SearchComponents, RequestHandlers, Spellcheckers
I spend most of my configuration time in Solr’s schema.xml, but the solrconfig.xml is also a really powerful tool. I wanted to use my recent spellcheck configuration experience to review some aspects of this important file. Sure, solrconfig.xml lets you configure a bunch of mundane sounding things like caching policies and library load paths, but it also has some high-tech configuration “LEGO blocks” that you can mix and match and re-assemble into all kinds of interesting Solr setups. Three main Building Blocks I’ll discuss:
- SearchHandlers (a type of RequestHandler)
- SearchComponents
- Named parameter sets, aka Named Configs
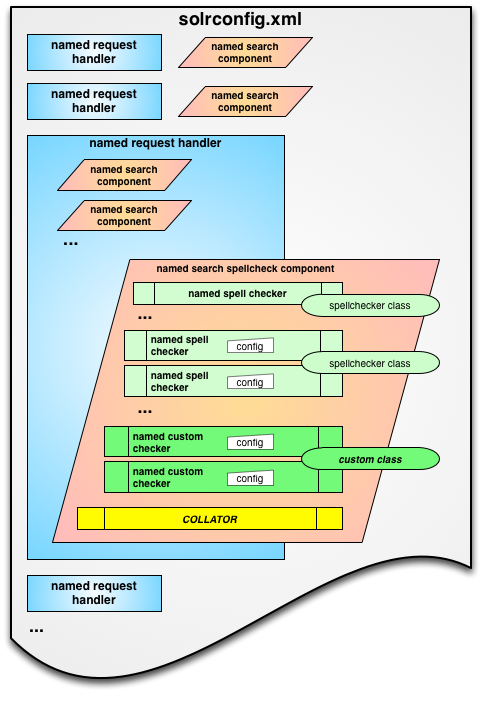
solrconfig.xml nests search components (including spellcheckers)
underneath request handlers. I’ll detail each of these after the break…
RequestHandlers
In the conceptual diagram above you’ll notice a number of high-level RequestHandlers are defined, shown as blue rectangles. These define the main entry points into Solr, and include some text you may have noticed in the URLs like /select, /update, /browse and /spell. Request Handlers are called by the Request Dispatcher, and are the containers for SearchComponents. SearchHandler is a particular type of RequestHandler that will be of particular interest.
SearchComponents
SearchComponents do the actual work, such as doing an actual search (via QueryComponent), calculating facets, highlighting matching terms, or adding spellchecking suggestions. In the above diagram these are the orange parallelograms (tilted rectangles).
Multiple Search Components can be strung together inside of a Search Handler, and this is where the LEGO blocks analogy comes from. SearchHandlers are composed of one or more SearchComponents.
An Exception
Remember I said that the diagram above conceptual? If I pointed out that the default /select Request Handler has six Search Components (query, facet, mlt/MoreLikeThis, highlight, stats & debug), you’d probably assume you could open solrconfig.xml, find the Search Handler that takes care of /select, and see those six Search Components defined right there – well… they aren’t.
For various technical and legacy code reasons, there’s a special predefined Java class called “SearchHandler” that is hard coded to include the 6 search components by default. It’s still a Search Handler that contains 6 Search Components, but it’s just not defined in solrconfog.xml.
If you wanted to, you could define your own Search Handler and configure it to have the same 6 Search Components. It’s more common for folks to add additional Search Components to the 6 that already run, or to define a Search Handler with many fewer components.
Spell Checking SearchComponents
The SpellCheckComponent is a particularly interesting example of a Search Component because it’s actually composed of additional subcomponents, which are the base spell checker classes. So one Spell Checker Search Component can be composed of multiple spellcheck classes (plus a collator, which I’ll explain later).
“Named Configs”
The third building block of configuration is Solr’s mechanism for named sets of configuration data, or what I’ll call “Named Configs”. In the diagram above they’re show as small white blocks labeled “config”. If you’ve ever looked at solrconfig.xml you’ll have noticed a lot of <lst name="xyz"> XML structures, where “xyz” can be any arbitrary name, but is often called “default”. Under each of these are sets of name/value pairs of the form <str name=”paramName”>param_value</str>.
These Named Configs are a general concept in Solr and are not specific to just Request Handlers and Search Components – you’ll see them everywhere! And what exactly do these Named Configs do? As you probably know, Solr is implemented in Java, an object based language. You can have more than one instance of a Java object class, and each instance can have its own distinct configuration. The named sets of configurations in solrconfig.xml are specifying various Java classes in Solr, but also passing them specific sets of configuration settings. For example, the FileBasedSpellChecker uses a text file of terms to make spelling suggestions from. Through configuration, you could have one instance called “english_dictionary” and another called “french_dictionary”, each reading terms from its own language appropriate file. (there’s reasons outlined in the wiki why you might not want to use FileBasedSpellCheckers at all, but it’s a very good example for understanding named configs)
In the diagram above you’ll notice green rectangles representing defined low-level spellcheckers, and green rounded rectangles representing the actual Java classes that they refer to. But notice there are two pairs of green rectangles that are sharing common Java classes; although they reference the same class, each definition includes its own “config” module that sets the parameters for that specific instance.
Possible Named Config Confusion
Named Configs have a few things that make them confusing at times.
For example, there’s yet another discrepancy between the conceptual diagram above and what you’d actually see in solrconfig.xml is the location of the Named Config settings within the file – typically they’re defined once, and then referenced elsewhere.
Also, since Named Configs are used for many different contexts, more than one config set can have the same name; this is particularly true of the name “default”! You can have defaults for different Request Handlers all named “default”.
And another exception: When a config set is named “default”, that’s a magic name, and doesn’t have to be explicitly referenced anywhere else.
Another potentially confusing aspect of these names in the default solrconfig is that they’re often very generic looking, and it’s not always obvious to new users that these are arbitrary labels that will be referenced from other parts of the config file, vs. an important fixed keyword.
For example, the default Solr config for the file based spell checker mentioned above is called “file”, as in <str name="name">file</str>, and in another part of the example config it’s referenced via <str name="spellcheck.dictionary">file</str>. If you were creating your own configuration it might be clearer to name it something like “flat_file_config”, so that you’d define it with <str name="name">flat_file_config</str> and reference it via <str name="spellcheck.dictionary">flat_file_config</str>.
Revisiting the earlier example of having both an English and French dictionary, you’d define two named configs “english_dictionary_file_config” and “french_dictionary_file_config”, and reference each separately via the spellcheck.dictionary parameter. Although it’s much longer to type, it’s certainly more self-documenting, and besides that’s what Copy & Paste is for!
And yet one more potentially confusing note specific to spellchecking is the somewhat poorly named spellcheck.dictionary parameter, which is used to reference any type of spellchecker sub-component, even if it’s not based on a dictionary at all! This is just another legacy code thing to keep track of.
For example, to reference the configuration for the very useful WordBreakSolrSpellChecker configuration, you’d say <str name="spellcheck.dictionary">wordbreak</str>.
And just a bit more confusion on Named Configs in relation to spellchecking: Normally Named Configs that will be used in the same context should have different names. But in the case of spell checking, there are multiple configurations named “spellchecker”, and this is intentional and a good thing! This is the name attribute; but each one also has an <str> sub-element also called name, which names the configuration set.
For example:
<lst name="spellchecker"> <str name="name">default</str> ... <lst name="spellchecker"> <str name="name">wordbreak</str> ... <lst name="spellchecker"> <str name="name">jarowinkler</str> ...
Deciphering this:
- The top level
<lst>is the container for the named configuration, and it has an XML attribute of “name”. This is used for internal querying of the XML tree and should not be changed. - The nested
<str>elements are the name/value pairs. In pseudo code we’d sayfoo=bar, but in Solr XML syntax it would be<str name="foo">bar</str>. Conceptually, later on we could sayprint myConfig.fooand it would print out “bar”. - Earlier I mentioned that named configs have arbitrary identifying names, in this example we’re defining three names: “default”, “wordbreak” and “jarowinkler”. These are registered by having a
<str>sub-element literally called “name” whose value is the name we want to actually register. Thinking again in pseudo code, instead of sayingfoo=barwe now want to sayname=wordbreak. So instead of<str name="foo">bar</str>we have<str name="name">wordbreak</str>. It’s just an odd-looking syntax coincidence that we seename="name"inside the<str>tag. - Solr will gather up all of the
<lst>elements with attribute name spellchecker and will file them away by the name defined by the<str>sub-element value named “name”. This will later be referenced by-name via spellcheck.dictionary.
If you’re feeling confused, try looking at a bunch of solrconfig.xml examples and it may become clearer. There is logic here, and the XML mechanism provides a really powerful way to change Solr’s behavior without always needing to break out a Java compiler, it’s just that it looks a bit odd at times.
Importance of the Collator
The Collator combines all of the raw spelling suggestions from all of low level spellcheck classes, does some filtering, and then produces fully rewritten queries that can be displayed as clickable links in the results list, or shown as dynamic autocomplete suggestions while the user is typing into the search box.
The low-level spellcheck classes tend to operate on a word-by-word basis, even when the user’s query contains multiple words; they’re just providing low-level suggestions for each specific word. Since some of the low-level spellcheck classes don’t even look at your Solr index, they may very well be suggesting alternate words that don’t even exist in your documents! But that’s OK, these low-level classes are simple by design, they’re just coming up with candidate suggestions. Configured spellcheckers are allowed to call multiple low-level spellcheck classes, to potentially get a large number candidate suggestions.
It’s the Collator’s job to combine and then sift through all of these suggestions by checking the main Solr index. Notice that this also means it’s OK if more than one spellcheck class suggests the same alternate spelling; the Collator will handle that too! It knows how to combine and deduplicate all of the candidates.
Checking the index does take a bit of extra time, it’s actually generating additional searches to do those checks, but in a well running system this take only a few extra milliseconds. The Collator then decides, of all possible word-by-word corrections, which reassembled queries would make for the best suggestion.
Contrasting the low-level spellcheckers with the collator, assuming a user types in “helllo worlld” (both misspelled). Low level spellcheckers will often look at each word individually, so “helllo” might generate the candidates of “hello”, “halo” and “hellion”; and “worlld” might generate the candidates “world”, “would”, “wold” and “worldly”. But assuming Solr’s default content, only “hello” and “world” really make any sense.
And remember that the query was actually two words, not one, so we don’t want to just suggest “hello” or “world”. But the Collator figures all this out and comes back with a proper two word suggestion of “hello world”. Very cool!
This type of delegation of duties (coming up with low-level suggestions vs. coming up with a final set of best rewritten queries) is really nice because you can add in other custom spellcheckers and still let Solr’s Collator keep your more “creative” spelling suggestions from getting to users. If you had a ton of content, it might be that “halo wold” (both valid English words) would have also been a reasonable suggestion. And the Collator lets you make lots of choices about how many candidates to try, how many suggestions to present, how common a word must be to be considered right or wrong, etc. Very cool stuff.
In Summary
Remember the primary building blocks in solrconfig.xml: SearchHandlers contain SearchComponents that are defined with Named Config Blocks that refer to Java classes. You can then reference the SearchComponents in multiple SearchHandlers as needed.
For Spelling Suggestions, there are low-level spell checkers that come with candidate alternative spellings on a word-by-word basis. It’s the Collator’s job to tabulate, deduplicate and check these candidates against the actual search index, and then produce one or more valid and complete queries.
Some JIRA issues to be aware of: If you’re using Solr 4.3 or later you should be OK, but if you’re using earlier versions be advised that the example Solr application had some configuration and template issues that prevented Spellcheck from working out of the box. See JIRA bugs SOLR-4680,SOLR-4681 andSOLR-4702.
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.