Creating a spellchecker with Solr
Introduction
In a previous post I talked about how the Solr Spellchecker works and then I showed you some test results of its performance. Now we are going to see another aproach to spellchecking.
This method, as many others, use a two step procedure. A rather fast “candidate word” selection, and then a scoring of those words. We are going to select different methods from the ones that Solr uses and test its performance. Our main objective will be effectiveness in the correction, and in a second term, velocity in the results. We can tolerate a slightly slower performance considering that we are gaining in correctness of the results.
Our strategy will be to use a special Lucene index, and query it using fuzzy queries to get a candidate list. Then we are going to rank the candidates with a Python script (that can easily be transformed in a Solr spell checker subclass if we get better results).
Candidate selection
Fuzzy queries have historically been considered a slow performance query in relation with others but , as they have been optimized in the 1.4 version, they are a good choice for the first part of our algorithm. So, the idea will be very simple: we are going to construct a Lucene index where every document will be a dictionary word. When we have to correct a misspelled word we are going to do a simple fuzzy query of that word and get a list of results. The results will be words similar to the one we provided (ie with a small edit distance). I found that with approximately 70 candidates we can get excellent results.
With fuzzy queries we are covering all the typos because, as I said in the previous post, most of the typos are of edit distance 1 with respect to the correct word. But although this is the most common error people make while typing, there are other kinds of errors.
We can find three types of misspellings [Kukich]:
- Typographic errors
- Cognitive errors
- Phonetic errors
Typographic errors are the typos, when people knows the correct spelling but makes a motor coordination slip when typing. The cognitive errors are those caused by a lack of knowledge of the person. Finally, phonetic errors are a special case of cognitive errors that are words that sound correctly but are orthographically incorrect. We already covered typographic errors with the fuzzy query, but we can also do something for the phonetic errors. Solr has a Phonetic Filter in its analysis package that, among others, has the double methaphone algorithm. In the same way we perform fuzzy query to find similar words, we can index the methaphone equivalent of the word and perform fuzzy query on it. We must manually obtain the methaphone equivalent of the word (because the Lucene query parser don’t analyze fuzzy queries) and construct a fuzzy query with that word.
In few words, for the candidate selection we construct an index with the following solr schema:
<fieldType name="spellcheck_text" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer/>
<filter/>
<filter encoder="DoubleMetaphone" maxCodeLength="20" inject="false"/>
</analyzer>
</fieldType>
<field name=”original_word” type=”string” indexed=”true” stored=”true” multiValued=”false”/>
<field name=”analyzed_word” type=”spellcheck_text” indexed=”true” stored=”true” multiValued=”false”/>
<field name=”freq” type=”tfloat” stored=”true” multiValued=”false”/>
As you can see the analyzed_word field contains the “soundslike” of the word. The freq field will be used in the next phase of the algorithm. It is simply the frequency of the term in the language. How can we estimate the frequency of a word in a language? Counting the frequency of the word in a big text corpus. In this case the source of the terms is the wikipedia and we are using the TermComponents of Solr to count how many times each term appears in the wikipedia.
But the Wikipedia is written by common people that make errors! How can we trust in this as a “correct dictionary”? We make use of the “colective knowledge” of the people that writes the Wikipedia. This dictionary of terms extracted from the Wikipedia has a lot of terms! Over 1.800.00, and most of them aren’t even words. It is likely that words with a high frequency are correctly spelled in the Wikipedia. This approach of building a dictionary from a big corpus of words and considering correct the most frequent ones isn’t new. In [Cucerzan] they use the same concept but using query logs to build the dictionary. It apears that Google’s “Did you mean” use a similar concept.
We can add little optimizations here. I have found that we can remove some words and get good results. For example, I removed words with frequency 1, and words that begin with numbers. We can continue removing words based on other criteria, but we’ll leave this like that.
So the procedure for building the index is simple, we extract all the terms from the wikipedia index via the TermsComponent of Solr along with frequencies, and then create an index in Solr, using SolrJ.
Candidate ranking
Now the ranking of the candidates. For the second phase of the algorithm we are going to make use of information theory, in particular, the noisy channel model. The noisy channel applied to this case assumes that the human knows the correct spelling of a word but some noise in the channel introduces the error and as the result we get another word, misspelled. We intuitively know that it is very unlikely that we get ‘sarasa’ when trying to type ‘house’ so the noisy channel model introduces some formality to finding how probable an error was.
For example, we have misspelled ‘houze’ and we want to know which one is the most likely word that we wanted to type. To accomplish that we have a big dictionary of possible words, but not all of them are equally probable. We want to obtain the word with the highest probability of having been intended to be typed. In mathematics that is called conditional probability; given that we typed ‘houze’ how high is the probability of each of the correct words to be the word that we intended. The notation of conditional probability is: P(‘house’|’houze’) that stands for the probability of ‘house’ given ‘houze’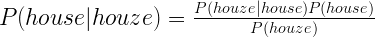
This problem can be seen from two perspectives: we may think that the most common words are more probable, for example ‘house’ is more probable than ‘hose’ because the former is a more common word. In the other hand, we also intuitively think that ‘house’ is more probable than ‘photosinthesis’ because of the big difference in both words. Both of these aspects, are formally deduced by Bayes theorem:
We have to maximize this probability and to do that we only have one parameter: the correct candidate word (‘house’ in the case shown).

For that reason the probability of the misspelled word will be constant and we are not interested in it. The formula reduces to
And to add more structure to this, scientists have given named to these two factors. The P(‘houze’|’house’) factor is the Error model (or Channel Model) and relates with how probable is that the channel introduces this particular misspell when trying to write the second word. The second term P(‘house’) is called the Language model and gives us an idea of how common a word is in a language.
Up to this point, I only introduced the mathematical aspects of the model. Now we have to come up with a concrete model of this two probabilities. For the Language model we can use the frequency of the term in the text corpus. I have found empirically that it works much better to use the logarithm of the frequency rather than the frequency alone. Maybe this is because we want to reduce the weight of the very frequent terms more than the less frequent ones, and the logarithm does just that.
There is not only one way to construct a Channel model. Many different ideas have been proposed. We are going to use a simple one based in the Damerau-Levenshtein distance. But also I found that the fuzzy query of the first phase does a good job in finding the candidates. It gives the correct word in the first place in more than half of the test cases with some datasets. So the Channel model will be a combination of the Damerau-Levenshtein distance and the score that Lucene created for the terms of the fuzzy query.
The ranking formula will be: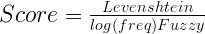
I programmed a small script (python) that does all that was previously said:
from urllib import urlopen
import doubleMethaphone
import levenshtain
import json
server = “http://benchmarks:8983/solr/testSpellMeta/”
def spellWord(word, candidateNum = 70):
#fuzzy + soundlike
metaphone = doubleMethaphone.dm(word)
query = “original_word:%s~ OR analyzed_word:%s~” % (word, metaphone[0])
if metaphone[1] != None:
query = query + ” OR analyzed_word:%s~” % metaphone[1]
doc = urlopen(server + “select?rows=%d&wt=json&fl=*,score&omitHeader=true&q=%s” % (candidateNum, query)).read( )
response = json.loads(doc)
suggestions = response[‘response’][‘docs’]
if len(suggestions) > 0:
#score
scores = [(sug[‘original_word’], scoreWord(sug, word)) for sug in suggestions]
scores.sort(key=lambda candidate: candidate[1])
return scores
else:
return []
def scoreWord(suggestion, misspelled):
distance = float(levenshtain.dameraulevenshtein(suggestion[‘original_word’], misspelled))
if distance == 0:
distance = 1000
fuzzy = suggestion[‘score’]
logFreq = suggestion[‘freq’]
return distance/(fuzzy*logFreq)
From the previous listing I have to make some remarks. In line 2 and 3 we use third party libraries for Levenshtein distance and metaphone algorithms. In line 8 we are collecting a list of 70 candidates. This particular number was found empirically. With higher candidates the algorithm is slower and with fewer is less effective. We are also excluding the misspelled word from the candidates list in line 30. As we used the wikipedia as our source it is common that the misspelled word is found in the dictionary. So if the Leveshtain distance is 0 (same word) we add 1000 to its distance.
Tests
I ran some tests with this algorithm. The first one will be using the dataset that Peter Norvig used in his article. I found the correct suggestion of the word in the first position approximately 80% of the times!!! That’s is a really good result. Norvig with the same dataset (but with a different algoritm and training set) got 67%
Now let’s repeat some of the test of the previous post to see the improvement. In the following table I show you the results.
| Test set | % Solr | % new | Solr time [seconds] | New time [seconds] | Improvement | Time loss |
FAWTHROP1DAT.643 |
45,61% |
81,91% |
31,50 |
74,19 |
79,58% |
135,55% |
batch0.tab |
28,70% |
56,34% |
21,95 |
47,05 |
96,30% |
114,34% |
SHEFFIELDDAT.643 |
60,42% |
86,24% |
19,29 |
35,12 |
42,75% |
82,06% |
We can see that we get very good improvements in effectiveness of the correction but it takes about twice the time.
Future work
How can we improve this spellchecker. Well, studying the candidates list it can be found that the correct word is generally (95% of the times) contained in it. So all our efforts should be aimed to improve the scoring algorithm.
We have many ways of improving the channel model; several papers show that calculating more sophisticated distances weighting the different letter transformations according to language statistics can give us a better measure. For example we know that writing ‘houpe’ y less probable than writing ‘houze’.
For the language model, great improvements can be obtained by adding more context to the word. For example if we misspelled ‘nouse’ it is very difficult to tell that the correct word is ‘house’ or ‘mouse’. But if we add more words “paint my nouse” it is evident that the word that we were looking for was ‘house’ (unless you have strange habits involving rodents). These are also called ngrams (but of words in this case, instead of letters). Google has offered a big collection of ngrams that are available to download, with their frequencies.
Lastly but not least, the performance can be improved by programming the script in java. Part of the algorithm was in python.
Bye!
This blog entry can also be found in my personal blog http://emmaespina.wordpress.com.
As an update for all of you interested, Robert Muir told me in the Solr User list that there is a new spellchecker, DirectSpellChecker, that was in the trunk then and now should be part of Solr 3.1. It uses a similar technique to the one i presented in this entry without the performance loses.
References
[Kukich] Karen Kukich – Techniques for automatically correcting words in text – ACM Computing Surveys – Volume 24 Issue 4, Dec. 1992
[Cucerzan] S. Cucerzan and E. Brill Spelling correction as an iterative process that exploits the collective knowledge of web users. July 2004
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.