Analyzing Enron with Solr, Spark, and Fusion

At Lucene/Solr Revolution this year I taught a course on using Big Data technologies with Apache Solr and by extension Lucidworks Fusion. As part of the course we ingested the Enron corpus as provided by Carnegie Mellon University. The corpus consists of a lot of emails, some poorly formed from the early part of the last decade that were part of the legal discovery phase of the investigation into energy company’s flameout in 2001. It is a pretty substantial piece of unstructured data at 423MB compressed.
During the course of this article, we’re going to index the Enron corpus, search it with Solr and then perform sentiment analysis on the results. Feel free to follow along, grab a copy of the Enron corpus and untar it into a directory on your drive. You can grab the referenced code from my repository here.
Why Spark and Solr?
Why would you want to use Solr if you’re already using Spark? Consider this: If you’ve got a substantial amount of stored data that you’re going to perform analytics on, do you really want to load ALL of that data in memory just to find the subset you want to work on? Wouldn’t it make more sense to load only the data you need from storage? To do this, you need smarter storage! You can to index the storage as you store the data or in batches sometime afterwards. Otherwise, everyone performing the same analysis is probably running the same useless “find it” process before they actually start to analyze it.
Why would you want to use Spark if you’re already using Solr? Solr is amazing at what it does, finding needles or small haystacks inside of a big barn full of hay. It can find the data you need to match the query you provide it. Solr isn’t, by itself, however machine learning or has any of the analytics you might want to run. When the answer to your query needs to be derived from a massive amount of data, you really need a really fast distributed processing engine – like Spark – to do the algorithmic manipulation.
Lucidworks Fusion actually gets its name from “fusing” Spark and Solr together into one solution. In deploying Solr solutions for customers, Lucidworks discovered that Spark was a great way to augment the capabilities of Solr for everything from machine learning to distributing the processing of index pipelines.
Ingesting
Back in 2013, Erik Hatcher showed you a way you could ingest emails and other entities using Solr and a fair amount of monkey code. At Lucene/Solr Revolution, given that my mission wasn’t to cover ingestion but using Spark with Solr, I just used Fusion to ingest the data into Solr. The process of ingesting the Enron emails with is easy and Fusion UI makes it dead simple.
- Download, Install and Run Lucidworks Fusion.
- Go to http://localhost:8764 and complete the fusion setup process. Skip the Quickstart tutorial.
Note: screenshots are from the upcoming Fusion 3.x release, this has been tested with 2.4.x but the look/feel will be slightly different.
- Navigate to the Fusion collection screen (on 2.4 this is the first screen that comes up, on 3.x click devops)
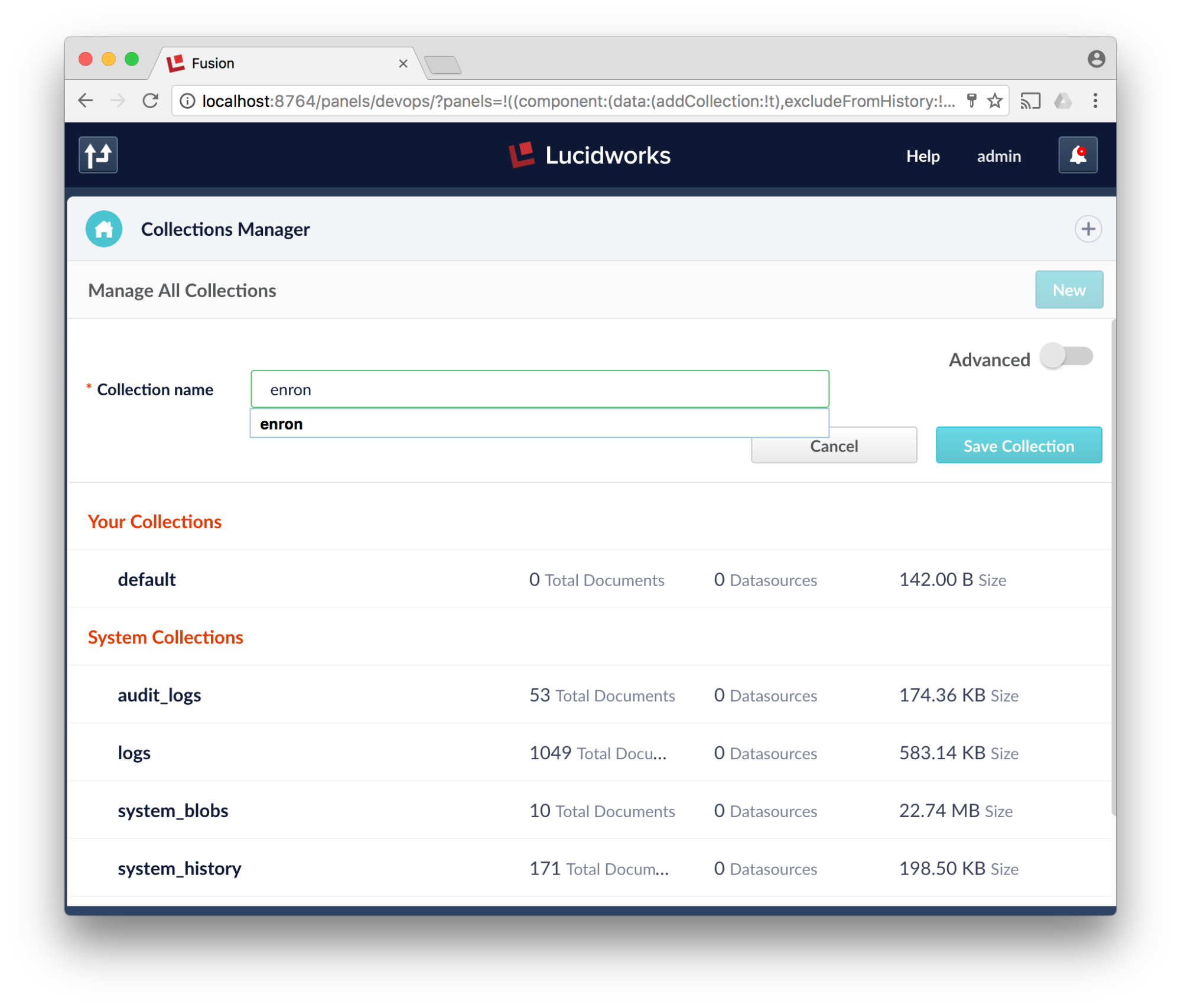
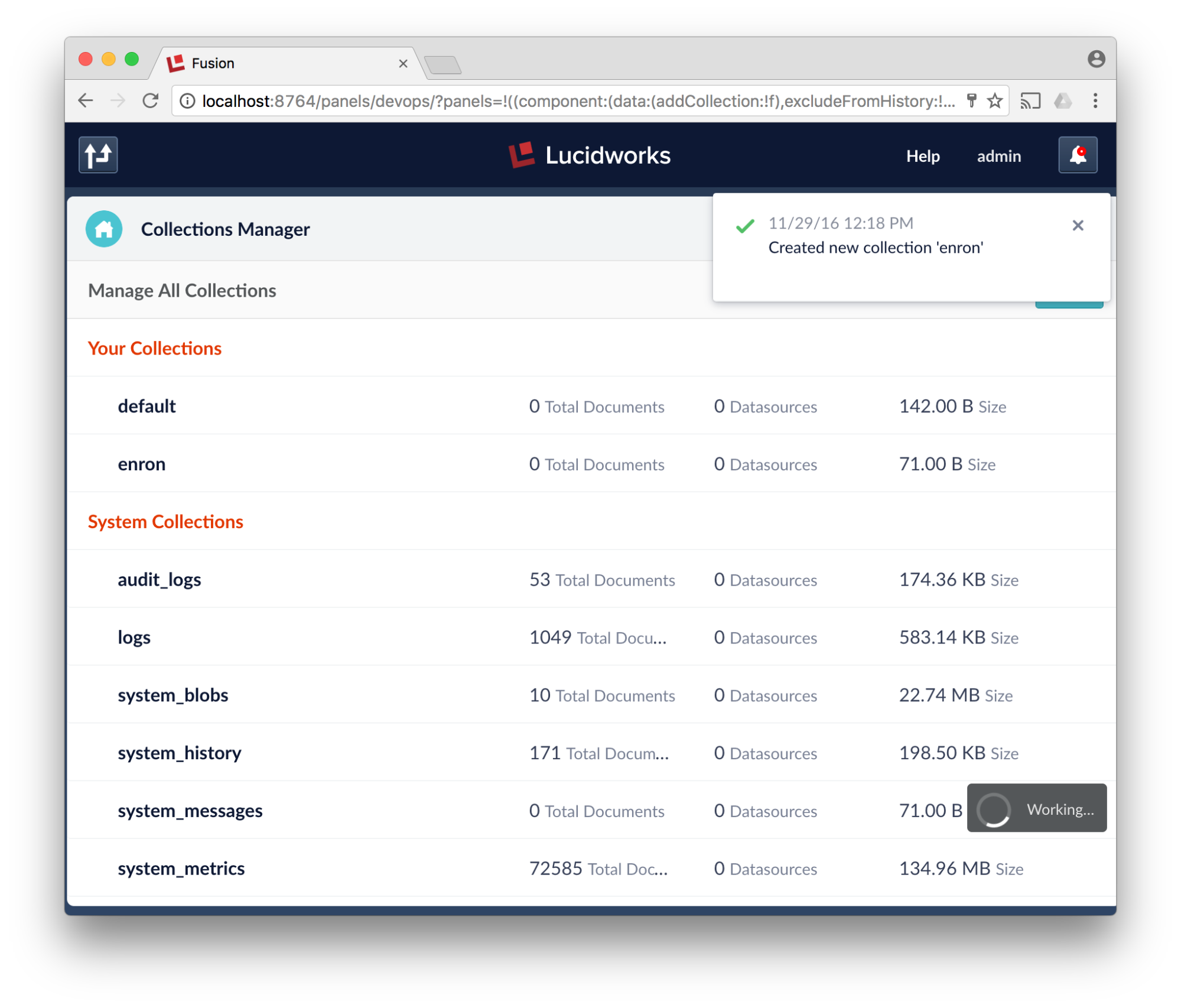
- Click New collection, type enron and click save.
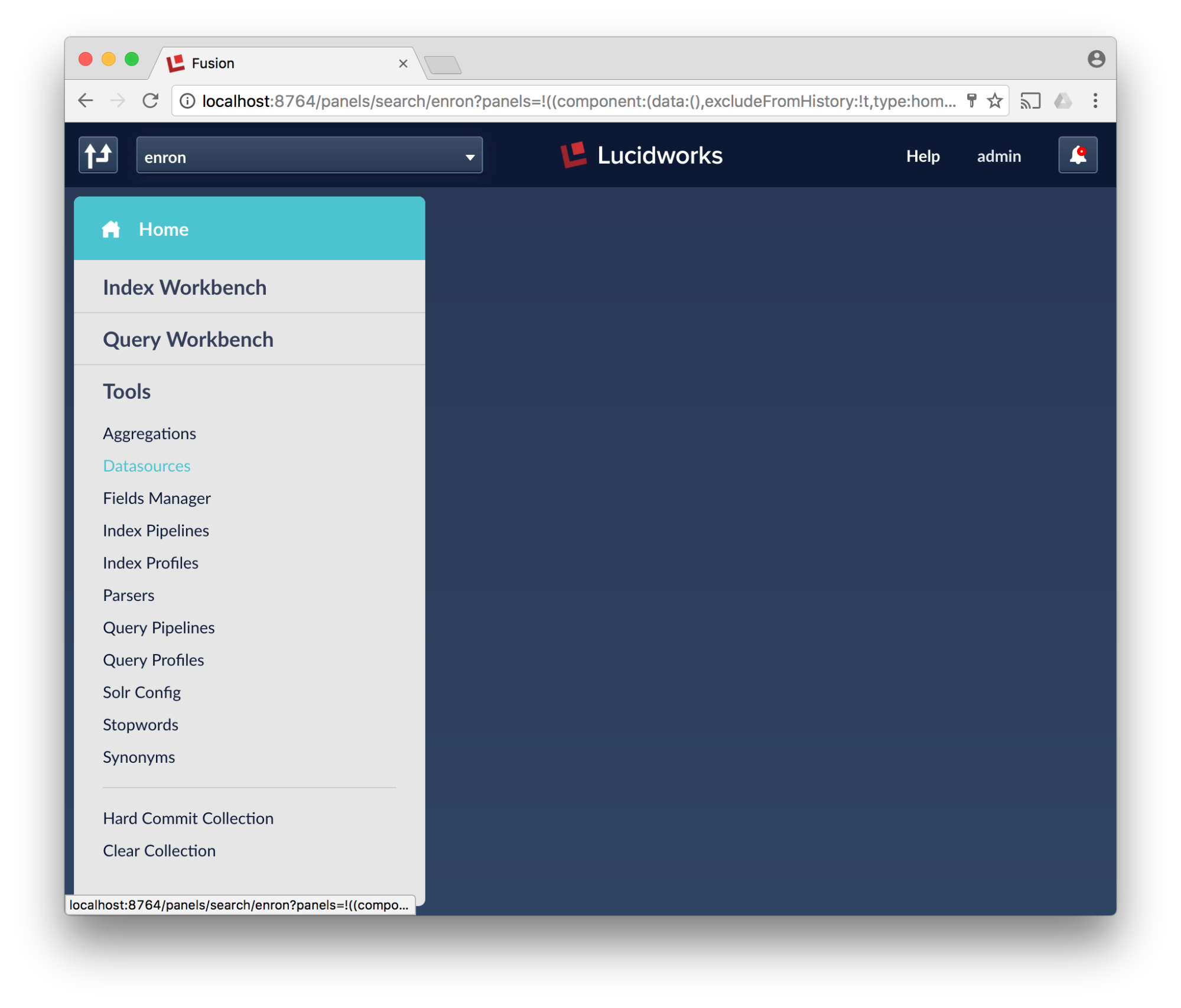
- Click on the newly created “enron” collection, then click “datasources”.
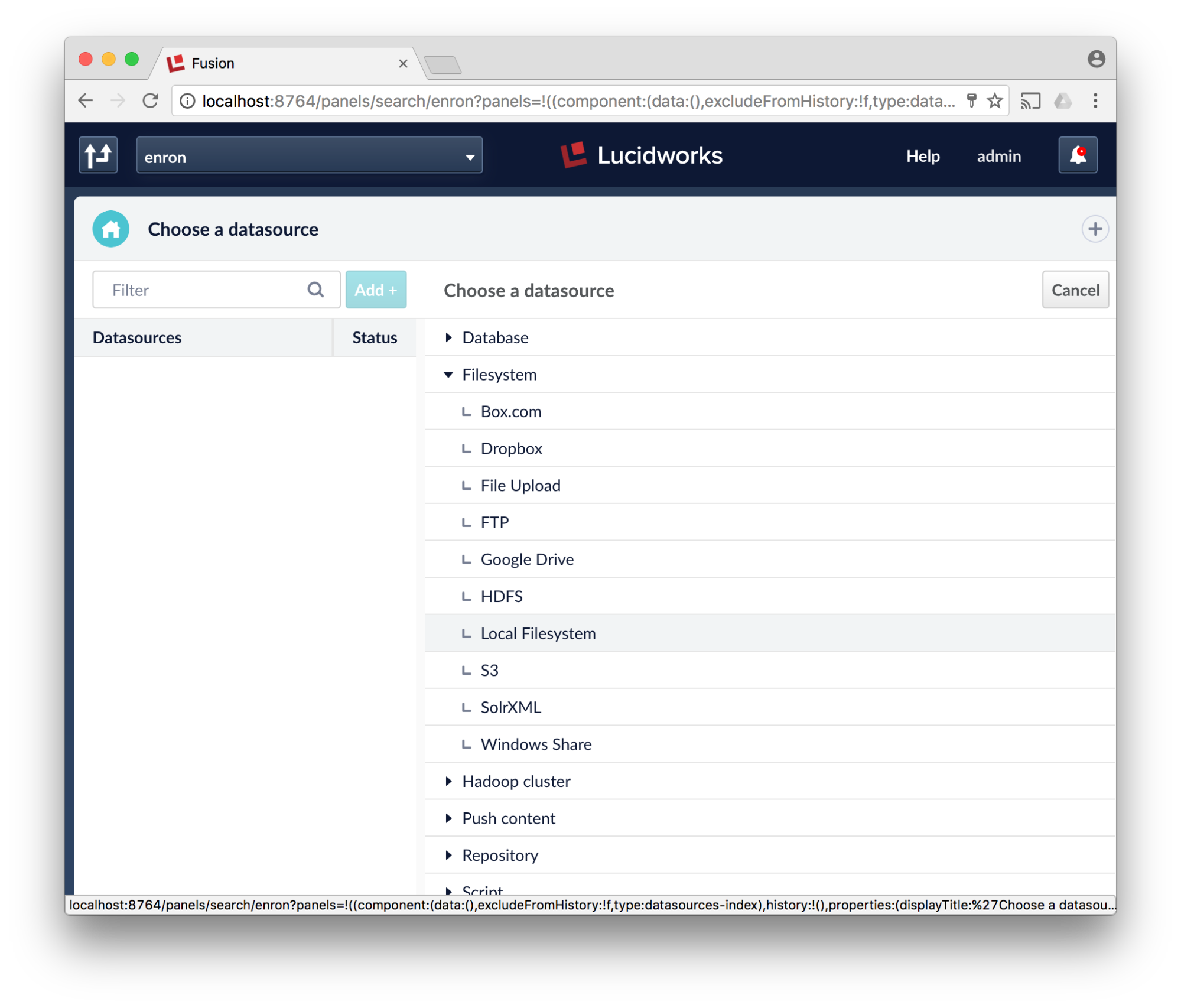
- Create a new Local Filesystem Datasource
- Call the datasource enron-data then scroll down
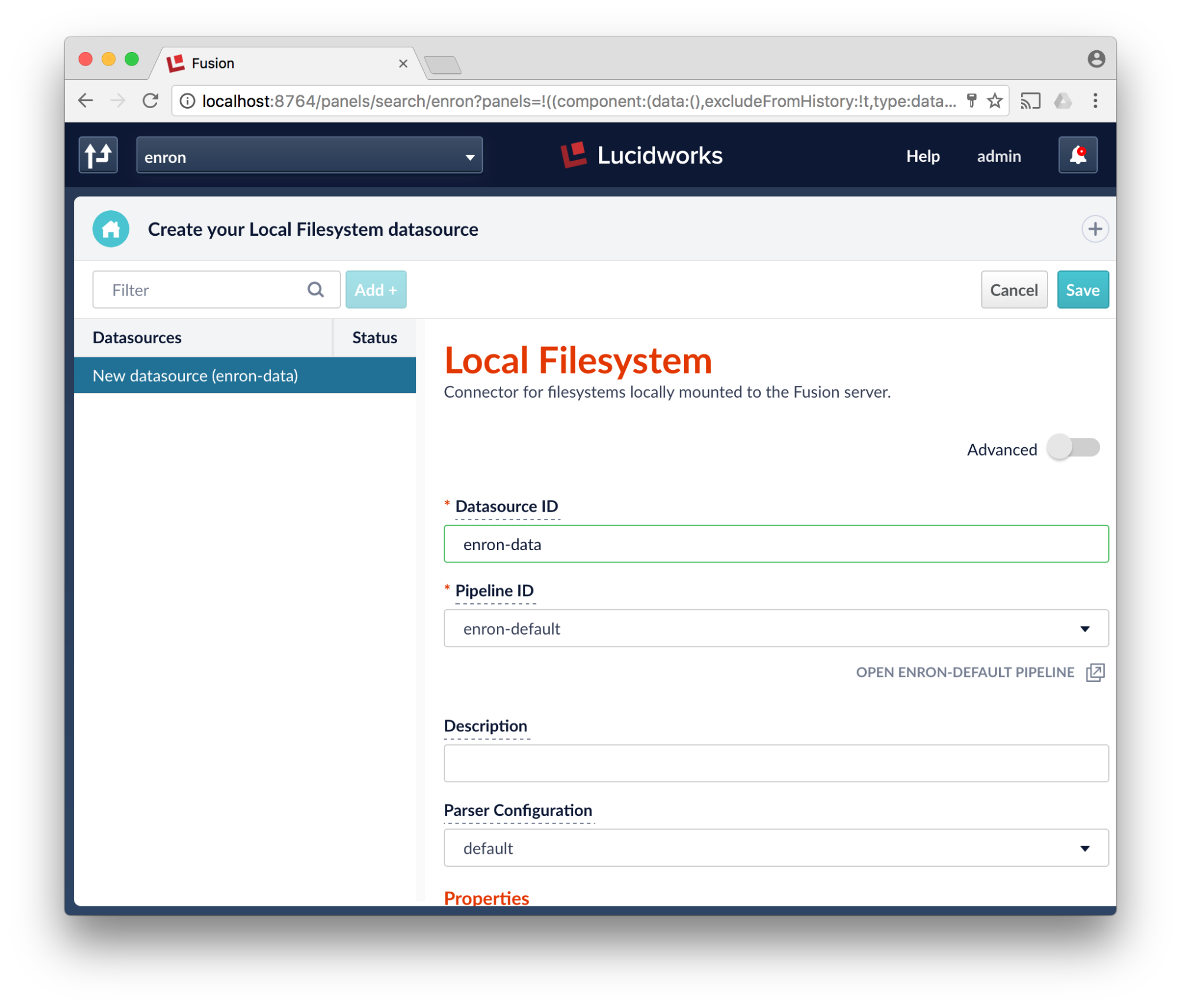
- Expand the “StartLinks” and put in the full path to where you unzipped the enron corpus (root directory), then scroll or expand “limit documents”
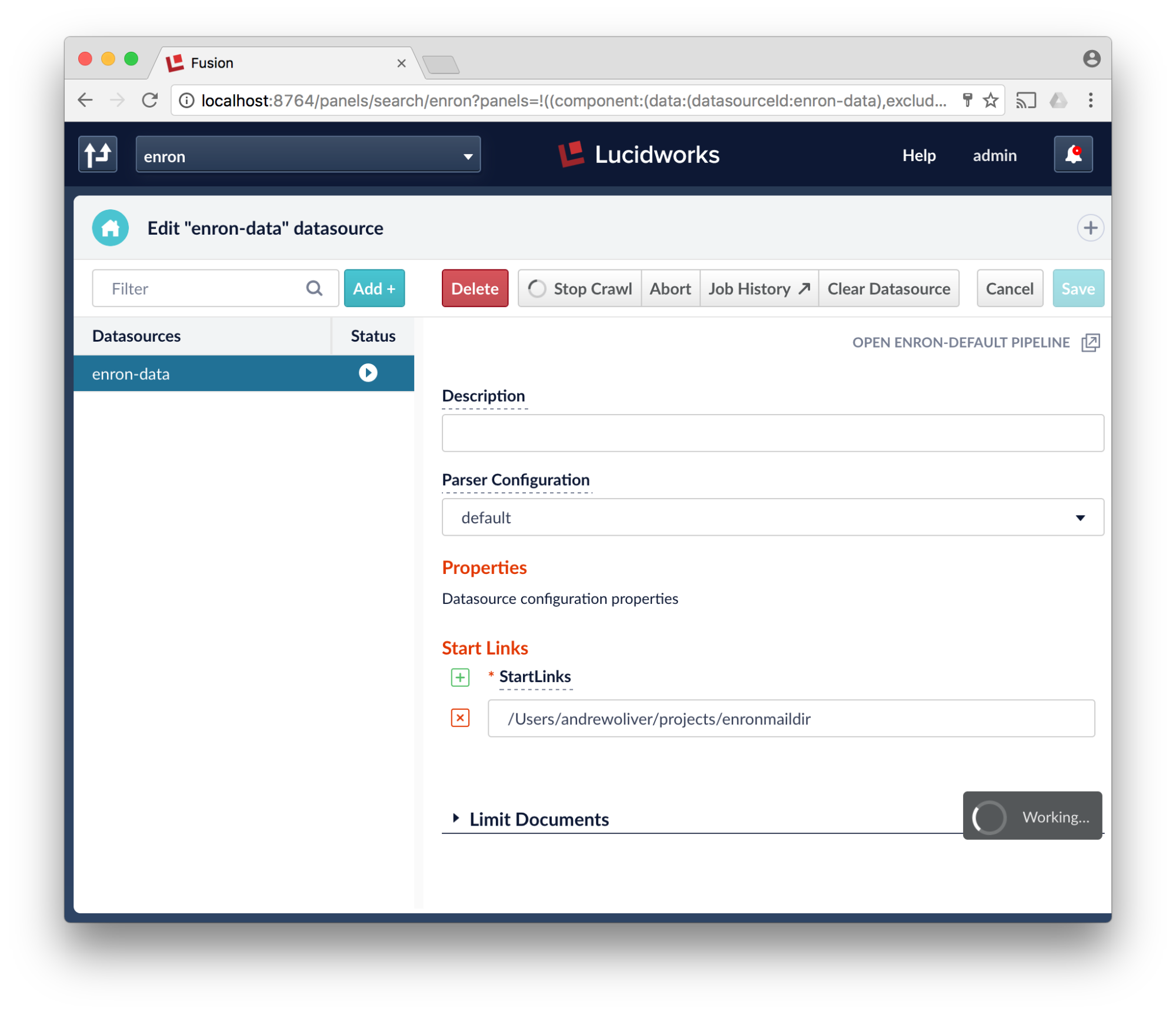
- Up the maximum filesize, I just added a 0. Some of the files in the enron corpus are large. Scroll down more.
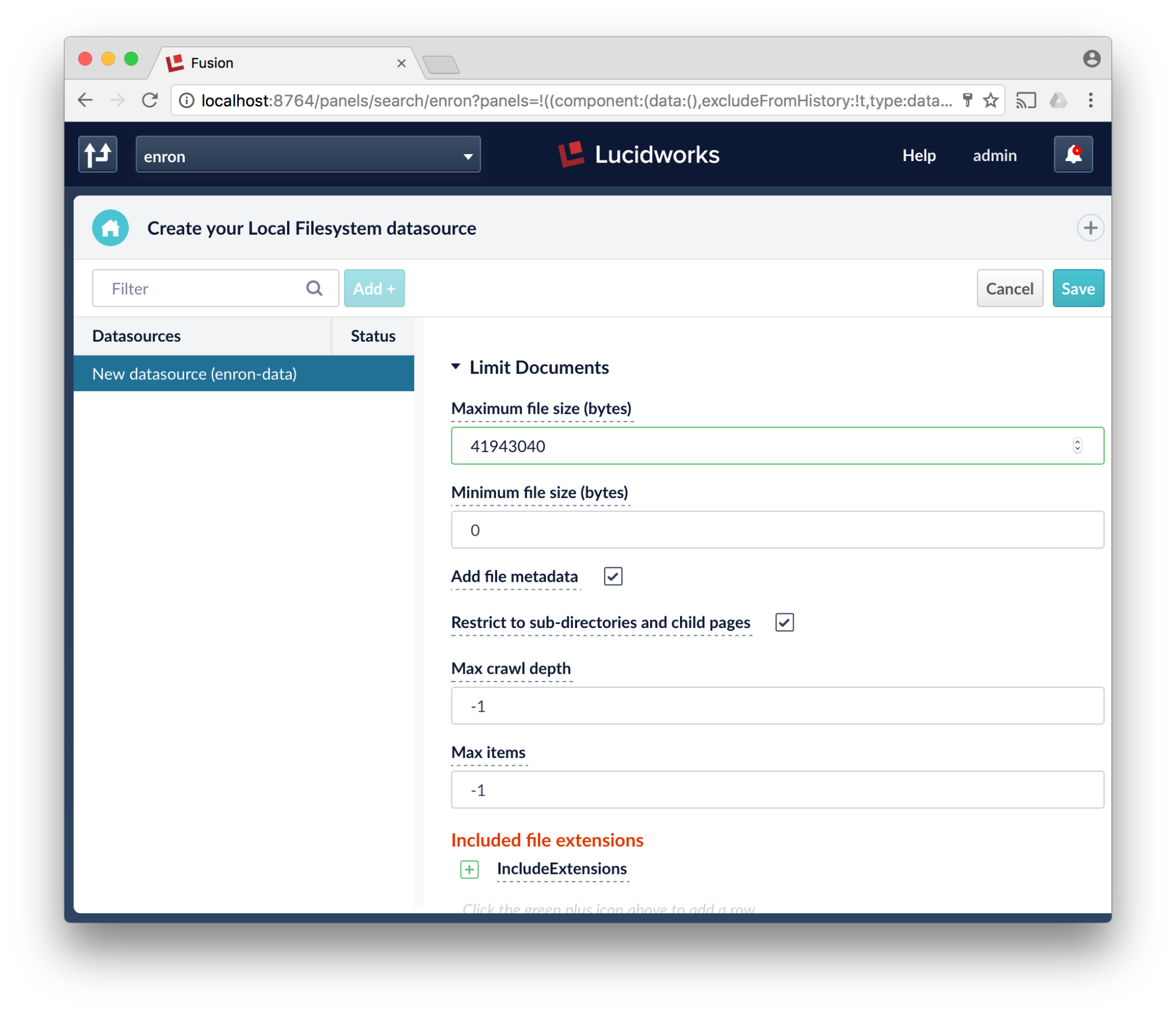
- Save the datasource
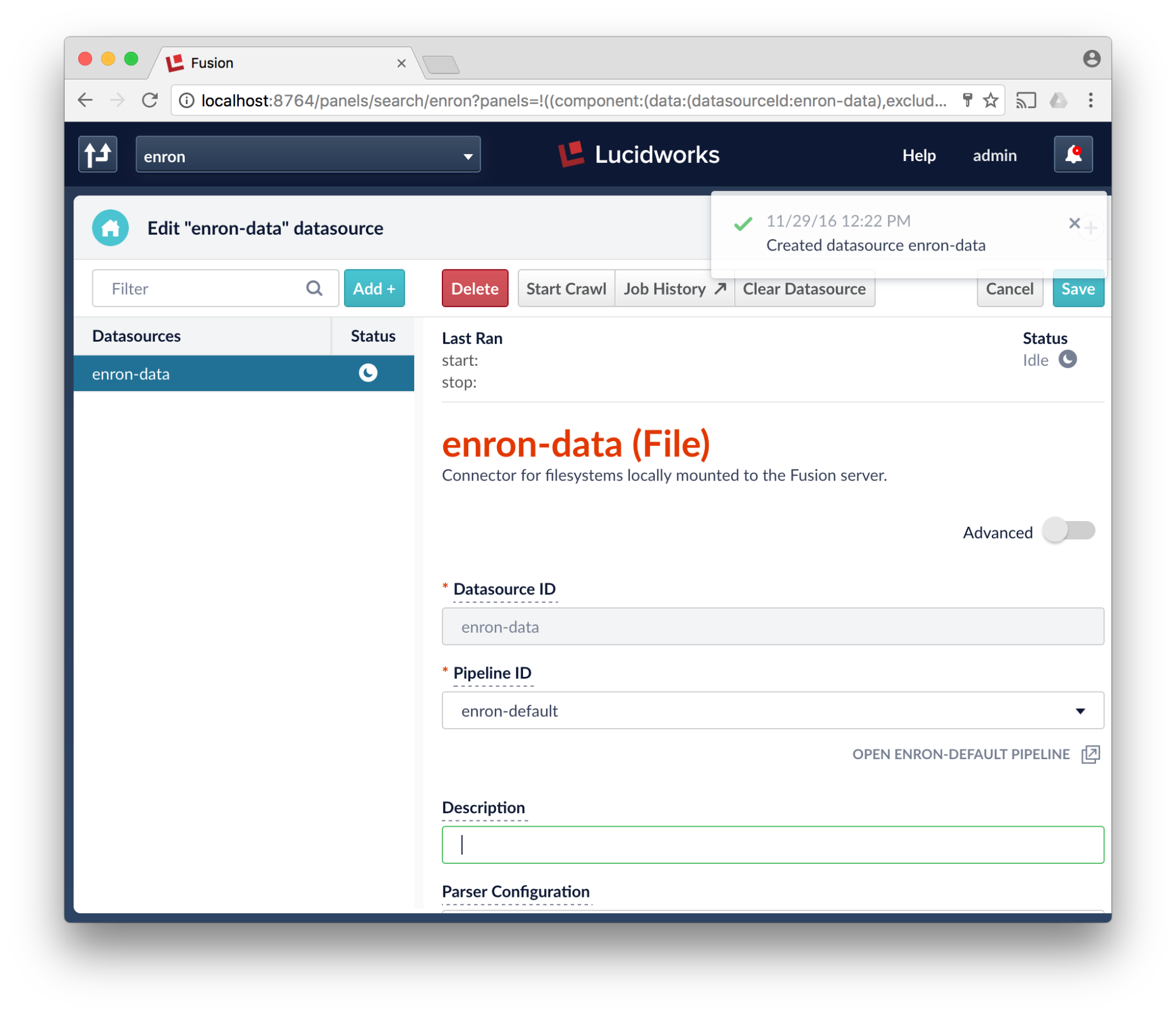
- Click Start Crawl
- Click Job History and select your job
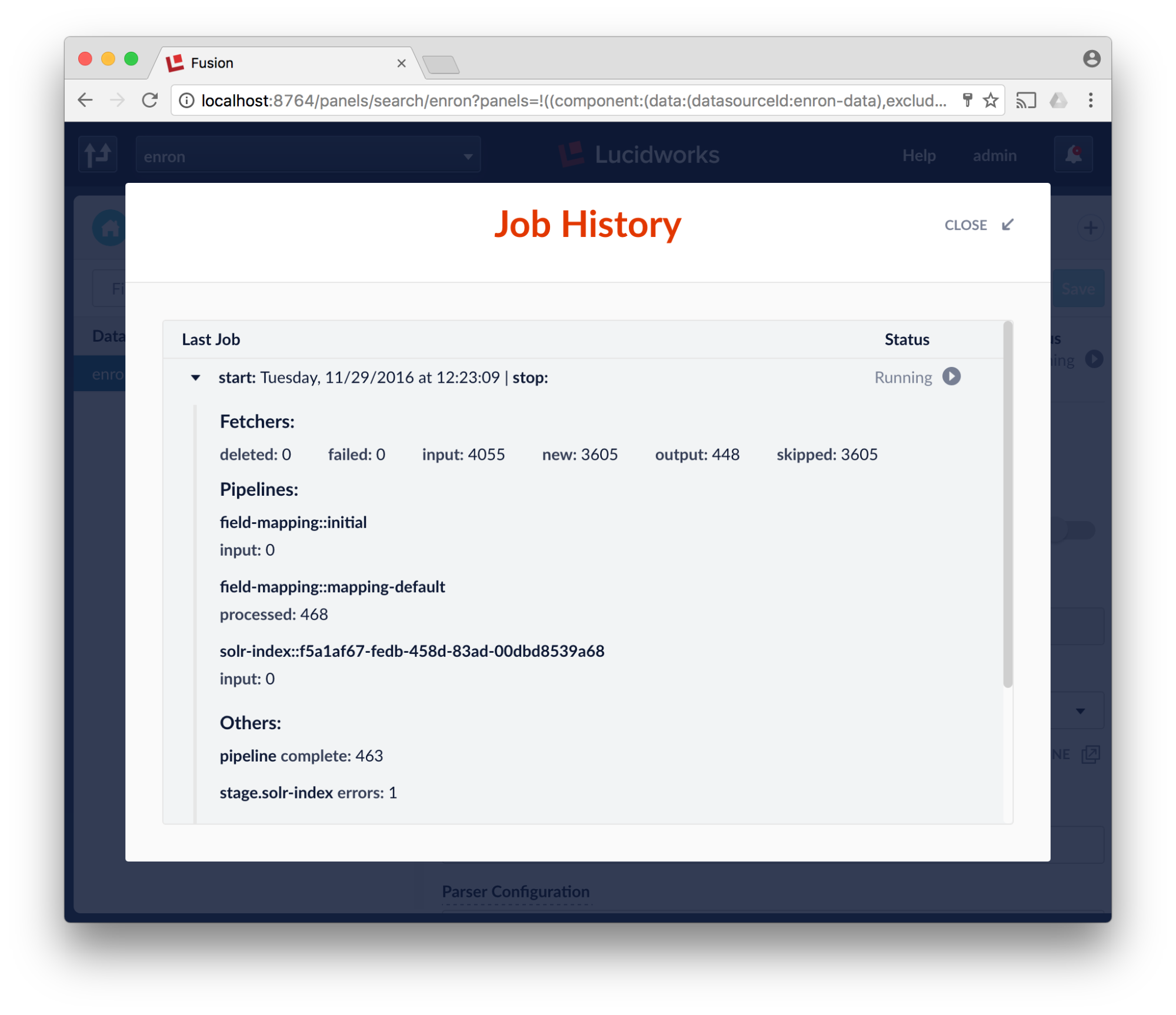
- Watch the pot boil, this will take a bit if you’re doing it on your laptop.
There will be some of the emails that will be skipped due to poor-formedness, lack of content or other reasons. In a real project, we’d adjust the pipeline a bit. Either way, note that we got this far without touching a line of code, the command line or really doing any heavy lifting!
Spark / Spark-Solr
If you’re using Solr, my colleague Tim, showed you how to get and build the spark-solr repository back in August of last year.
If you use Fusion, Spark-Solr connectivity and Spark itself are provided. You can find them in the $FUSION_HOME/apps/libs/spark-solr-2.2.2.jar and the spark-shell in $FUSION_HOME/bin. To launch the Spark console you type: bin/spark-shell
Scala Briefly
Scala is the language that Spark is written in. It is a type-safe functional language that runs on the Java Virtual Machine. The syntax is not too alien to people familiar with Java or any C-like language. There are some noticeable differences.
object HelloWorld {
def main(args: Array[String]) {
println("Hello, world!")
}
}
Spark also supports Python and other languages (you can even write in functional Java). Since Spark is Scala natively, Scala always has the best support and there are performance penalties for most other languages. There are great reasons to use languages such as Python and R for statistics and analytics such as various libraries and developer familiarity, however, a Spark developer should at least be familiar with Scala.
In this article we’ll give examples in Scala.
Connecting Spark to Solr
Again, launch the Spark shell that comes with Fusion by typing bin/spark-shell. Now we need to specify the collection, query, and fields we want returned. We do this in an “options” variable. Next we read a dataframe from Solr and load the data. See the example below:
val options = Map(
"collection" -> "enron",
"query" -> "content_txt:*FERC*",
"fields" -> "subject,Message_From,Message_To,content_txt"
)
val dfr = sqlContext.read.format("solr");
val df = dfr.options(options).load;
If you’re not using Fusion, you’ll need to specify the zkHost and you may also need to add the spark-data library and its dependencies with a –jars argument to spark-shell. In Fusion, we’ve already handled this for you.
Poor Man’s Sentiment Analysis
Provided in the repository mentioned above is a simple script called sentiment.scala. We demonstrate a connection to Solr and a basic script to calculate sentiment. Sentiment analysis on emails can be done for any number of purposes: maybe you want to find out general employee morale; or to track customer reactions to particular staff, topics or policies; or maybe just because it is fun!
We need to do something with our DataFrame. I’ve always had a soft spot for sentiment analysis because what could be better than mathematically calculating people’s feelings (or at least the ones they’re trying to convey in their textual communication)? There are different algorithms for this. The most basic is to take all the words, remove stop-words (a, the, it, he, she, etc), and assign the remaining words a value that is negative, positive, or neutral (say -5 to +5), add up the values and average it. There are problems with this like “This is not a terrible way to work” comes out pretty negative when it is actually a positive to neutral sentiment.
To really do this, you need more sophisticated machine learning techniques as well as natural language processing. We’re just going to do it the dumb way. So how do we know what is positive or negative? Someone already cataloged that for us in the AFINN database. It is a textfile with 2477 words ranked with a number between -5 and +5. There are alternative word lists but we’ll use this one.
Based on this, we’ll loop through every word and add them up then divide the words by the number of words. That’s our average.
Understanding the Code
abandon -2 abandoned -2 abandons -2 abducted -2 abduction -2 ...
AFINN-111.txt first 5 lines
The first step is to get our afinn datafile as a map of words to values.
We define our bone-headed simplistic algorithm as follows:
val defaultFile = "/AFINN/AFINN-111.txt"
val in = getClass.getResourceAsStream(defaultFile)
val alphaRegex = "[^a-zA-Zs]".r
val redundantWhitespaceRegex = "[s]{2,}".r
val whitespaceRegex = "s".r
val words = collection.mutable.Map[String, Int]().withDefaultValue(0)
for (line <- Source.fromInputStream(in).getLines()) {
val parsed = line.split("t")
words += (parsed(0) -> parsed(1).toInt)
}
Sentiment.scala extract
Next we connect to Solr, query all messages in our “enron” collection related to the Federal Energy Regulatory Commission (FERC) and extract the relevant fields:
val options = Map(
"collection" -> "enron",
"zkhost" -> "localhost:9983",
"query" -> "content_txt:*FERC*",
"fields" -> "subject,Message_From,Message_To,content_txt"
)
val dfr = sqlContext.read.format("solr");
val df = dfr.options(options).load;
Sentiment.scala extract
The idea is to get a collection of from addresses with the affinity score. To do that we have to create a few more collections and then normalize the score by dividing the number of emails mentioning our subject “FERC.”
val peopleEmails = collection.mutable.Map[String, Int]().withDefaultValue(0)
val peopleAfins = collection.mutable.Map[String, Float]().withDefaultValue(0)
def peoplesEmails(email: String, sentiment: Float) = {
var peopleEmail: Int = peopleEmails(email);
var peopleAfin: Float = peopleAfins(email);
peopleEmail += 1;
peopleAfin += sentiment;
peopleEmails.put(email, peopleEmail);
peopleAfins.put(email, peopleAfin);
}
def normalize(email: String): Float = {
var score: Float = peopleAfins(email);
var mails: Int = peopleEmails(email);
var retVal : Float = score / mails
return retVal
}
sentiment.scala extract
Finally, we run our algorithms and print the result:
df.collect().foreach( t => peoplesEmails(t.getString(1), sentiment(tokenize(t.getString(3))) ) ) for ((k,v) <- peopleEmails) println( ""+ k + ":" + normalize(k))
Sentiment.scala extract
The result looks like several lines of
ken@enron.com -0.0075
Because corporate emails of the time looked more like memos than the more direct communications of today most of the sentiment will be pretty close to neutral. “FERC is doing this” rather than “Those jerks at FERC are about to freaking subpoena all of our emails and I hope to heck they don’t end up in the public record!!!”
Next Steps
Obviously a list of addresses and numbers are kind of just the start. I mean you might as well visualize the data.
As fun as that may have been and a decent way to demonstrate connecting to Solr/Fusion with Spark, it might not be the best way to do sentiment analysis. Why not just analyze sentiment while you index and store the score in the index itself? You could still use Spark, but rather than analyze a piece of mail every time you query, do it once.
You can also Fusion documentation.
Moreover, we are looking at the sentiment in the data, what about your user’s sentiment in their conversational searches? What about other contextual information about their behavior i.e. Signals. There are a lot of opportunities to use the power of Spark inside of Fusion to produce more powerful analytics and relevant information.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.