Fusion 5.1 Is Here: Faster Deployment of Data Science and Innovation
Fusion 5.1, available now, extends Fusion’s cloud-native, microservices architecture further with tools and features that streamline development, simplify operations and supercharge data science.

We are proud to announce a new series of enhancements to Lucidworks Fusion. Fusion 5.1, available now, extends the platform’s cloud-native, microservices architecture further with tools and features that streamline development, simplify operations and supercharge data science. This release enriches our ability to help customers maximize the value of data discovery and provide personalized experiences to their customers and employees.
Make Data Science Faster
Many organizations have centralized data science teams that work apart from the teams who build search applications. This makes it difficult for search teams to leverage custom machine learning models and for data science teams to understand how their models work in production. As a way to bridge that gap, Fusion 5.1 makes custom models more easily consumed by search applications and the developers who create them and provides a feedback loop for data scientists.
Last year’s Fusion 5.0 release introduced native Python support, enabling seamless deployment of models built in popular data science toolkits like TensorFlow and scikit-learn. Fusion 5.1 builds on that base and includes a Jupyter notebook integration that gives data scientists the freedom to explore and test models.
A new Seldon Core service automates deployment and training of machine learning models into Fusion’s containerized architecture, decoupling data science from application release cycles and increasing the velocity of innovation.
Streamline DevOps
Fusion’s updated metrics and dashboard capabilities are built with open source standards Prometheus and Grafana and give search and DevOps teams fine-grained visibility into system operations. Dashboards for Fusion’s index and query pipelines make it easier to identify and resolve issues. Metrics can be easily exported into external cloud monitoring tools so DevOps teams can remain within their existing workflows.
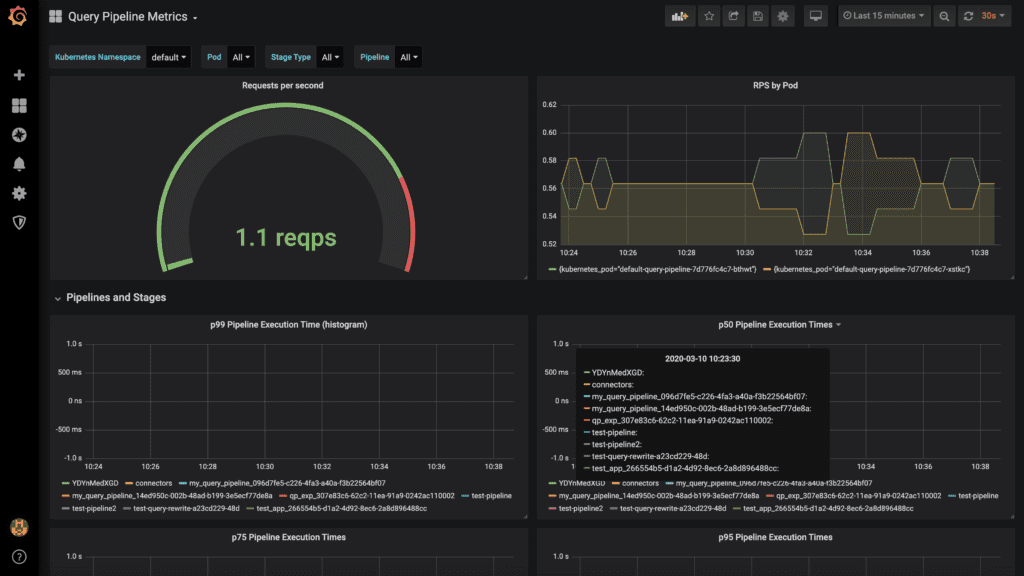
Dashboards for Fusion’s index and query pipelines as well as all Solr metrics make it easier to identify and resolve issues.
Fusion 5.1 can be deployed in the data center, in the cloud, or in a hybrid environment – anywhere that uses Kubernetes for container orchestration. We’ll help get you started quickly in Google Kubernetes Engine (GKE), Azure Kubernetes Service (AKS), Amazon Elastic Kubernetes Service (EKS), and Red Hat OpenShift. And if you don’t want to worry about managing Fusion and Kubernetes on your own, we can host it for you as a cloud service.
Additional Fusion 5.1 Features
- Support for streaming data and geo-location
- Index Stage SDK for custom development of index pipeline stages
- Advanced Linguistics pack for tokenization in more than thirty non-English languages and advanced entity extraction for 19 languages
- Enhancements to Fusion’s Predictive Merchandiser solution
To learn more about what’s new in Fusion 5.1, read the release notes, watch the webinar, and try Fusion today.
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.