How StubHub De-Dupes with Apache Solr
How StubHub detects and removes duplicates in their Solr index without compromising on quality and performance.
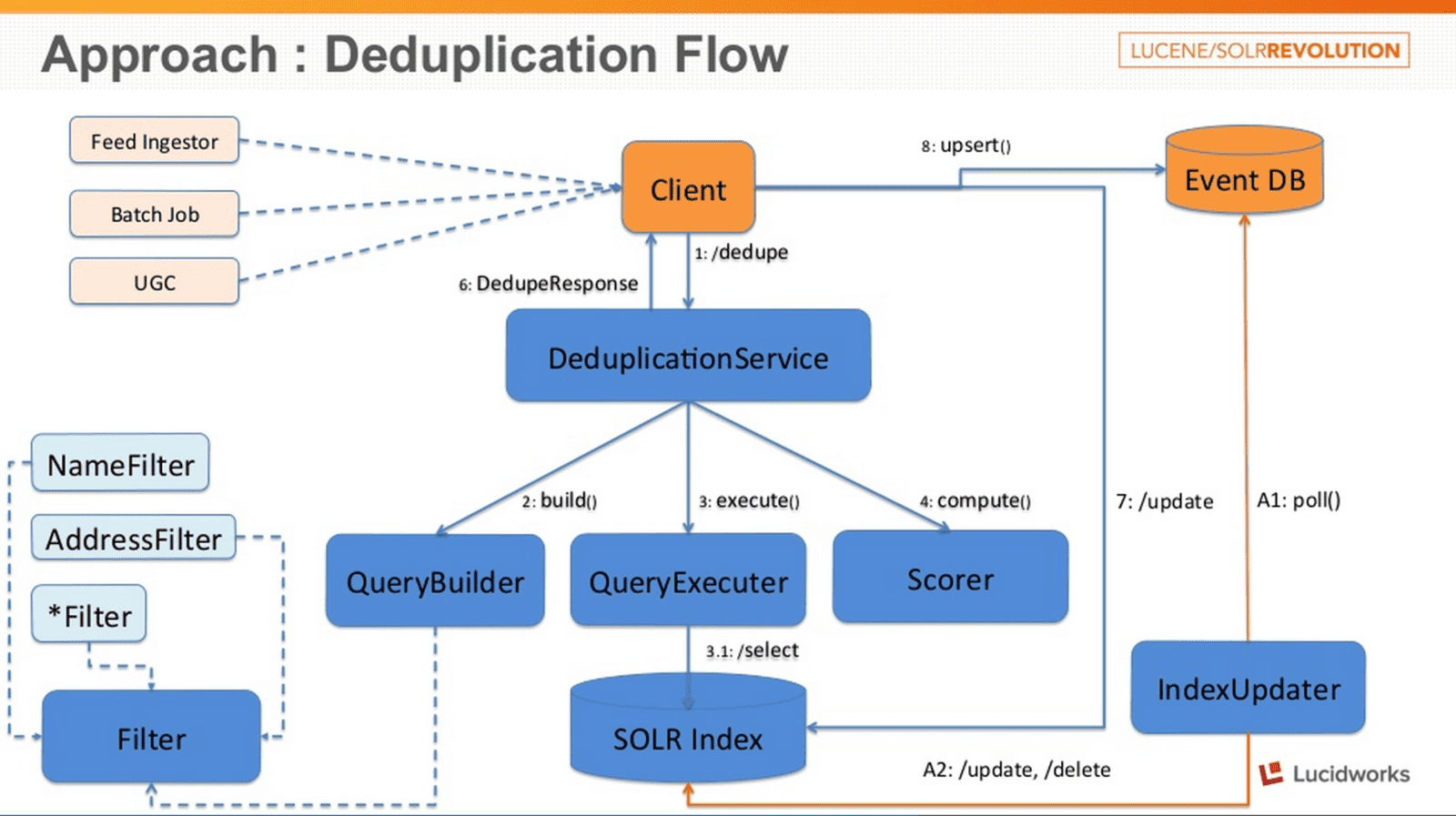
As we countdown to the annual Lucene/Solr Revolution conference in Austin this October, we’re highlighting talks and sessions from past conferences. Today, we’re highlighting StubHub engineer Neeraj Jain’s session on de-duping in Solr.
Stubhub handles large number of events and related documents. Use of Solr within Stubhub has grown from search for events/tickets to content ingestion. One of the major challenges that are faced in content ingestion systems is to detect and remove duplicates without compromising on quality and performance. We present a solution that involves spatial searching, custom update handler, custom geodist function etc, to solve the de-duplication problem. In this talk, we’ll present design and implementation details of the custom modules and APIs and discuss some of the challenges that we faced and how we overcame them.
We’ll also present the comparison analysis between old and the new system used for de-duplication.
Neeraj Jain is an engineer working with Stubhub Inc in San Francisco. He has a special interest in search domain and has been working with SOLR for over 4 years. He also has interest in mobile app development; he works as a freelancer and has applications on Google play store and iTunes store that are built using SOLR. Neeraj has a Masters in Technology degree from the Indian Institute of Technology, Kharagpur.
![]() Join us at Lucene/Solr Revolution 2015, the biggest open source conference dedicated to Apache Lucene/Solr on October 13-16, 2015 in Austin, Texas. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
Join us at Lucene/Solr Revolution 2015, the biggest open source conference dedicated to Apache Lucene/Solr on October 13-16, 2015 in Austin, Texas. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.