Using Solr’s REST APIs to Manage Stop Words and Synonyms

In this post, I introduce a recently added feature for performing Create-Read-Update-Delete (CRUD) operations on Solr resources using a REST API. Before I delve into the details, let’s first understand what I mean by “resource” and why you might want to perform CRUD operations on it.
At its most basic level, a resource in Solr is any object that has editable configuration settings and data that supports a Solr component at runtime. For example, the set of stop words used by a StopFilter during text analysis is a resource, in that it has editable data and configuration settings. Another example, as we’ll see below, is a set of synonym mappings used by a SynonymFilter during text analysis.
I use the term “managed” to indicate a resource in Solr that exposes a RESTful endpoint to allow CRUD style operations to be performed on it. Of course this raises the question as to why one might want to manage resources used by Solr using a REST API? For starters, being able to programmatically change Solr configuration settings simplifies Solr setup, as well as ongoing administration. Moreover, many other “tunable” components in Solr are moving away from manual editing towards being programmatically manageable. For instance, you can use the RESTful schema API to add fields to a managed schema. In general, the features described in this post fit within the current trend towards opening up more of Solr’s internal components to being programmatically managed using RESTful APIs.
Consider a Web-based UI that offers Solr-as-a-Service where users need to configure a set of stop words and synonym mappings as part of an initial setup process for their search application. For this use case, it would be great if Solr exposed simple REST-style interface to list, add, and remove stop words. This would be preferred to the service requiring their users to upload text files to the Solr server.
This post is broken in to two parts: in part 1, I cover the high-level details of how to use this feature to manage stop words and synonyms using a REST API. In part 2, I dig into the nuts and bolts of the implementation. You can safely skip the implementation details in part 2 if you’re only interested in how to use this feature in your application.
Part 1: Feature Overview
As I described in the introduction, you can use this feature to perform CRUD operations on stop words using a REST API. For this section, I’ll use cURL to make the specific API calls, but you’re free to use any HTTP-based client tool.
NOTE: At the time of this writing, these features are only available in Solr trunk.
Stop words
To begin, you need to define a field type that uses the ManagedStopFilterFactory, such as:
<fieldType name="managed_en" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ManagedStopFilterFactory"
managed="english" />
</analyzer>
</fieldType>
There are two important things to notice about this field type definition. First, the filter implementation class is solr.ManagedStopFilterFactory, which resolves to org.apache.solr.rest.schema.analysis.ManagedStopFilterFactory at runtime. This is a special implementation of the StopFilterFactory that uses a set of stop words that are managed from a REST API. Second, the managed=”english” attribute gives a name to the set of managed stop words, in this case indicating the stop words are for English text.
Tip: In the near future, you’ll be able to define field types using a REST API (SOLR-4898), but for now, you must define them manually in the schema.xml.
The REST endpoint for managing the English stop words will be:
/solr/<collection|core>/schema/analysis/stopwords/english
That resource path should be mostly self-explanatory. It should be noted that the ManagedStopFilterFactory implementation determines the /schema/analysis/stopwords part of the path, which makes sense because this is an analysis component defined by the schema. It follows that a field type that uses the following filter:
<filter class=”solr.ManagedStopFilterFactory”
managed=”french” />
would resolve to path:
/solr/<collection|core>/schema/analysis/stopwords/french
So now let’s see this API in action, starting with a simple GET request:
curl "http://localhost:8983/solr/collection1/schema/analysis/ stopwords/english"
Note: The line break should not be present when executing this command.
Assuming you sent this request to the example server, the response body would be a JSON document:
{
"responseHeader":{
"status":0,
"QTime":1
},
"wordSet":{
"initArgs":{"ignoreCase":true},
"initializedOn":"2014-03-28T20:53:53.058Z",
"managedList":[
"a",
"an",
"and",
"are",
... ]
}
}
The collection1 core in the example server ships with a built-in set of managed stop words, see: example/solr/collection1/conf/_schema_analysis_stopwords_english.json. However, you should only interact with this file using the API and not edit it directly.
One thing that should stand out to you in this response is that it contains a managedList of words as well as initArgs. This is an important concept in this framework—managed resources typically have configuration and data. For stop words, the only configuration parameter is a boolean that determines whether to ignore the case of tokens during stop word filtering (ignoreCase=true|false).
Now, let’s add a new word to the English stop word list using an HTTP PUT:
curl -X PUT -H 'Content-type:application/json' --data-binary '["foo"]' "http://localhost:8983/solr/collection1/schema/analysis/stopwords/ english"
Here we’re using cURL to PUT a JSON list containing a single word “foo” to the managed English stop words set. Solr will return 200 if the request was successful.
You can test to see if a specific word exists by sending a GET request for that word as a child resource of the set, such as:
curl "http://localhost:8983/solr/collection1/schema/analysis/ stopwords/english/foo"
This will return a status code of 200 if the child resource (foo) exists or 404 if it does not exist the managed list.
To delete a stop word, you would do:
curl -X DELETE "http://localhost:8983/solr/collection1/schema/ analysis/stopwords/english/foo"
Overall, it should be clear at this point that working with the API itself is very simple. What might not be clear is how changes made with the API affect Solr behavior? Early in the design process, we decided that changes would not be applied to the active Solr components until the Solr core in single server mode or collection in cloud mode is reloaded. In other words, after adding or deleting a stop word, you must reload the core/collection before changes become active. This approach is required when running in distributed mode so that we are assured changes are applied to all cores in a collection at the same time so that behavior is consistent and predictable. It goes without saying that you don’t want one of your replicas working with a different set of stop words than the others.
One subtle outcome of this apply-changes-at-reload approach is that the once you make changes with the API, there is no way to read the active data. In other words, the API returns the most up-to-date data from an API perspective, which could be different than what is currently being used by Solr components. However, the intent of this API implementation is that changes will be applied using a reload within a short time frame after making them so the time in which the data returned by the API differs from what is active in the server is intended to be negligible.
Before we move on to synonyms, I want to discuss the design decision to use PUT/POST to add terms to an existing list instead of replacing the list entirely. This choice was made because it is more common to add a term to an existing list than it is to replace a list altogether. One could argue that the API could just place the burden on the client application to get all terms, make the appropriate set operations (additions/deletions), and then PUT back a full replacement set of words. Either approach is valid, but I chose to favor the more common approach of incrementally adding terms especially since deleting individual terms is also supported.
Synonyms
For the most part, the API for managing synonyms behaves similar to the API for stop words, except instead of working with a list of words, we need to work with a map, where the value for each entry in the map is a set of synonyms for a term. As with stop words, the example server ships with a minimal set of English synonym mappings that is activated by the following field type definition in schema.xml:
<fieldType name="managed_en" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ManagedStopFilterFactory"
managed="english" />
<filter class="solr.ManagedSynonymFilterFactory"
managed="english" />
</analyzer>
</fieldType>
To get the map of managed English synonyms, send a GET request to:
curl "http://localhost:8983/solr/collection1/schema/analysis/ synonyms/english"
This will return a response that looks like:
{
"responseHeader":{
"status":0,
"QTime":4},
"synonymMappings":{
"initArgs":{
"ignoreCase":true,
"format":"solr"},
"initializedOn":"2014-03-31T15:46:48.77Z",
"managedMap":{
"gb":["gib","gigabyte"],
"happy":["glad","joyful"],
"tv":["television"]
}
}
}
Managed synonyms are returned under the managedMap property which contains a JSON Map where the value of each entry is a set of synonyms for a term, such as happy has synonyms glad and joyful in the example above.
To add a new synonym mapping, you can PUT/POST a single mapping such as:
curl -X PUT -H 'Content-type:application/json'
--data-binary '{"mad":["angry","upset"]}'
"http://localhost:8983/solr/collection1/schema/analysis/
synonyms/english"
To determine the synonyms for a specific term, you send a GET request for the child resource, such as /schema/analysis/synonyms/english/mad would return [“angry”,”upset”]. Lastly, you can delete a mapping by sending a DELETE request to the managed endpoint. Now that you’ve seen two specific managed resources in action, let’s move on to learning about the RestManager, which is responsible for managing resources behind the scenes.
RestManager Endpoint
Lastly, before I turn to covering some of the nuts and bolts of the implementation, you can get metadata about registered ManagedResources using the /schema/managed or /config/managed endpoints. Assuming you have the managed_en field type shown above defined in your schema.xml, sending a GET request to the following resource will return metadata about which schema-related resources are being managed by the RestManager:
curl "http://localhost:8983/solr/collection1/schema/managed"
The response body is a JSON document containing metadata about managed resources under the /schema root:
{
"responseHeader":{
"status":0,
"QTime":3},
"managedResources":[
{
"resourceId":"/schema/analysis/stopwords/english",
"class":
"org.apache.solr.rest.schema.analysis.ManagedWordSetResource",
"numObservers":"1"
},
{
"resourceId":"/schema/analysis/synonyms/english",
"class":"org.apache.solr.rest.schema.analysis.
ManagedSynonymFilterFactory$SynonymManager",
"numObservers":"1"
}
]
}
I’ll leave it as an exercise for the reader to see what is returned for the /config endpoint.
As you might have guessed, you can also create new managed resource endpoints. For instance, let’s imagine we want to build up a set of German stop words. Before we can start adding stop words, we need to create the endpoint:
/solr/collection1/schema/analysis/stopwords/german
To create this endpoint, send the following PUT/POST request to the endpoint we wish to create:
curl -X PUT -H 'Content-type:application/json' --data-binary
'{"class":
"org.apache.solr.rest.schema.analysis.ManagedWordSetResource"}'
"http://localhost:8983/solr/collection1/schema/analysis/
stopwords/german"
Solr will respond with status code 200 if the request is successful. Effectively, this action registers a new endpoint for a managed resource in the RestManager. From here you can start adding German stop words as we saw above:
curl -X PUT -H 'Content-type:application/json' --data-binary '["die"]' "http://localhost:8983/solr/collection1/schema/analysis/ stopwords/german"
You can also delete managed resources unless they are being used by a Solr component. For instance, the managed resource for German that we created above can be deleted because there are no Solr components that are using it, whereas the managed resource for English stop words cannot be deleted because there is a token filter declared in schema.xml that is using it. You’ll have to wait for SOLR-4898 before adding managed resources programmatically can be fully utilized.
You should be aware that changing things like stop words and synonym mappings typically require re-indexing existing documents if being used by index-time analyzers. The RestManager framework does not guard you from this, it simply makes it possible to programmatically build up a set of stop words, synonyms etc.
So now that you’ve seen the REST API in action, let’s dig into the implementation details.
Part 2: Nuts and Bolts
In this section, I give you some pointers into design and implementation decisions we made while developing this feature. For more details beyond what is covered here, I encourage you to review the code in Solr trunk and JIRA tickets: SOLR-5653, -5654, -5655. Let’s begin with a quick discussion of how REST works in Solr.
Restlet
Restlet is an open-source Java framework for implementing RESTful endpoints in a Java Web application. Solr uses Restlet to route HTTP requests to specific resources identified in a request. There are many good resources on the Web that cover the principles of REST so I’ll skip the theory in this blog and focus on the implementation details. The following diagram depicts how Restlet works in Solr:
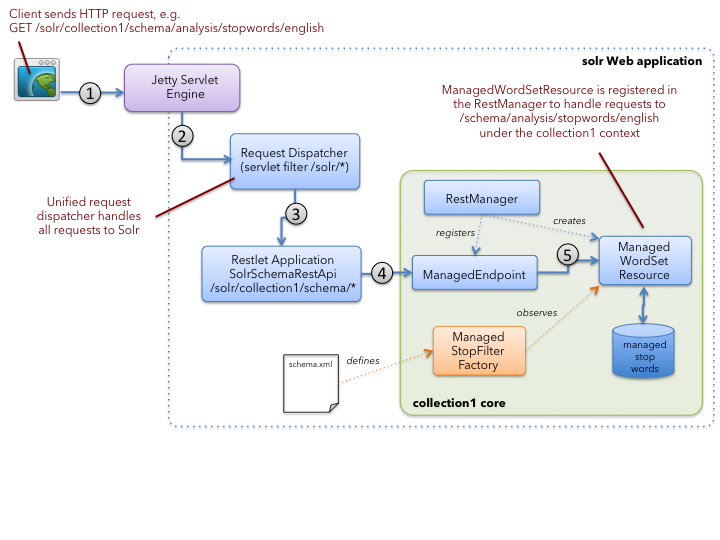
Let’s walk through the steps in this diagram, as they will help you see how Restlet based routing works in Solr. At the top left (1), a client application issues a GET request for resource at path: /solr/collection1/schema/analysis/stopwords/english. Of course this gets handled by Jetty and routed to the SolrDispatchFilter based on the /solr context in the request (2). The SolrDispatchFilter determines the collection/core based on the request, in this case collection1. After resolving the correct core, the filter routes requests to /schema to the Restlet Application instance (3). The Restlet Application is configured in web.xml.
The Restlet Application routes the request to a ManagedEndpoint in the collection1 core (4). The ManagedEndpoint gets setup by the RestManager during core initialization, which I’ll discuss in more detail below. Lastly, the ManagedEndpoint delegates the handling of the GET request to a ManagedResource, which in this case is a ManagedWordSetResource (5).
Although not depicted in the diagram, there is also a Restlet Application registered to respond to requests for /config resources, which is useful for managed resources that support Solr components defined in solrconfig.xml. I’ll only be covering /schema based resources in this blog.
Steps 4-6 in the diagram are the main focus of this blog post. Let’s start with learning how ManagedEndpoints and their related ManagedResources are registered with the Restlet application by a core component called the RestManager.
RestManager
RestManager is a core component of this framework. Its main responsibility is to create and manage a set of ManagedResource instances, which includes registering the endpoint for each resource in the appropriate Restlet Application, either /schema or /config. There is one RestManager per Solr core.
RestManager can be configured in solrconfig.xml. For instance, the following XML declaration in solrconfig.xml would define a RestManager that uses in-memory storage (don’t worry about the actual details now as I’ll cover RestManager storage below).
<restManager> <str name="storageIO">org.apache.solr.rest. ManagedResourceStorage$InMemoryStorageIO</str> </restManager>
Tip: The InMemoryStorageIO implementation shown in the XML above should only be used for unit testing as data is only stored in memory.
If there is not a <restManager> element defined in solrconfig.xml, then the default RestManager is configured automatically. The default RestManager uses the file system or ZooKeeper for data persistence depending on whether Solr is running in single server or cloud mode.
When parsing solrconfig.xml and schema.xml during core initialization, Solr may encounter components that depend on managed resources. For example, consider the managed_en field type definition from section 1 above:
<fieldType name="managed_en" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.ManagedStopFilterFactory"
managed="english" />
</analyzer>
</fieldType>
This field type defines a ManagedStopFilterFactory, which depends on a ManagedWordSetResource. The “managed” attribute is required to give a unique handle to the underlying ManagedResource, in this case “english”.
When Solr creates this field type, it creates an instance of ManagedStopFilterFactory, which in turn registers itself as an observer of a ManagedWordSetResource, see BaseManagedTokenFilterFactory#inform method.
The observer registry approach is necessary to de-couple the registration of observers of ManagedResources from the initialization of the RestManager and managed resources. In other words, to avoid timing issues during core initialization / config file parsing, components that depend on ManagedResources simply register themselves as observers and then receive a callback after the managed resource is fully initialized. Observers only receive the callback once during core initialization, which is how we ensure that changes made by the API are only applied during core initialization.
Also, it’s important to notice that there can be many Solr components that depend on the same ManagedResource. For example, you may have many field type definitions that use the same set of English stop words. Behind the scenes, all ManagedStopFilterFactory instances that use the same managed=”english” attribute should use the same set of managed words. This is a perfect application of the observer pattern.
At this point, it should be clear that Solr components register as observers of managed resources and the RestManager is responsible for initializing managed resources. Now let’s see how requests get routed to correct managed resource using a ManagedEndpoint.
ManagedEndpoint
One of the key principles in object-oriented design is separation of concerns. The main “concern” of a managed resource is properly supporting CRUD operations on some data and/or configuration settings. What it should not be concerned with is REST-style request routing, response formatting, or endpoint registration in Restlet. Another way to look at this is that a developer should be able to implement a managed resource without having to become a REST expert or even learn how Restlet works. The ManagedEndpoint class helps facilitate separation of concerns by abstracting most of the details of being RESTful from managed resources.
In the diagram above, the RestManager registers the ManagedEndpoint class with Restlet for each endpoint being managed. During request handling, the Restlet framework creates a new ManagedEndpoint for every request. On the other hand, managed resources are typically long-lived, heavyweight objects that use resources to load and store data. Thus, ManagedEndpoint instances must lookup the correct managed resource at runtime using information in the request path. If the ManagedEndpoint doesn’t find a resource for the requested path, it delegates the request to the RestManager. As we saw in section 1, a POST to a non-existing path creates a new managed resource at that path. A GET request to a non-existing path leads to a 404 error.
The ManagedEndpoint class also takes care of JSON request parsing, response formatting, and error handling in a RESTful way.
Data Storage
Managed resources typically need to load/store data from/to a persistent location, such as the local file system or ZooKeeper if running in SolrCloud mode. Keeping with our separation of concerns design philosophy, ManagedResource developers need not worry about how storage I/O works behind the scenes. In other words, developers need not be concerned with whether their data is being stored in ZooKeeper or in a local text file. The ManagedResourceStorage class provides the necessary data storage abstractions for managed resources.
Although the I/O aspects of storage can safely be abstracted from managed resources, the storage format is another story. By default, the framework uses JSON as the storage format. However, a ManagedResource developer can choose to use a different format, such as good old Java Serialization if JSON doesn’t work for their needs. Storage format and storage I/O are separate concerns so one can choose a custom storage format and still use the framework to persist data to ZooKeeper in SolrCloud. A good example of using a different storage format is available in the TestManagedResource unit test class.
Wrap-Up
In this post, I introduced you to a new framework in Solr for building resources that you can manage using a REST API and two concrete implementations of that framework for managing stop words and synonyms. I encourage you to try these features out in Solr trunk. Of course, as with any new feature set, there may be improvements/issues that were overlooked during the initial development phase, so please don’t hesitate to provide feedback on the Solr user mailing list or in JIRA.
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.