Parsing and Indexing Multi-Value Fields in Fusion
Recently, I was helping a client move from a pure Apache Solr implementation to Lucidworks Fusion. Part of this effort entailed the recreation of indexing processes (implemented using Solr’s REST APIs) in the Fusion environment, taking advantage of Indexing Pipelines to decouple the required ETL from Solr and provide reusable components for future processing.
One particular feature that was heavily used in the previous environment was the definition of “field separator” in the REST API calls to the Solr UpdateCSV request handler. For example:
curl "http://localhost:8888/solr/collection1/update/csv/?commit=true&f.street_names.split=true&f.street_names.separator=%0D" --data-binary @input.csv -H 'Content-type:text/plain; charset=utf-8'
The curl command above posts a CSV file to the /update/csv request handler, with the request parameters "f.aliases.split=true" and "f.aliases.separator=%0D" identifying the field in column “aliases” as a multi-value field, with the character “r” separating the values (%0D is a mechanism for escaping the carriage return by providing the hexadecimal ASCII code to represent “r”.) This provided a convenient way to parse and index multi-value fields that had been stored as delimited strings. Further information about this parameter can be found here.
After investigating possible approaches to this in Fusion, it was determined that the most straightforward way to accomplish this (and provide a measure of flexibility and reusability) was to create an index pipeline with a JavaScript stage.
The Index Pipeline
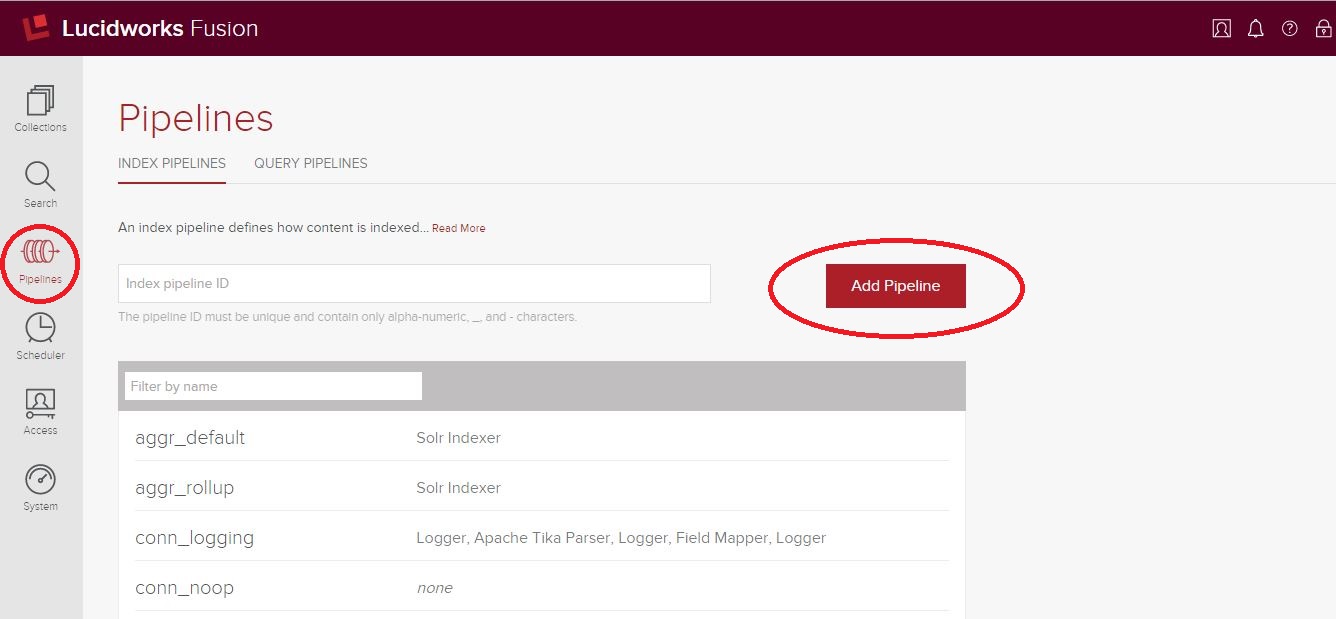
Index pipelines are a framework for plugging together a series of atomic steps, called “stages,” that can dynamically manipulate documents flowing in during indexing. Pipelines can be created through the admin console by clicking “Pipelines” in the left menu, then entering a unique and arbitrary ID and clicking “Add Pipeline” – see below.
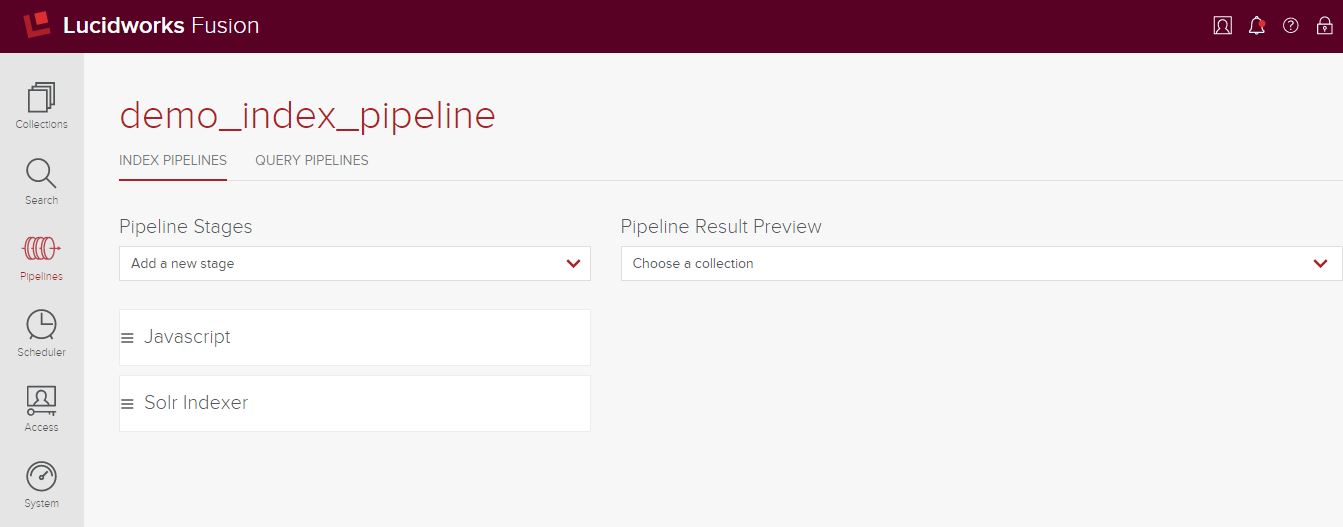
After creating your pipeline, you’ll need to add stages. In our case, we have a fairly simple pipeline with only two stages: a JavaScript stage and a Solr Indexer stage. Each stage has its own context and properties and is executed in the configured order by Fusion. Since this post is about document manipulation, I won’t go into detail regarding the Solr Indexer stage; you can find more information about it here. Below is our pipeline with its two new stages, configured so that the JavaScript stage executes before the Solr Indexer stage.
The JavaScript Index Stage
We chose a JavaScript stage for our approach, which gave us the ability to directly manipulate every document indexed via standard JavaScript – an extremely powerful and convenient approach. The JavaScript stage has four properties:
- “Skip This Stage” – a flag indicating whether this stage should be executed
- “Label” – an optional property that allows you to assign a friendly name to the stage
- “Conditional Script” – JavaScript that executes before any other code and must return true or false. Provides a mechanism for filtering documents processed by this stage; if false is returned, the stage is skipped
- “Script Body” – required; the JavaScript that executes for each document indexed (where the script in “Conditional Script,” if present, returned true)
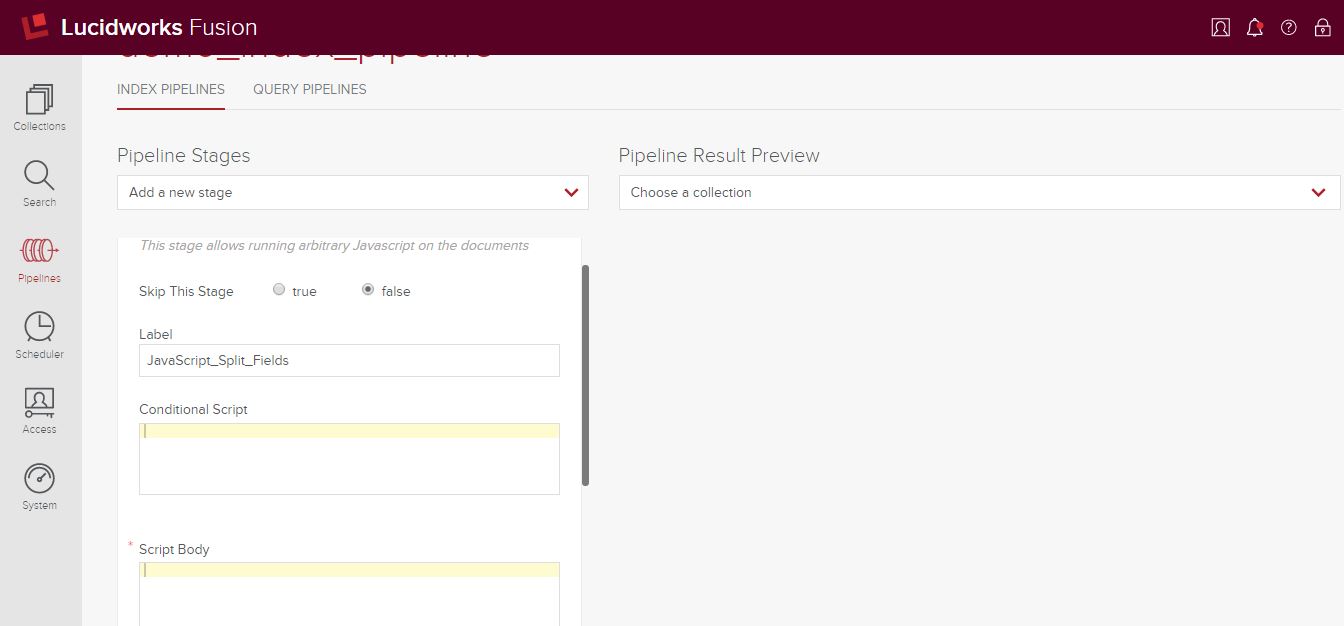
Below, our JavaScript stage with “Skip This Stage” set to false and labeled “JavaScript_Split_Fields.”
Our goal is to split a field (called “aliases”) in each document on a carriage return (CTRL-M). To do this, we’ll define a “Script Body” containing JavaScript that checks each document for the presence of a particular field; if present, splits it and assigns the resulting values to that field.
The function defined in “Script Body” can take one (doc, the pipeline document) or two (doc and _context, the pipeline context maintained by Fusion) arguments. Since this stage is the first to be executed in the pipeline, and there are no custom variables to be passed to the next stage, the function only requires the doc argument. The function will then be obligated to return doc (if the document is to be indexed) or null (if it should not be indexed); in actuality we’ll never return null as the purpose of this stage is to manipulate documents, not determine if they should be indexed.
function (doc) {
return doc;
}
Now that we have a reference to the document, we can check for the field “aliases” and split it accordingly. Once its split, we need to remove the previous value and add the new values to “aliases” (which is defined as a multi-value field in our Solr schema.) Here’s the final code:
function (doc) {
var f_aliases = doc.getFirstField("aliases");
if (f_aliases != null) {
var v_aliases = f_aliases.value;
} else {
var v_aliases = null;
}
if (v_aliases != null) {
doc.removeFields("aliases");
aliases = v_aliases.split("r");
for (var i = 0; i < aliases.length; i++) {
doc.addField('aliases',aliases[i]);
}
}
return doc;
}
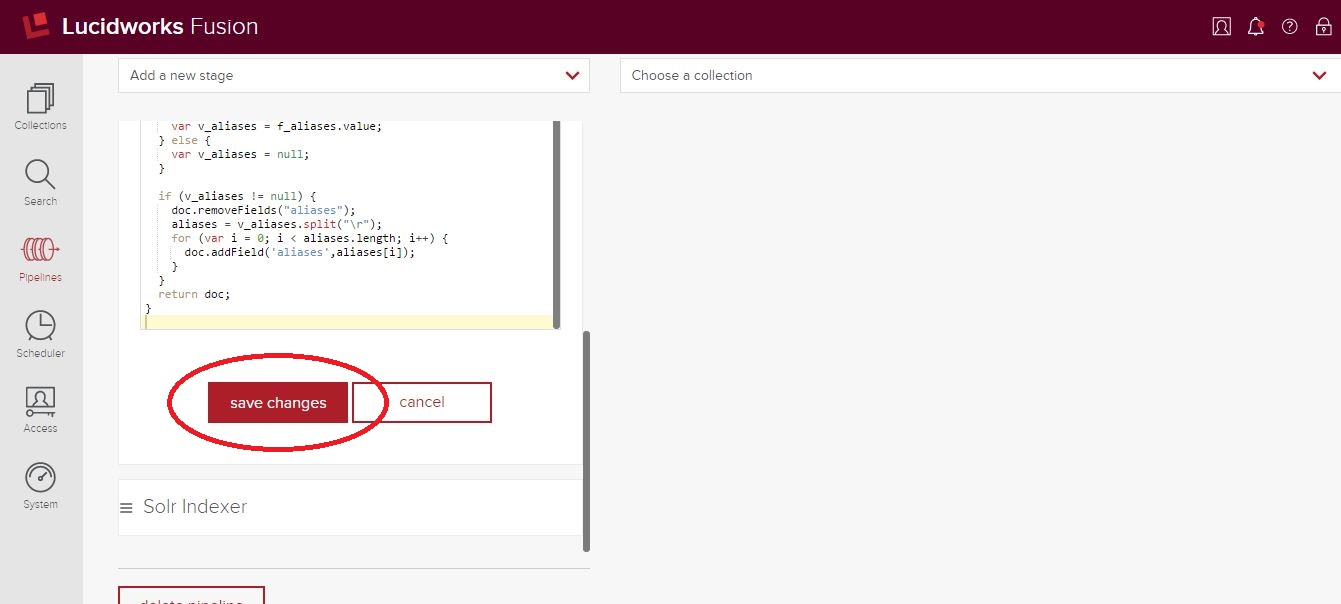
Click “Save Changes” at the bottom of this stage’s properties.
Bringing It All Together
Now we have an index pipeline – let’s see how it works! Fusion does not tie an index pipeline to a specific collection or datasource, allowing for easy reusability. We’ll need to associate this pipeline to the datasource from which we’re retrieving “aliases,” which is accomplished by setting the pipeline ID in that datasource to point to our newly-created pipeline.
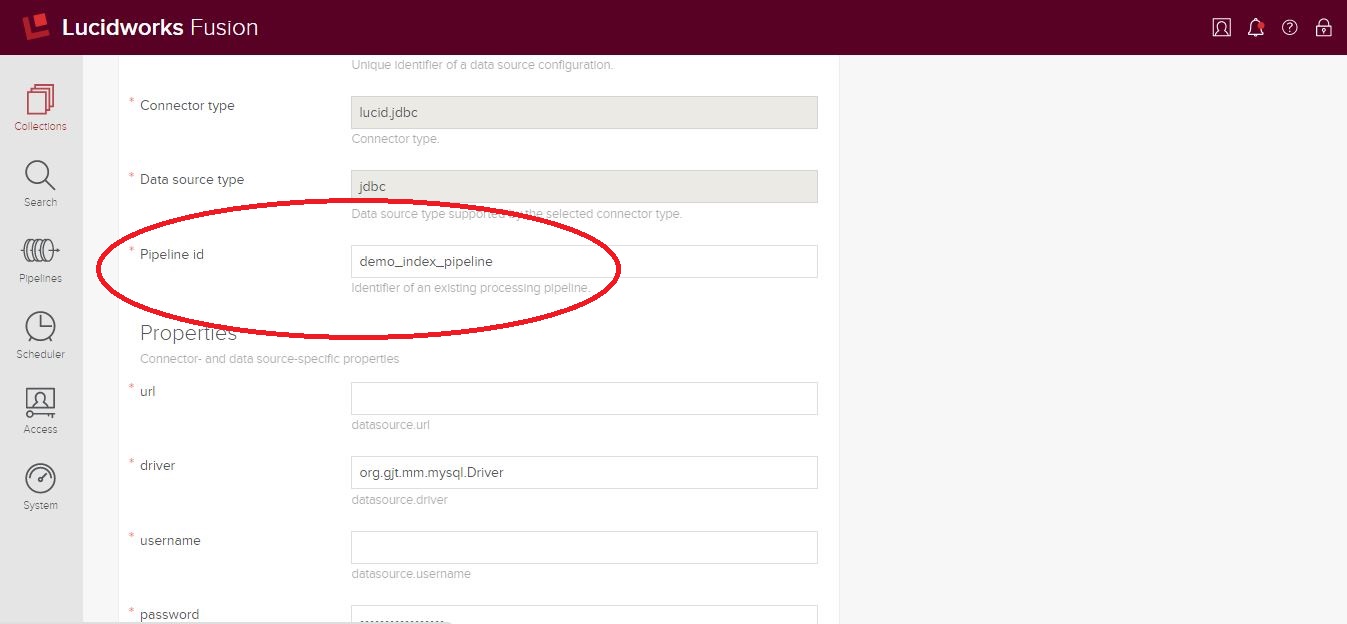
Save your changes and the next time you start indexing that datasource, your index pipeline will be executed.
You can debug your JavaScript stage by taking advantage of the “Pipeline Result Preview” pane, which allows you to test your code against static data right in the browser. Additionally, you can add log statements to the JavaScript by calling a method on the logger object, to which your stage already has a handle. For example:
logger.debug("This is a debug message");
will write a debug-level log message to <fusion home>/logs/connector/connector.log. By combining these two approaches, you should be able to quickly determine the root cause of any issues encountered.
A Final Note
You have probably already recognized the potential afforded by the JavaScript stage; Lucidworks calls it a “Swiss Army knife.” In addition to allowing you to execute any ECMA-compliant JavaScript, you can import Java libraries – allowing you to utilize custom Java code within the stage and opening up a myriad of possible solutions. The JavaScript stage is a powerful tool for any pipeline!
About the Author
Sean Mare is a technologist with over 18 years of experience in enterprise application design and development. As Solution Architect with Knowledgent Group Inc., a leading Big Data and Analytics consulting organization and partner with Lucidworks, he leverages the power of enterprise search to enable people and organizations to explore their data in exciting and interesting ways. He resides in the greater New York City area.
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.