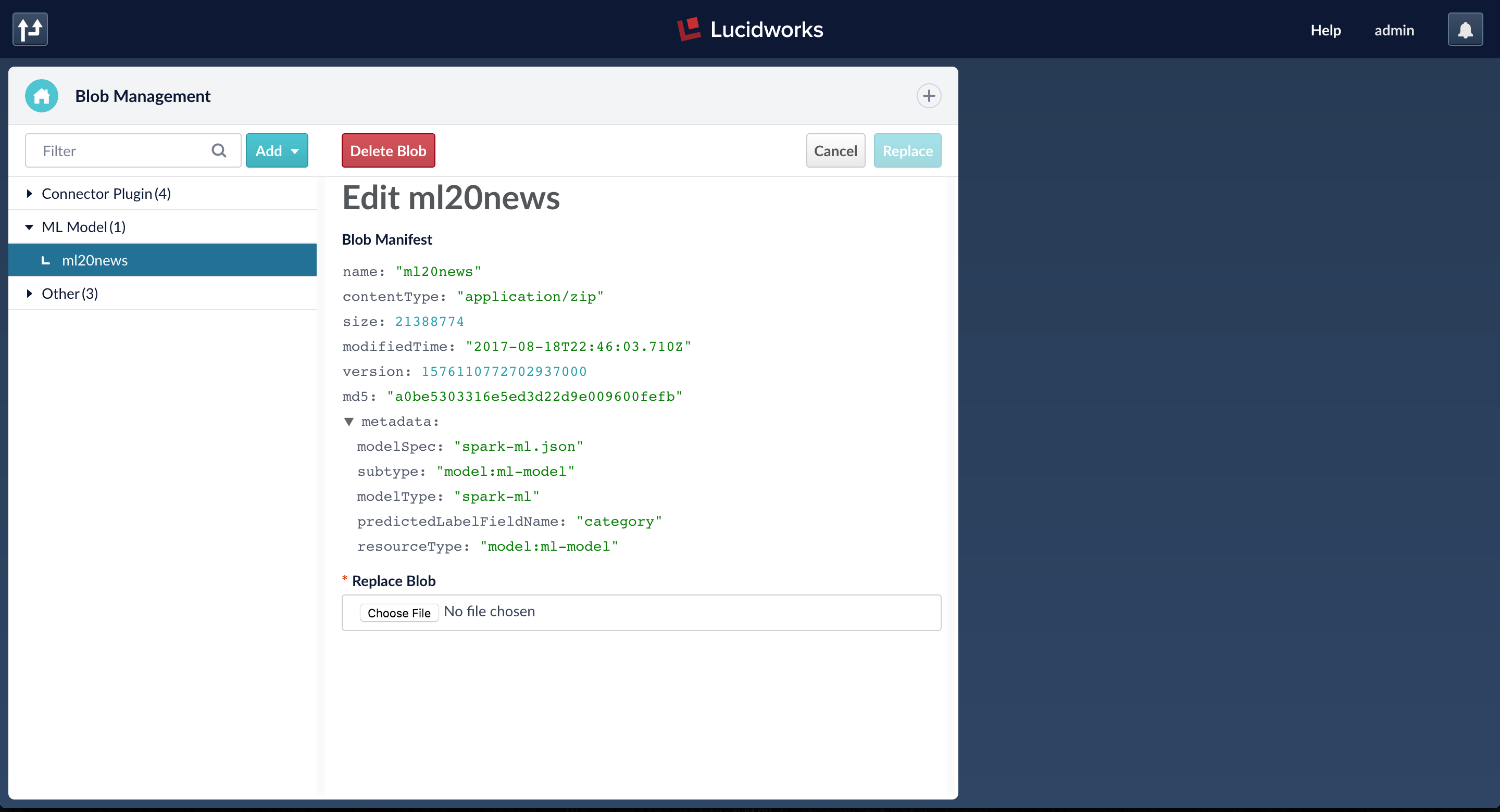
Generating Predictions Using a Trained Model
After the model is trained through a Spark job, it can be used in both query and index pipelines. In this example, I will show how to use it in an index pipeline to generate predictions on documents before they are indexed.
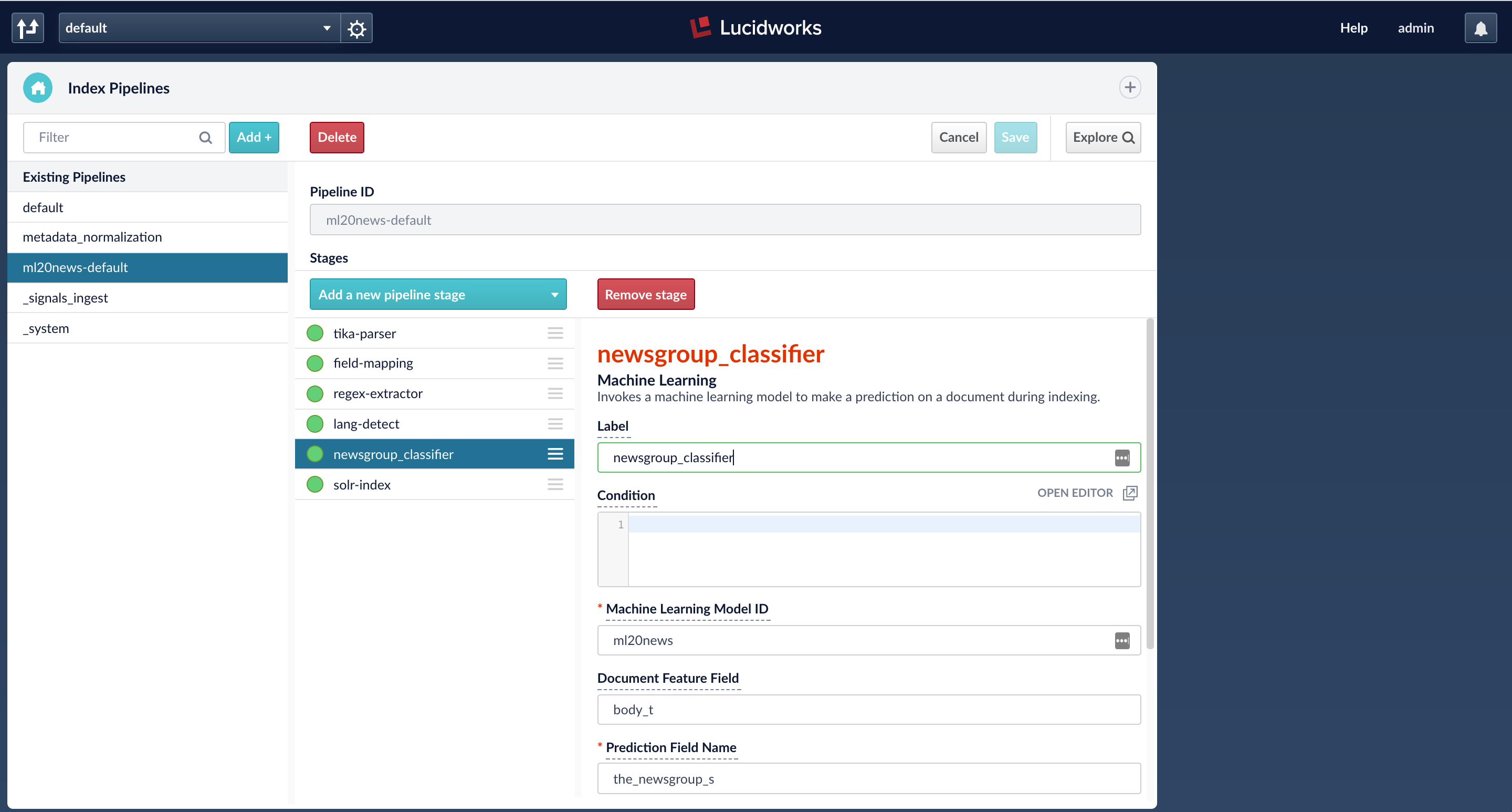
The index pipeline is configured with an ML stage that is configured to take input field ‘body_t’ and output the prediction into a new field ‘the_newsgroup_s’. The model id in the stage should be the trained model name. (By default, this is the name of the Spark job that trained the model)
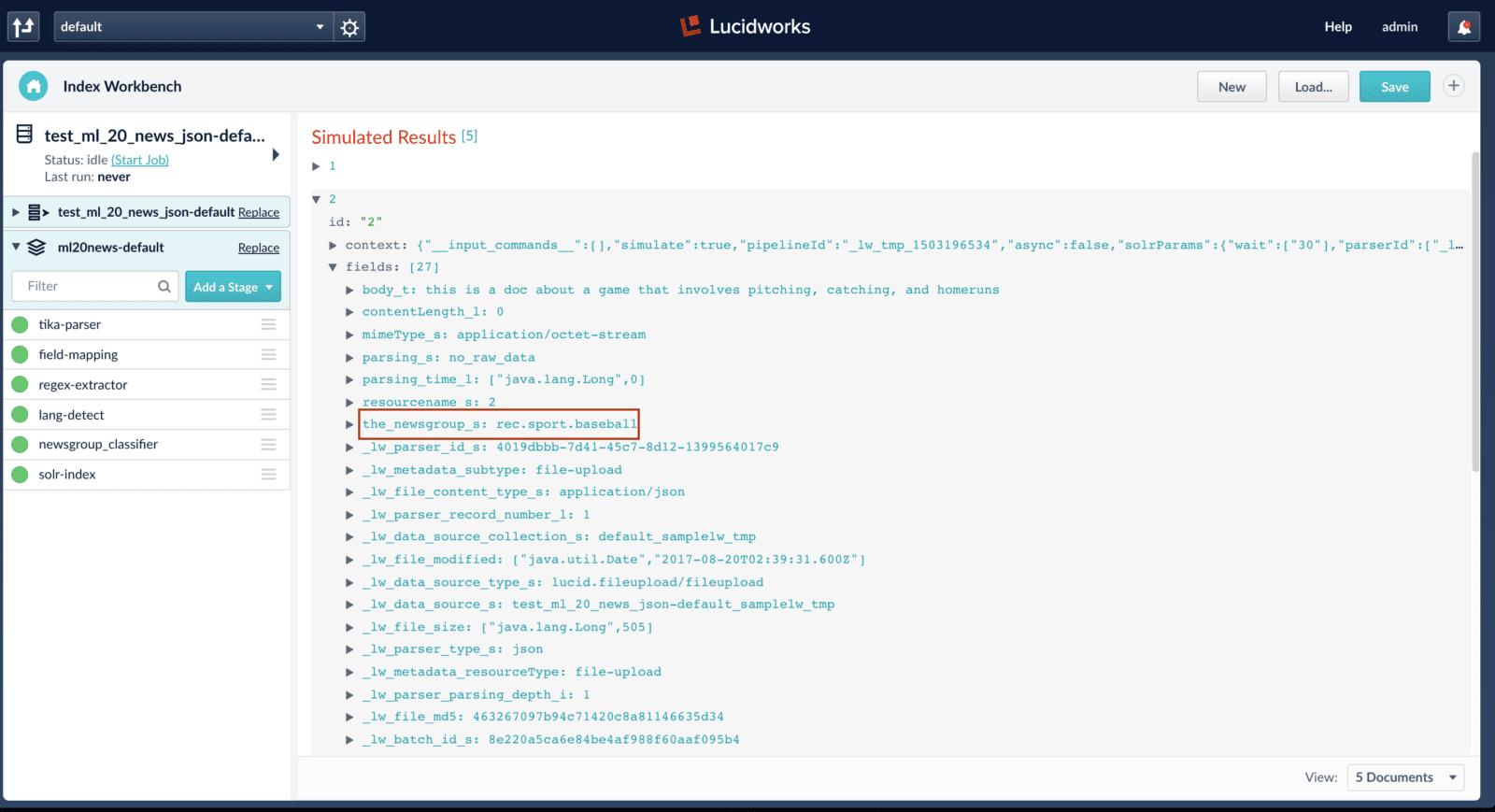
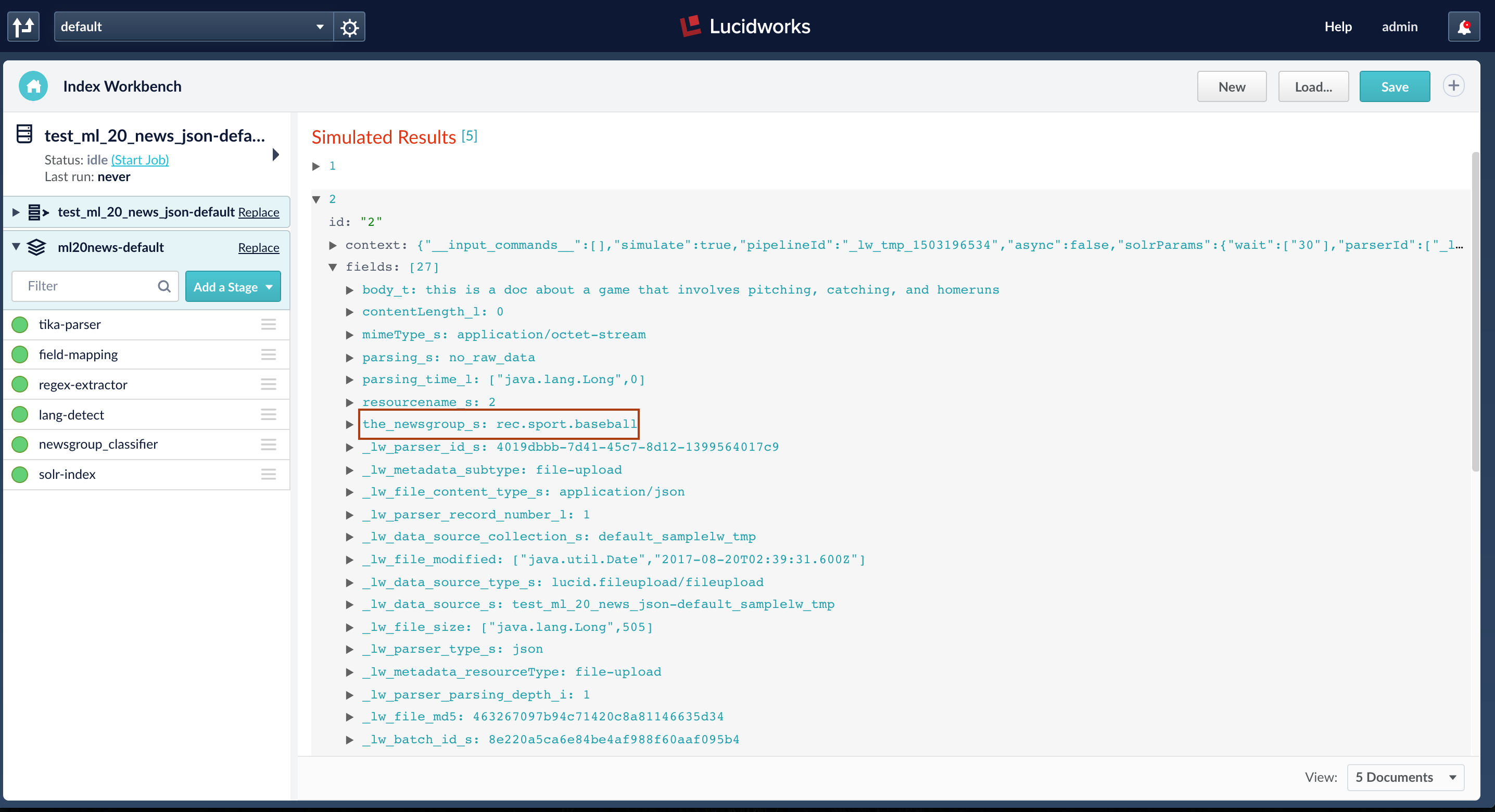
Fusion connectors can be used to index data from over 40 data sources and if these datasources are configured to use the index pipeline with the ML stage, then the predictions will be generated on all the documents that are indexed. The example below shows the use of index workbench to index documents and generate predictions. Here, I am trying to index a JSON file with 5 test documents and after the job finishes, the field ‘the_newsgroup_s’ is added to all the 5 documents.
To learn more about ML jobs in Fusion, see https://lucidworks.com/2017/06/12/machine-learning-in-lucidworks-fusion/
[1], [2] discuss in detail about the experimental Spark jobs available in Fusion 3.1 for clustering and query exploration.
[1] – https://lucidworks.com/2017/06/21/automatic-document-clustering-with-fusion/
[2] – https://lucidworks.com/2017/06/21/query-explorer-jobs-in-fusion-3-1/
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.