Min/Max On Multi-Valued Field For Functions & Sorting
One of the new features added in Solr 5.3 is the ability to specify that you wanted Solr to use either the min or max value of a multi-valued numeric field — either to use directly (perhaps as a sort), or to incorporate into a larger more complex function.
For example: Suppose you were periodically collecting temperature readings from a variety of devices and indexing them into Solr. Some devices may only have a single temperature sensor, and return a single reading; But other devices might have 2, or 3, or 50 different sensors, each returning a different temperature reading. If all of the devices were identical — or at least: had identical sensors — you might choose to create a distinct field for each sensor, but if the devices and their sensors are not homogeneous, and you generally just care about the “max” temperature returned, you might just find it easier to dump all the sensor readings at a given time into a single multi-valued “all_sensor_temps” field, and also index the “max” value into it’s own “max_sensor_temp” field. (You might even using the MaxFieldValueUpdateProcessorFactory so Solr would handle this for you automatically every time you add a document.)
With this type of setup, you can use different types of Solr options to answer a lot of interesting questions, such as:
- For a given time range, you can use
sort=max_sensor_temp descto see at a glance which devices had sensors reporting the hottest temperatures during that time frame. - Use
fq={!frange l=100}max_sensor_tempto restrict your results to situations where at least one sensor on a device reported that it was “overheating”
…etc. But what if you one day decide you’d really like to which devices have sensors reporting the lowest temperature? Or readings that have ever been below some threshold which is so low it must be a device error?
Since you didn’t create a min_sensor_temp field in your index before adding all of those documents, there was no easy way in the past to answer those types of questions w/o either reindexing completely, or by using a cursor to fetch all matching documents and determine the “min” value of the all_sensor_temps field yourself.
This is all a lot easier now in Solr 5.3, using some underlying DocValues support. Using the field(...) function, you can now specify the name of a multi-valued numeric field (configured with docValues="true") along with either min or max to indicate which value should be selected.
For Example:
- Sorting:
sort=field(all_sensor_temps,min) asc - Filtering:
fq={!frange u=0}field(all_sensor_temps,min) - As a pseudo-field:
fl=device_id,min_temp:field(all_sensor_temps,min),max_temp:field(all_sensor_temps,max) - In complex functions: facet.query={!frange key=num_docs_with_large_sensor_range u=50}sub(field(all_sensor_temps,max),field(all_sensor_temps,min))
Performance?
One of the first things I wondered about when I started adding the code to Solr to take advantage of the underlying DocValues functionality that makes this all possible is: “How slow is it going to be to find the min/max of each doc at query time going to be?” The answer, surprisingly, is: “Not very slow at all.”
The reason why there isn’t a major performance hit in finding these min/max values at query time comes from the fact that the DocValues implementation sorts the multiple values at index time when writing them to disk. At query time they are accessible via SortedSetDocValues. Finding the “min” is as simple as accessing the first value in the set, while finding the “max” is only slightly harder: one method call to ask for the “count” of values are in the (sorted) set, and then ask for the “last one” (ie: count-1).
The theory was sound, but I wanted to do some quick benchmarking to prove it to myself. So I whipped up a few scripts to generate some test data and run a lot of queries with various sort options and compare the mean response time of different equivalent sorts. The basic idea behind these scripts are:
- Generate 10 million random documents containing a random number of numeric “long” values in a
multi_lfield- Each doc had a 10% chance of having no values at all
- The rest of the docs have at least 1 and at most 13 random values
- Index these documents using a solrconfig.xml that combines CloneFieldUpdateProcessorFactory with MinFieldValueUpdateProcessorFactory and MaxFieldValueUpdateProcessorFactory to ensure that single valued
min_landmax_lfields are also populated accordingly with the correct values. - Generate 500 random range queries against the uniqueKey field, such that there is exactly one query matching each multiple of 200 documents up to 100,000 documents, and such that the order of the queries is fixed but randomized
- For each sort options of interest:
- Start Solr
- Loop over and execute all of the queries using that particular sort option
- Repeat the loop over all of the queries a total of 10 times to try and eliminate noise and find a mean/stddev response time
- Shutdown Solr
- Plot the response time for each set of comparable sort options relative to number of matching documents that were sorted in that request
Before looking at the results, I’d like to remind everyone of a few important caveats:
- I ran these tests on my laptop, while other applications where running and consuming CPU
- There was only the one client providing query load to Solr during the test
- The data in these tests was random and very synthetic, it doesn’t represent any sort of typical distribution
- The queries themselves are very synthetic, and designed to try and minimize the total time Solr spends processing a request other then sorting the various number of results
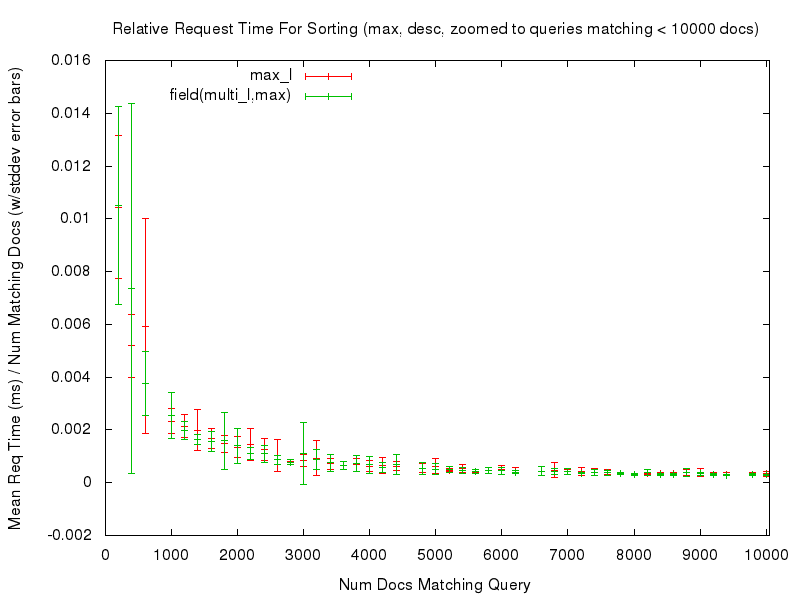
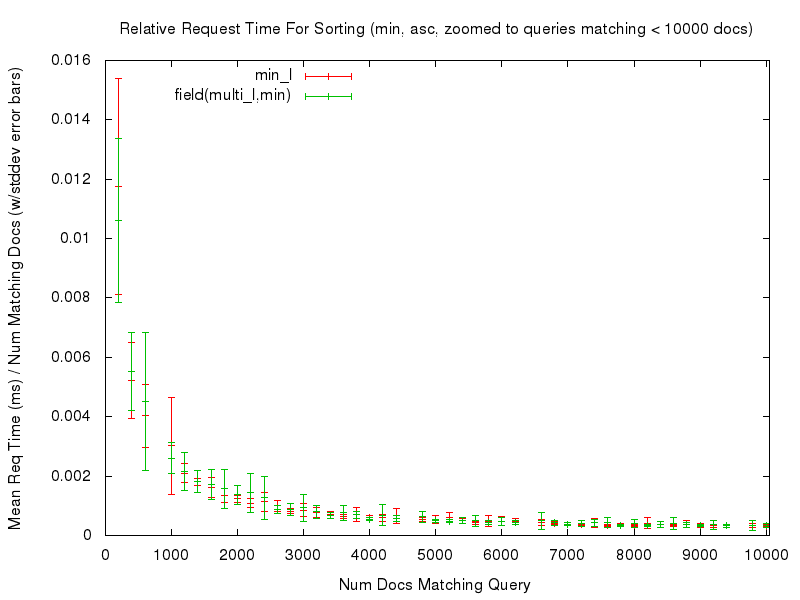
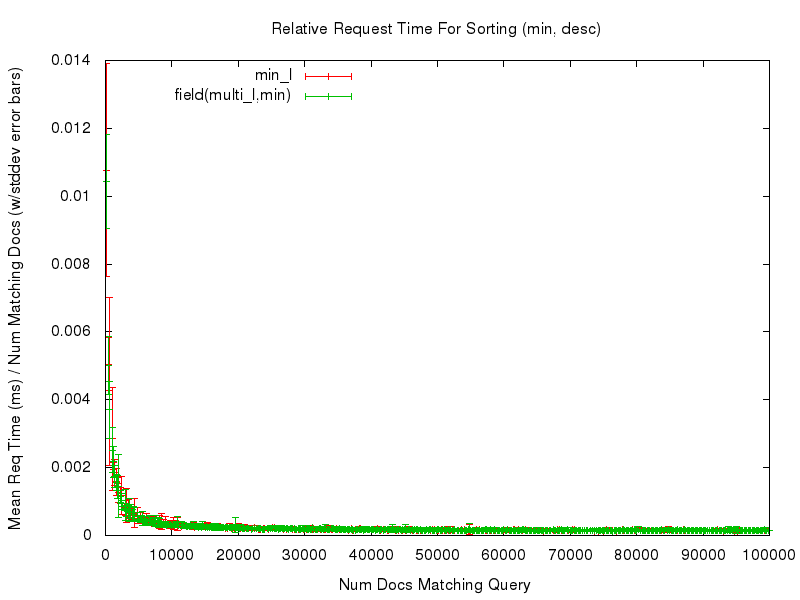
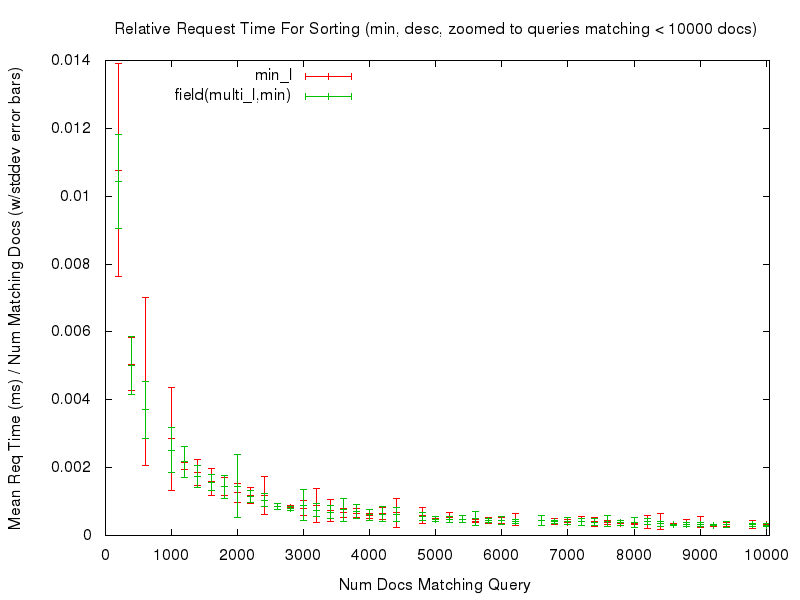
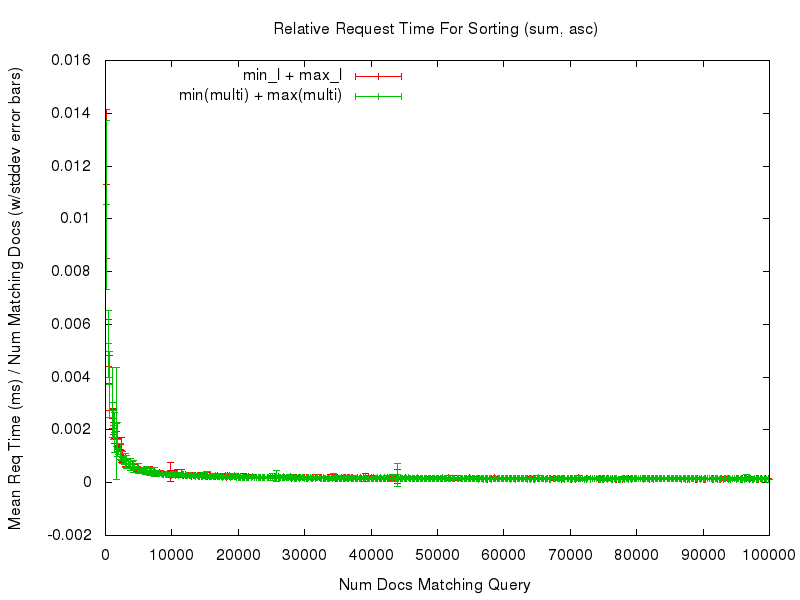
Even with those caveats however, the tests — and the resulting graphs — should still be useful for doing an “apples to apples” comparison of the performance of sorting on a single valued field, vs sorting on the new field(multivaluedfield,minmax) function. For example, let’s start by looking at a comparison of the relative time needed to sort documents using sort=max_l asc vs field(multi_l,max) asc …
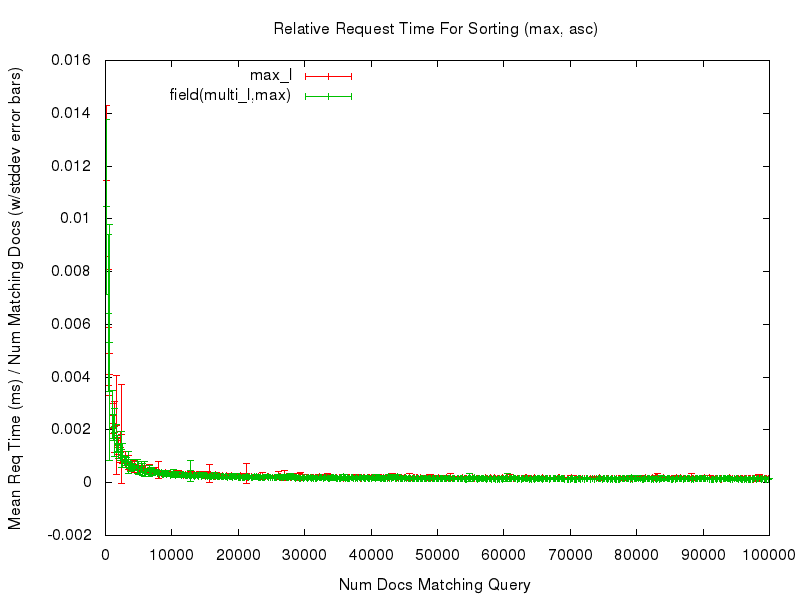
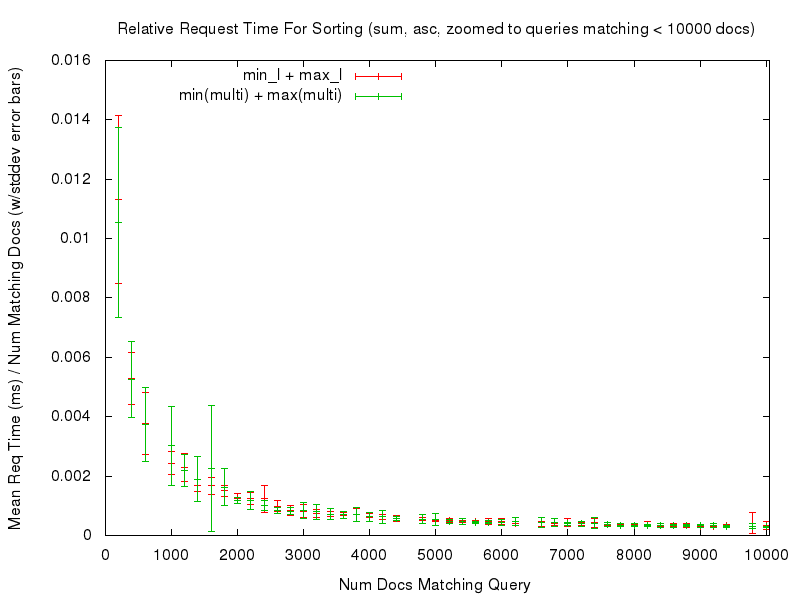
We can see that both sort options had fairly consistent, and fairly flat graphs, of the mean request time relative to the number of documents being sorted. Even if we “zoom in” to only look at the noisy left edge of the graph (requests that match at most 10,000 documents) we see that while the graphs aren’t as flat, they are still fairly consistent in terms of the relative response time…
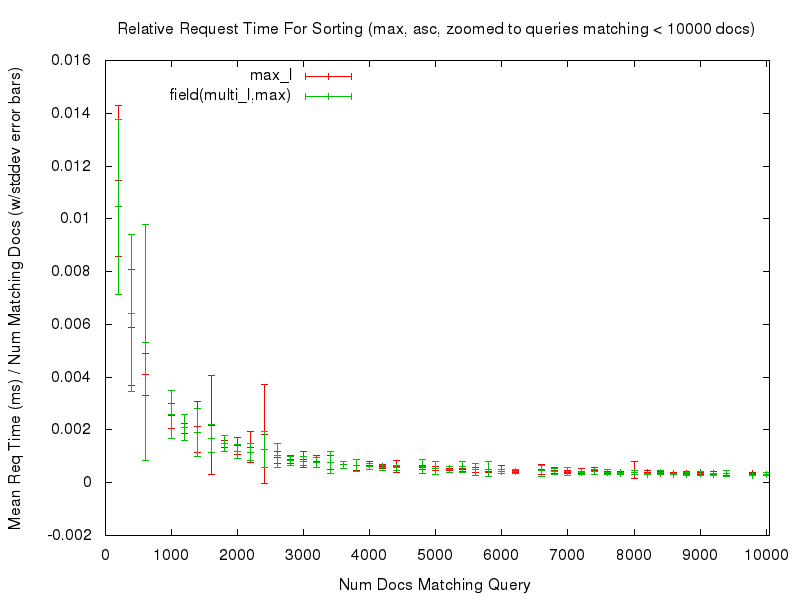
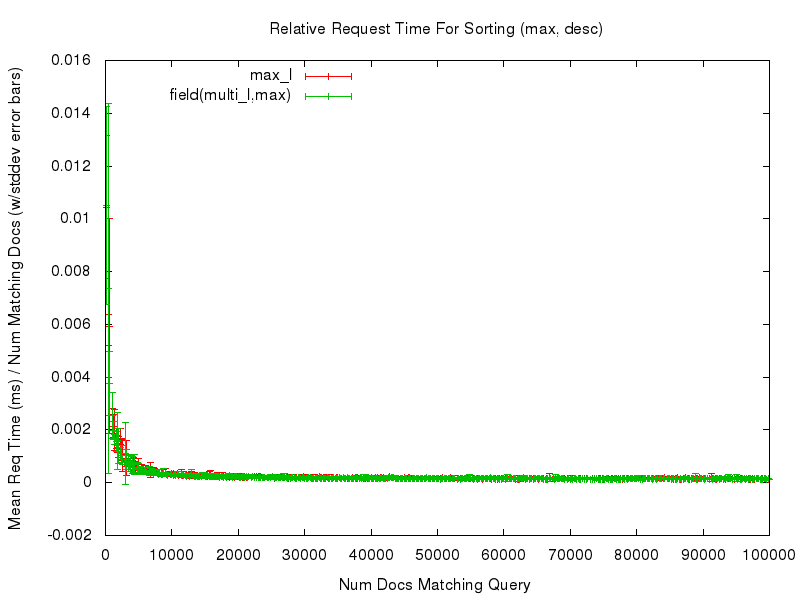
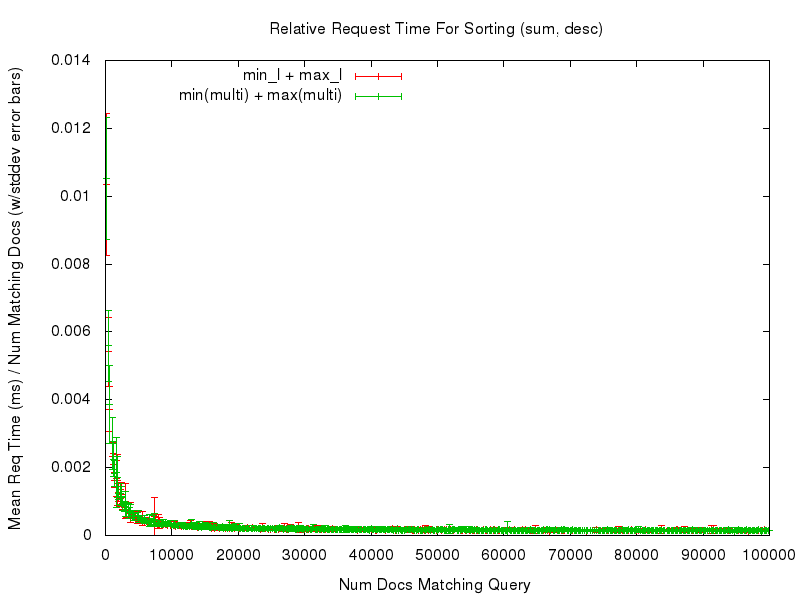
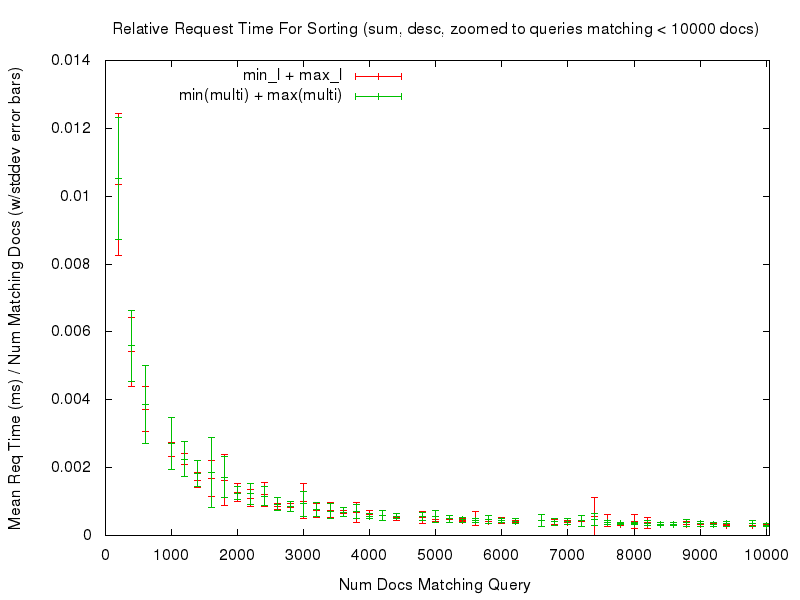
This consistency is (ahem) consistent in all of the comparisons tested — you can use the links in the table below to review any of the graphs you are interested in.
| single sort | multi sort | direction | ||
|---|---|---|---|---|
max_l |
field(multi_l,max) |
asc |
results | zoomed |
max_l |
field(multi_l,max) |
desc |
results | zoomed |
min_l |
field(multi_l,min) |
asc |
results | zoomed |
min_l |
field(multi_l,min) |
desc |
results | zoomed |
sum(min_l,max_l) |
sum(def(field(multi_l,min),0),def(field(multi_l,max),0)) |
asc |
results | zoomed |
sum(min_l,max_l) |
sum(def(field(multi_l,min),0),def(field(multi_l,max),0)) |
desc |
results | zoomed |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.